 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOAD: Discovering Hierarchical Software Engineering Agents via Bandit Optimization
Dec 29, 2025Large language models (LLMs) have shown strong reasoning and coding capabilities, yet they struggle to generalize to real-world software engineering (SWE) problems that are long-horizon and out of distribution. Existing systems often rely on a single agent to handle the entire workflow-interpreting issues, navigating large codebases, and implementing fixes-within one reasoning chain. Such monolithic designs force the model to retain irrelevant context, leading to spurious correlations and poor generalization. Motivated by how human engineers decompose complex problems, we propose structuring SWE agents as orchestrators coordinating specialized sub-agents for sub-tasks such as localization, editing, and validation. The challenge lies in discovering effective hierarchies automatically: as the number of sub-agents grows, the search space becomes combinatorial, and it is difficult to attribute credit to individual sub-agents within a team. We address these challenges by formulating hierarchy discovery as a multi-armed bandit (MAB) problem, where each arm represents a candidate sub-agent and the reward measures its helpfulness when collaborating with others. This framework, termed Bandit Optimization for Agent Design (BOAD), enables efficient exploration of sub-agent designs under limited evaluation budgets. On SWE-bench-Verified, BOAD outperforms single-agent and manually designed multi-agent systems. On SWE-bench-Live, featuring more recent and out-of-distribution issues, our 36B system ranks second on the leaderboard at the time of evaluation, surpassing larger models such as GPT-4 and Claude. These results demonstrate that automatically discovered hierarchical multi-agent systems significantly improve generalization on challenging long-horizon SWE tasks. Code is available at https://github.com/iamxjy/BOAD-SWE-Agent.
Latent Causal Probing: A Formal Perspective on Probing with Causal Models of Data
Jul 18, 2024



As language models (LMs) deliver increasing performance on a range of NLP tasks, probing classifiers have become an indispensable technique in the effort to better understand their inner workings. A typical setup involves (1) defining an auxiliary task consisting of a dataset of text annotated with labels, then (2) supervising small classifiers to predict the labels from the representations of a pretrained LM as it processed the dataset. A high probing accuracy is interpreted as evidence that the LM has learned to perform the auxiliary task as an unsupervised byproduct of its original pretraining objective. Despite the widespread usage of probes, however, the robust design and analysis of probing experiments remains a challenge. We develop a formal perspective on probing using structural causal models (SCM). Specifically, given an SCM which explains the distribution of tokens observed during training, we frame the central hypothesis as whether the LM has learned to represent the latent variables of the SCM. Empirically, we extend a recent study of LMs in the context of a synthetic grid-world navigation task, where having an exact model of the underlying causal structure allows us to draw strong inferences from the result of probing experiments. Our techniques provide robust empirical evidence for the ability of LMs to learn the latent causal concepts underlying text.
Evidence of Meaning in Language Models Trained on Programs
May 24, 2023We present evidence that language models can learn meaning despite being trained only to perform next token prediction on text, specifically a corpus of programs. Each program is preceded by a specification in the form of (textual) input-output examples. Working with programs enables us to precisely define concepts relevant to meaning in language (e.g., correctness and semantics), making program synthesis well-suited as an intermediate testbed for characterizing the presence (or absence) of meaning in language models. We first train a Transformer model on the corpus of programs, then probe the trained model's hidden states as it completes a program given a specification. Despite providing no inductive bias toward learning the semantics of the language, we find that a linear probe is able to extract abstractions of both current and future program states from the model states. Moreover, there is a strong, statistically significant correlation between the accuracy of the probe and the model's ability to generate a program that implements the specification. To evaluate whether the semantics are represented in the model states rather than learned by the probe, we design a novel experimental procedure that intervenes on the semantics of the language while preserving the lexicon and syntax. We also demonstrate that the model learns to generate correct programs that are, on average, shorter than those in the training set, which is evidence that language model outputs may differ from the training distribution in semantically meaningful ways. In summary, this paper does not propose any new techniques for training language models, but develops an experimental framework for and provides insights into the acquisition and representation of (formal) meaning in language models.
$α$NAS: Neural Architecture Search using Property Guided Synthesis
May 08, 2022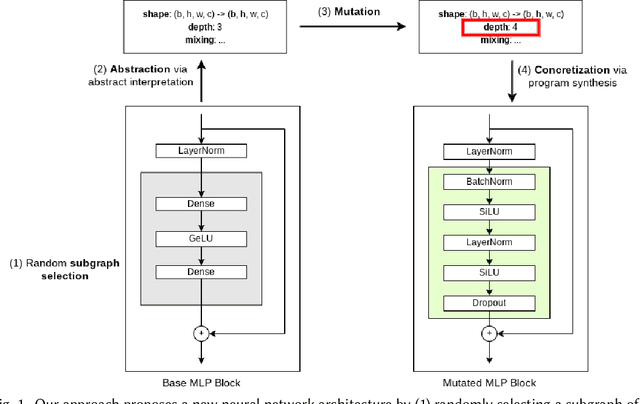

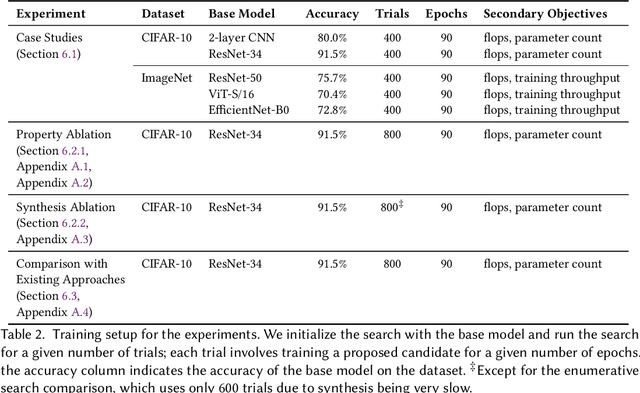
In the past few years, neural architecture search (NAS) has become an increasingly important tool within the deep learning community. Despite the many recent successes of NAS, current approaches still fall far short of the dream of automating an entire neural network architecture design from scratch. Most existing approaches require highly structured design spaces formulated manually by domain experts. In this work, we develop techniques that enable efficient NAS in a significantly larger design space. To accomplish this, we propose to perform NAS in an abstract search space of program properties. Our key insights are as follows: (1) the abstract search space is significantly smaller than the original search space, and (2) architectures with similar program properties also have similar performance; thus, we can search more efficiently in the abstract search space. To enable this approach, we also propose an efficient synthesis procedure, which accepts a set of promising program properties, and returns a satisfying neural architecture. We implement our approach, $\alpha$NAS, within an evolutionary framework, where the mutations are guided by the program properties. Starting with a ResNet-34 model, $\alpha$NAS produces a model with slightly improved accuracy on CIFAR-10 but 96% fewer parameters. On ImageNet, $\alpha$NAS is able to improve over Vision Transformer (30% fewer FLOPS and parameters), ResNet-50 (23% fewer FLOPS, 14% fewer parameters), and EfficientNet (7% fewer FLOPS and parameters) without any degradation in accuracy.
Provable Guarantees against Data Poisoning Using Self-Expansion and Compatibility
May 08, 2021
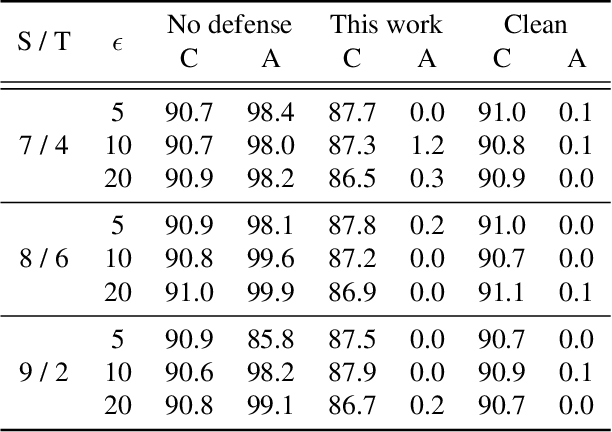

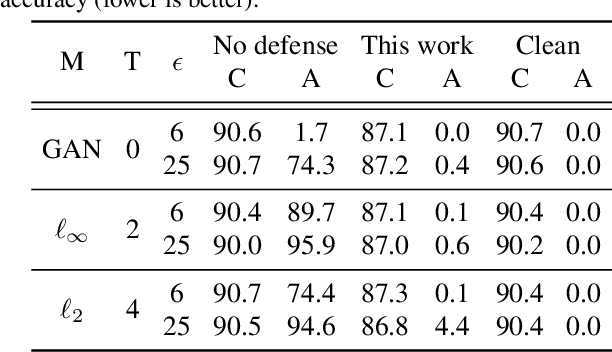
A recent line of work has shown that deep networks are highly susceptible to backdoor data poisoning attacks. Specifically, by injecting a small amount of malicious data into the training distribution, an adversary gains the ability to control the model's behavior during inference. In this work, we propose an iterative training procedure for removing poisoned data from the training set. Our approach consists of two steps. We first train an ensemble of weak learners to automatically discover distinct subpopulations in the training set. We then leverage a boosting framework to recover the clean data. Empirically, our method successfully defends against several state-of-the-art backdoor attacks, including both clean and dirty label attacks. We also present results from an independent third-party evaluation including a recent \textit{adaptive} poisoning adversary. The results indicate our approach is competitive with existing defenses against backdoor attacks on deep neural networks, and significantly outperforms the state-of-the-art in several scenarios.
Learning From Context-Agnostic Synthetic Data
May 29, 2020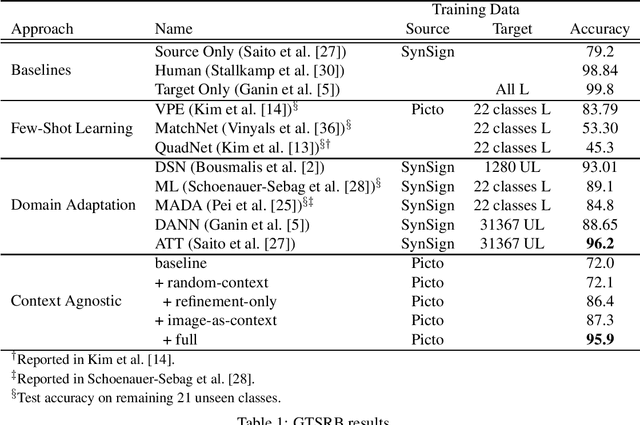
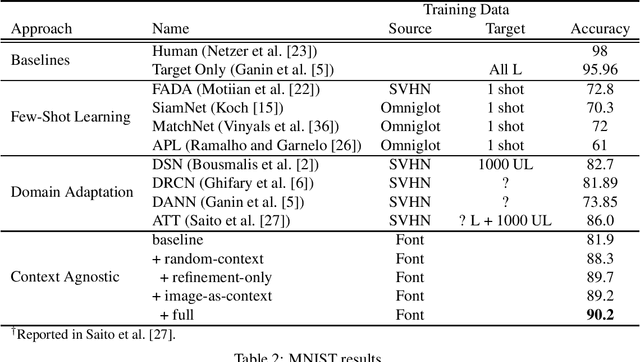
We present a new approach for synthesizing training data given only a single example of each class. Rather than learn over a large but fixed dataset of examples, we generate our entire training set using only the synthetic examples provided. The goal is to learn a classifier that generalizes to a non-synthetic domain without pretraining or fine-tuning on any real world data. We evaluate our approach by training neural networks for two standard benchmarks for real-world image classification: on the GTSRB traffic sign recognition benchmark, we achieve 96% test accuracy using only one clean example of each sign on a blank background; on the MNIST handwritten digit benchmark, we achieve 90% test accuracy using a single example of each digit taken from a computer font. Both these results are competitive with state-of-the-art results from the few-shot learning and domain transfer literature, while using significantly less data.
Manifold Regularization for Adversarial Robustness
Mar 09, 2020

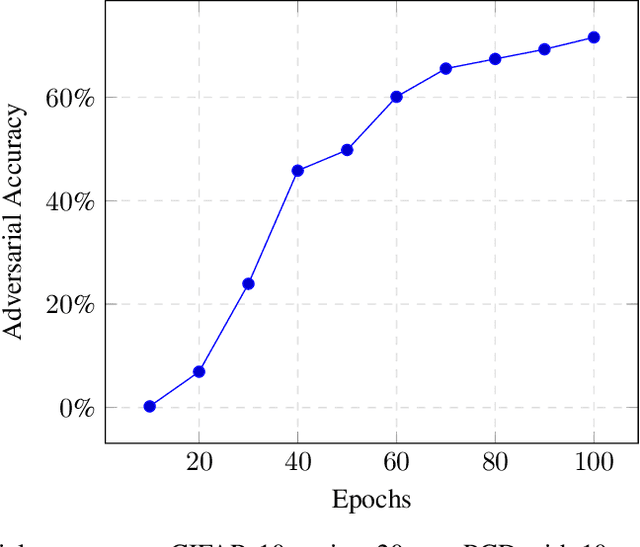
Manifold regularization is a technique that penalizes the complexity of learned functions over the intrinsic geometry of input data. We develop a connection to learning functions which are "locally stable", and propose new regularization terms for training deep neural networks that are stable against a class of local perturbations. These regularizers enable us to train a network to state-of-the-art robust accuracy of 70% on CIFAR-10 against a PGD adversary using $\ell_\infty$ perturbations of size $\epsilon = 8/255$. Furthermore, our techniques do not rely on the construction of any adversarial examples, thus running orders of magnitude faster than standard algorithms for adversarial training.