 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Fleet Efficiency: Analyzing and Optimizing Large-Scale Google TPU Systems with ML Productivity Goodput
Feb 10, 2025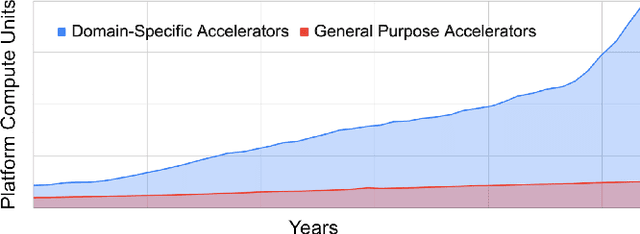

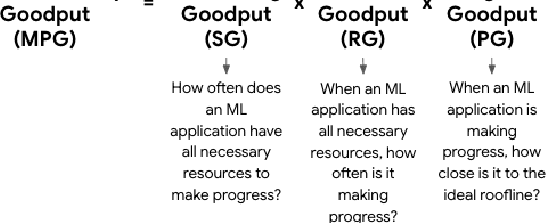

Recent years have seen the emergence of machine learning (ML) workloads deployed in warehouse-scale computing (WSC) settings, also known as ML fleets. As the computational demands placed on ML fleets have increased due to the rise of large models and growing demand for ML applications, it has become increasingly critical to measure and improve the efficiency of such systems. However, there is not yet an established methodology to characterize ML fleet performance and identify potential performance optimizations accordingly. This paper presents a large-scale analysis of an ML fleet based on Google's TPUs, introducing a framework to capture fleet-wide efficiency, systematically evaluate performance characteristics, and identify optimization strategies for the fleet. We begin by defining an ML fleet, outlining its components, and analyzing an example Google ML fleet in production comprising thousands of accelerators running diverse workloads. Our study reveals several critical insights: first, ML fleets extend beyond the hardware layer, with model, data, framework, compiler, and scheduling layers significantly impacting performance; second, the heterogeneous nature of ML fleets poses challenges in characterizing individual workload performance; and third, traditional utilization-based metrics prove insufficient for ML fleet characterization. To address these challenges, we present the "ML Productivity Goodput" (MPG) metric to measure ML fleet efficiency. We show how to leverage this metric to characterize the fleet across the ML system stack. We also present methods to identify and optimize performance bottlenecks using MPG, providing strategies for managing warehouse-scale ML systems in general. Lastly, we demonstrate quantitative evaluations from applying these methods to a real ML fleet for internal-facing Google TPU workloads, where we observed tangible improvements.
Accelerating Retrieval-Augmented Language Model Serving with Speculation
Jan 25, 2024Retrieval-augmented language models (RaLM) have demonstrated the potential to solve knowledge-intensive natural language processing (NLP) tasks by combining a non-parametric knowledge base with a parametric language model. Instead of fine-tuning a fully parametric model, RaLM excels at its low-cost adaptation to the latest data and better source attribution mechanisms. Among various RaLM approaches, iterative RaLM delivers a better generation quality due to a more frequent interaction between the retriever and the language model. Despite the benefits, iterative RaLM usually encounters high overheads due to the frequent retrieval step. To this end, we propose RaLMSpec, a speculation-inspired framework that provides generic speed-up over iterative RaLM while preserving the same model outputs through speculative retrieval and batched verification. By further incorporating prefetching, optimal speculation stride scheduler, and asynchronous verification, RaLMSpec can automatically exploit the acceleration potential to the fullest. For naive iterative RaLM serving, extensive evaluations over three language models on four downstream QA datasets demonstrate that RaLMSpec can achieve a speed-up ratio of 1.75-2.39x, 1.04-1.39x, and 1.31-1.77x when the retriever is an exact dense retriever, approximate dense retriever, and sparse retriever respectively compared with the baseline. For KNN-LM serving, RaLMSpec can achieve a speed-up ratio up to 7.59x and 2.45x when the retriever is an exact dense retriever and approximate dense retriever, respectively, compared with the baseline.
TpuGraphs: A Performance Prediction Dataset on Large Tensor Computational Graphs
Aug 25, 2023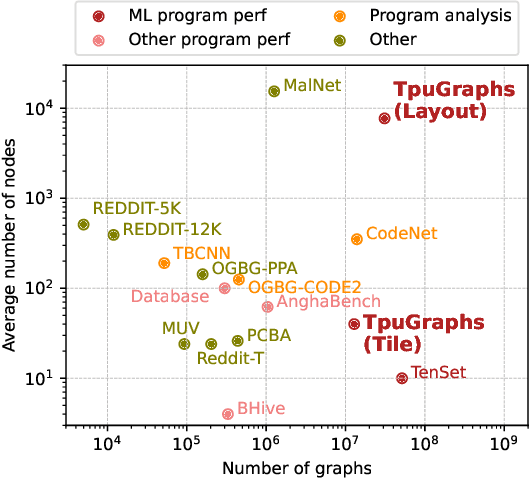

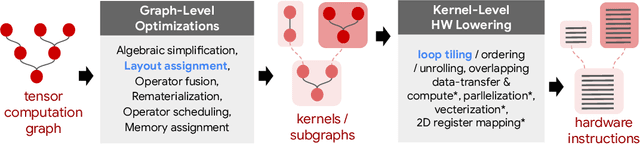
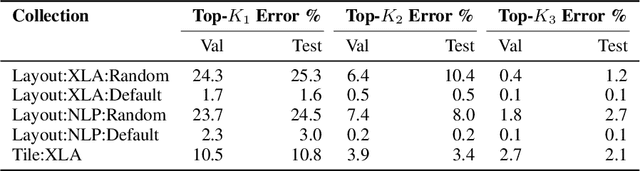
Precise hardware performance models play a crucial role in code optimizations. They can assist compilers in making heuristic decisions or aid autotuners in identifying the optimal configuration for a given program. For example, the autotuner for XLA, a machine learning compiler, discovered 10-20% speedup on state-of-the-art models serving substantial production traffic at Google. Although there exist a few datasets for program performance prediction, they target small sub-programs such as basic blocks or kernels. This paper introduces TpuGraphs, a performance prediction dataset on full tensor programs, represented as computational graphs, running on Tensor Processing Units (TPUs). Each graph in the dataset represents the main computation of a machine learning workload, e.g., a training epoch or an inference step. Each data sample contains a computational graph, a compilation configuration, and the execution time of the graph when compiled with the configuration. The graphs in the dataset are collected from open-source machine learning programs, featuring popular model architectures, e.g., ResNet, EfficientNet, Mask R-CNN, and Transformer. TpuGraphs provides 25x more graphs than the largest graph property prediction dataset (with comparable graph sizes), and 770x larger graphs on average compared to existing performance prediction datasets on machine learning programs. This graph-level prediction task on large graphs introduces new challenges in learning, ranging from scalability, training efficiency, to model quality.
Learning Large Graph Property Prediction via Graph Segment Training
May 21, 2023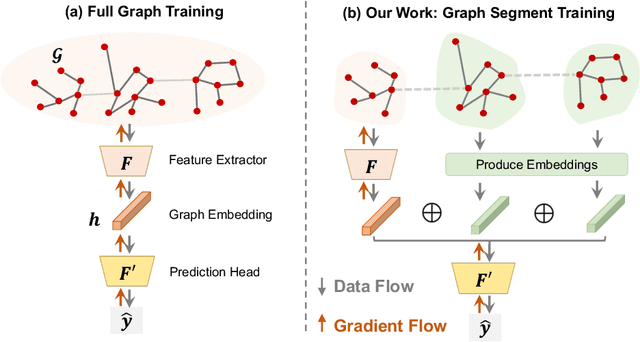
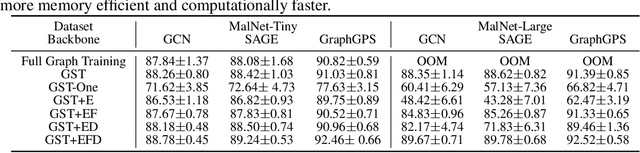

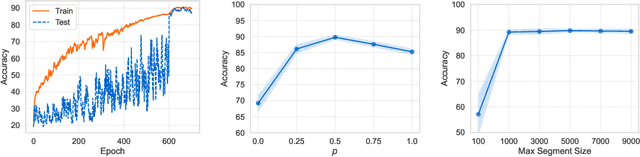
Learning to predict properties of large graphs is challenging because each prediction requires the knowledge of an entire graph, while the amount of memory available during training is bounded. Here we propose Graph Segment Training (GST), a general framework that utilizes a divide-and-conquer approach to allow learning large graph property prediction with a constant memory footprint. GST first divides a large graph into segments and then backpropagates through only a few segments sampled per training iteration. We refine the GST paradigm by introducing a historical embedding table to efficiently obtain embeddings for segments not sampled for backpropagation. To mitigate the staleness of historical embeddings, we design two novel techniques. First, we finetune the prediction head to fix the input distribution shift. Second, we introduce Stale Embedding Dropout to drop some stale embeddings during training to reduce bias. We evaluate our complete method GST-EFD (with all the techniques together) on two large graph property prediction benchmarks: MalNet and TpuGraphs. Our experiments show that GST-EFD is both memory-efficient and fast, while offering a slight boost on test accuracy over a typical full graph training regime.
Optimizing Memory Mapping Using Deep Reinforcement Learning
May 11, 2023



Resource scheduling and allocation is a critical component of many high impact systems ranging from congestion control to cloud computing. Finding more optimal solutions to these problems often has significant impact on resource and time savings, reducing device wear-and-tear, and even potentially improving carbon emissions. In this paper, we focus on a specific instance of a scheduling problem, namely the memory mapping problem that occurs during compilation of machine learning programs: That is, mapping tensors to different memory layers to optimize execution time. We introduce an approach for solving the memory mapping problem using Reinforcement Learning. RL is a solution paradigm well-suited for sequential decision making problems that are amenable to planning, and combinatorial search spaces with high-dimensional data inputs. We formulate the problem as a single-player game, which we call the mallocGame, such that high-reward trajectories of the game correspond to efficient memory mappings on the target hardware. We also introduce a Reinforcement Learning agent, mallocMuZero, and show that it is capable of playing this game to discover new and improved memory mapping solutions that lead to faster execution times on real ML workloads on ML accelerators. We compare the performance of mallocMuZero to the default solver used by the Accelerated Linear Algebra (XLA) compiler on a benchmark of realistic ML workloads. In addition, we show that mallocMuZero is capable of improving the execution time of the recently published AlphaTensor matrix multiplication model.
GRANITE: A Graph Neural Network Model for Basic Block Throughput Estimation
Oct 11, 2022
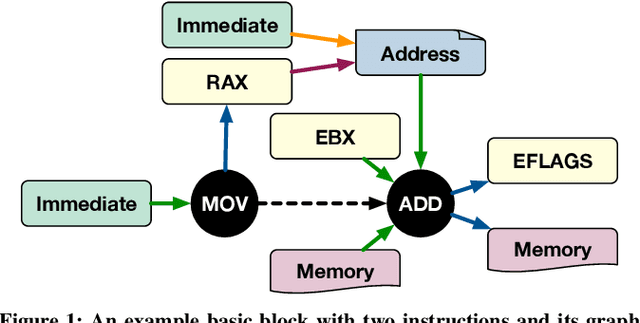
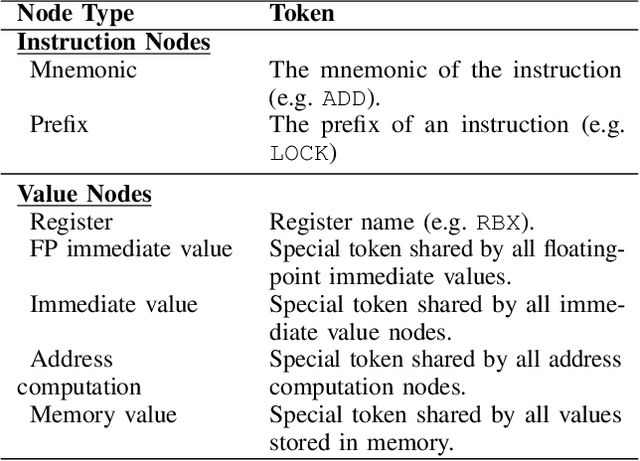
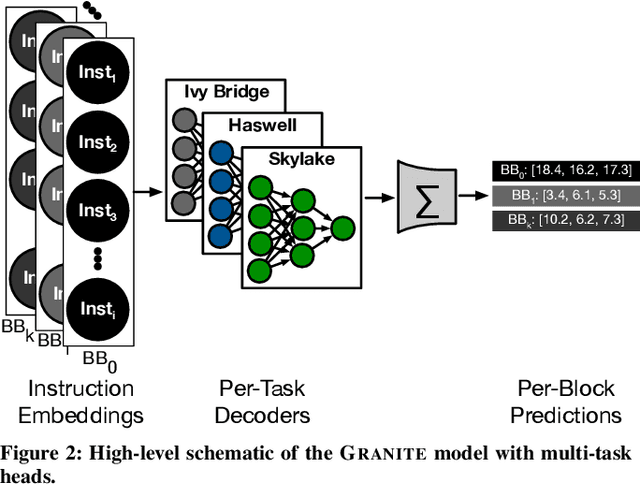
Analytical hardware performance models yield swift estimation of desired hardware performance metrics. However, developing these analytical models for modern processors with sophisticated microarchitectures is an extremely laborious task and requires a firm understanding of target microarchitecture's internal structure. In this paper, we introduce GRANITE, a new machine learning model that estimates the throughput of basic blocks across different microarchitectures. GRANITE uses a graph representation of basic blocks that captures both structural and data dependencies between instructions. This representation is processed using a graph neural network that takes advantage of the relational information captured in the graph and learns a rich neural representation of the basic block that allows more precise throughput estimation. Our results establish a new state-of-the-art for basic block performance estimation with an average test error of 6.9% across a wide range of basic blocks and microarchitectures for the x86-64 target. Compared to recent work, this reduced the error by 1.7% while improving training and inference throughput by approximately 3.0x. In addition, we propose the use of multi-task learning with independent multi-layer feed forward decoder networks. Our results show that this technique further improves precision of all learned models while significantly reducing per-microarchitecture training costs. We perform an extensive set of ablation studies and comparisons with prior work, concluding a set of methods to achieve high accuracy for basic block performance estimation.
$α$NAS: Neural Architecture Search using Property Guided Synthesis
May 08, 2022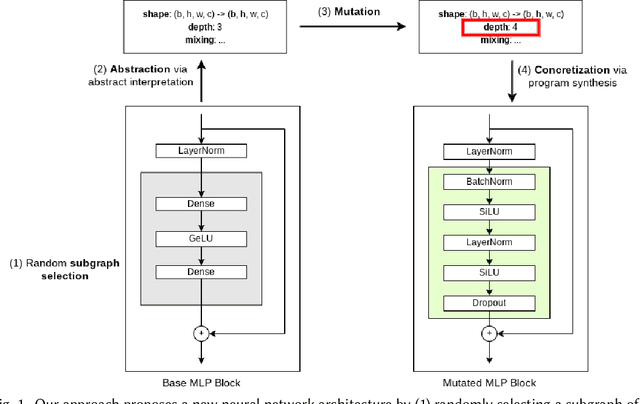

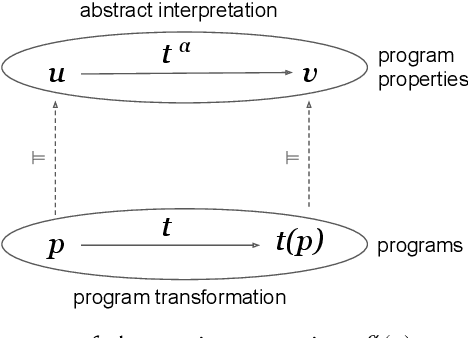
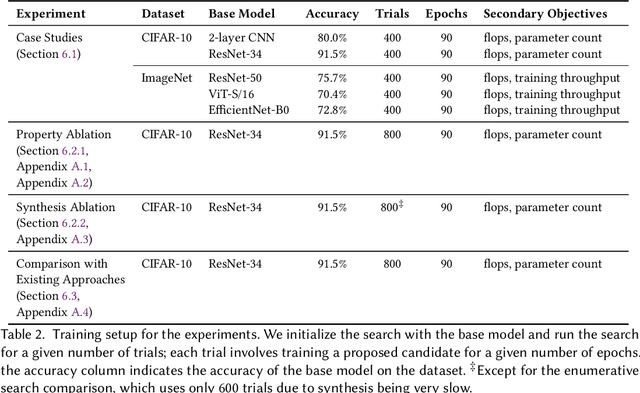
In the past few years, neural architecture search (NAS) has become an increasingly important tool within the deep learning community. Despite the many recent successes of NAS, current approaches still fall far short of the dream of automating an entire neural network architecture design from scratch. Most existing approaches require highly structured design spaces formulated manually by domain experts. In this work, we develop techniques that enable efficient NAS in a significantly larger design space. To accomplish this, we propose to perform NAS in an abstract search space of program properties. Our key insights are as follows: (1) the abstract search space is significantly smaller than the original search space, and (2) architectures with similar program properties also have similar performance; thus, we can search more efficiently in the abstract search space. To enable this approach, we also propose an efficient synthesis procedure, which accepts a set of promising program properties, and returns a satisfying neural architecture. We implement our approach, $\alpha$NAS, within an evolutionary framework, where the mutations are guided by the program properties. Starting with a ResNet-34 model, $\alpha$NAS produces a model with slightly improved accuracy on CIFAR-10 but 96% fewer parameters. On ImageNet, $\alpha$NAS is able to improve over Vision Transformer (30% fewer FLOPS and parameters), ResNet-50 (23% fewer FLOPS, 14% fewer parameters), and EfficientNet (7% fewer FLOPS and parameters) without any degradation in accuracy.
A Transferable Approach for Partitioning Machine Learning Models on Multi-Chip-Modules
Dec 07, 2021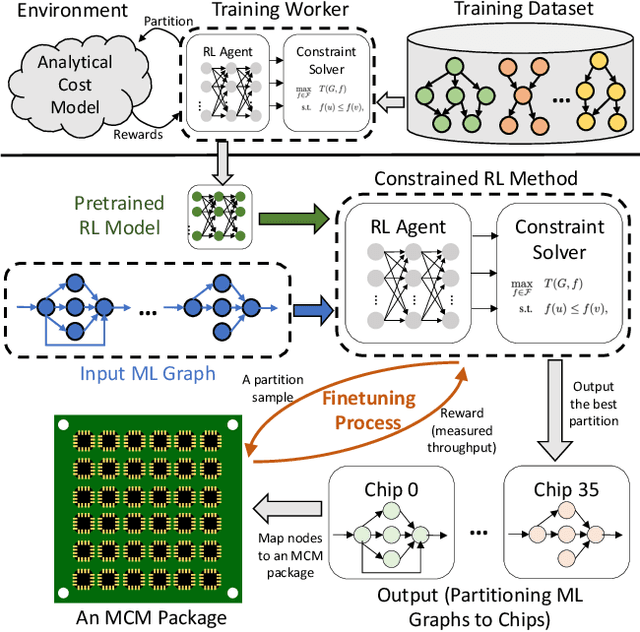
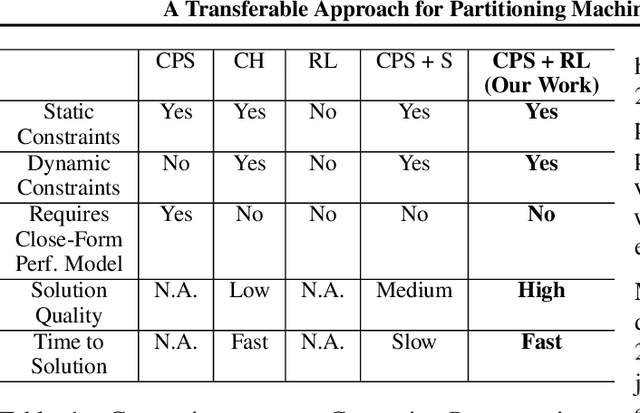
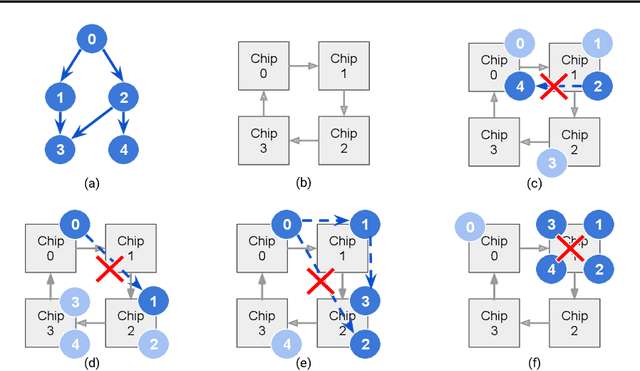

Multi-Chip-Modules (MCMs) reduce the design and fabrication cost of machine learning (ML) accelerators while delivering performance and energy efficiency on par with a monolithic large chip. However, ML compilers targeting MCMs need to solve complex optimization problems optimally and efficiently to achieve this high performance. One such problem is the multi-chip partitioning problem where compilers determine the optimal partitioning and placement of operations in tensor computation graphs on chiplets in MCMs. Partitioning ML graphs for MCMs is particularly hard as the search space grows exponentially with the number of chiplets available and the number of nodes in the neural network. Furthermore, the constraints imposed by the underlying hardware produce a search space where valid solutions are extremely sparse. In this paper, we present a strategy using a deep reinforcement learning (RL) framework to emit a possibly invalid candidate partition that is then corrected by a constraint solver. Using the constraint solver ensures that RL encounters valid solutions in the sparse space frequently enough to converge with fewer samples as compared to non-learned strategies. The architectural choices we make for the policy network allow us to generalize across different ML graphs. Our evaluation of a production-scale model, BERT, on real hardware reveals that the partitioning generated using RL policy achieves 6.11% and 5.85% higher throughput than random search and simulated annealing. In addition, fine-tuning the pre-trained RL policy reduces the search time from 3 hours to only 9 minutes, while achieving the same throughput as training RL policy from scratch.
A Learned Performance Model for the Tensor Processing Unit
Aug 03, 2020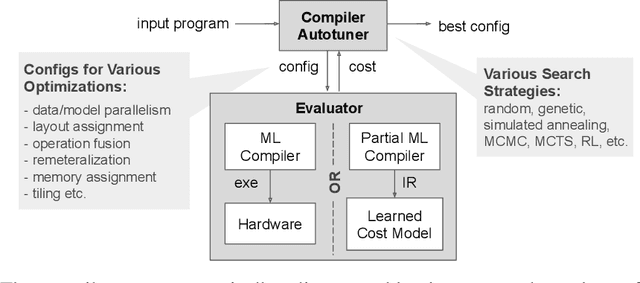
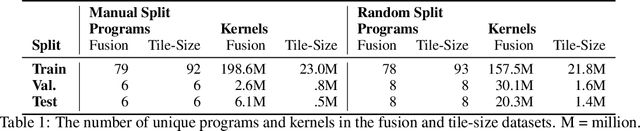
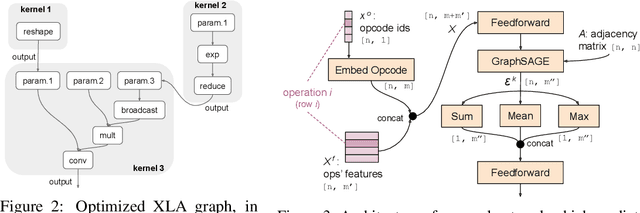
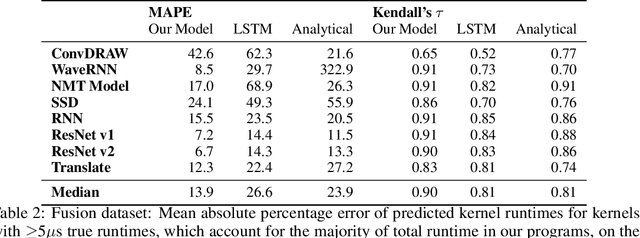
Accurate hardware performance models are critical to efficient code generation. They can be used by compilers to make heuristic decisions, by superoptimizers as an minimization objective, or by autotuners to find an optimal configuration of a specific program. However, they are difficult to develop because contemporary processors are complex, and the recent proliferation of deep learning accelerators has increased the development burden. We demonstrate a method of learning performance models from a corpus of tensor computation graph programs for the Tensor Processing Unit (TPU). We train a neural network over kernel-level sub-graphs from the corpus and find that the learned model is competitive to a heavily-optimized analytical cost model used in the production XLA compiler.