 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Context Parallelism for Scalable Million-Token Inference
Nov 04, 2024



We present context parallelism for long-context large language model inference, which achieves near-linear scaling for long-context prefill latency with up to 128 H100 GPUs across 16 nodes. Particularly, our method achieves 1M context prefill with Llama3 405B model in 77s (93% parallelization efficiency, 63% FLOPS utilization) and 128K context prefill in 3.8s. We develop two lossless exact ring attention variants: pass-KV and pass-Q to cover a wide range of use cases with the state-of-the-art performance: full prefill, persistent KV prefill and decode. Benchmarks on H100 GPU hosts inter-connected with RDMA and TCP both show similar scalability for long-context prefill, demonstrating that our method scales well using common commercial data center with medium-to-low inter-host bandwidth.
Hierarchical Structured Neural Network for Retrieval
Aug 13, 2024



Embedding Based Retrieval (EBR) is a crucial component of the retrieval stage in (Ads) Recommendation System that utilizes Two Tower or Siamese Networks to learn embeddings for both users and items (ads). It then employs an Approximate Nearest Neighbor Search (ANN) to efficiently retrieve the most relevant ads for a specific user. Despite the recent rise to popularity in the industry, they have a couple of limitations. Firstly, Two Tower model architecture uses a single dot product interaction which despite their efficiency fail to capture the data distribution in practice. Secondly, the centroid representation and cluster assignment, which are components of ANN, occur after the training process has been completed. As a result, they do not take into account the optimization criteria used for retrieval model. In this paper, we present Hierarchical Structured Neural Network (HSNN), a deployed jointly optimized hierarchical clustering and neural network model that can take advantage of sophisticated interactions and model architectures that are more common in the ranking stages while maintaining a sub-linear inference cost. We achieve 6.5% improvement in offline evaluation and also demonstrate 1.22% online gains through A/B experiments. HSNN has been successfully deployed into the Ads Recommendation system and is currently handling major portion of the traffic. The paper shares our experience in developing this system, dealing with challenges like freshness, volatility, cold start recommendations, cluster collapse and lessons deploying the model in a large scale retrieval production system.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
CoMERA: Computing- and Memory-Efficient Training via Rank-Adaptive Tensor Optimization
May 23, 2024



Training large AI models such as deep learning recommendation systems and foundation language (or multi-modal) models costs massive GPUs and computing time. The high training cost has become only affordable to big tech companies, meanwhile also causing increasing concerns about the environmental impact. This paper presents CoMERA, a Computing- and Memory-Efficient training method via Rank-Adaptive tensor optimization. CoMERA achieves end-to-end rank-adaptive tensor-compressed training via a multi-objective optimization formulation, and improves the training to provide both a high compression ratio and excellent accuracy in the training process. Our optimized numerical computation (e.g., optimized tensorized embedding and tensor-vector contractions) and GPU implementation eliminate part of the run-time overhead in the tensorized training on GPU. This leads to, for the first time, $2-3\times$ speedup per training epoch compared with standard training. CoMERA also outperforms the recent GaLore in terms of both memory and computing efficiency. Specifically, CoMERA is $2\times$ faster per training epoch and $9\times$ more memory-efficient than GaLore on a tested six-encoder transformer with single-batch training. With further HPC optimization, CoMERA may significantly reduce the training cost of large language models.
A Transferable Approach for Partitioning Machine Learning Models on Multi-Chip-Modules
Dec 07, 2021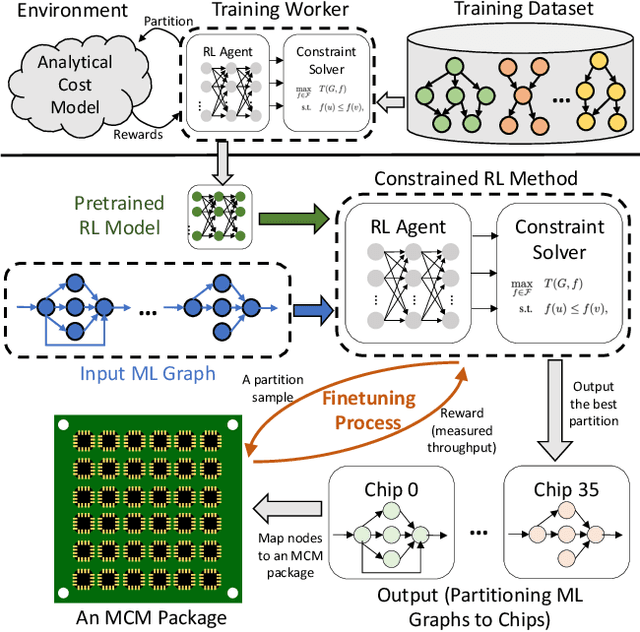
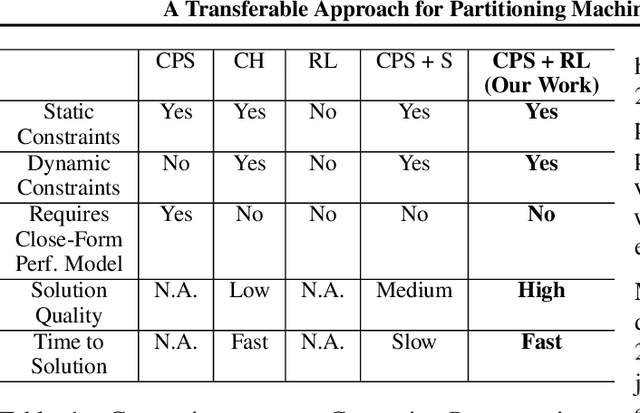
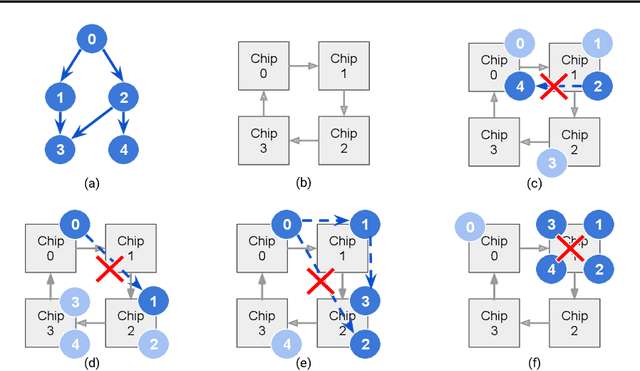

Multi-Chip-Modules (MCMs) reduce the design and fabrication cost of machine learning (ML) accelerators while delivering performance and energy efficiency on par with a monolithic large chip. However, ML compilers targeting MCMs need to solve complex optimization problems optimally and efficiently to achieve this high performance. One such problem is the multi-chip partitioning problem where compilers determine the optimal partitioning and placement of operations in tensor computation graphs on chiplets in MCMs. Partitioning ML graphs for MCMs is particularly hard as the search space grows exponentially with the number of chiplets available and the number of nodes in the neural network. Furthermore, the constraints imposed by the underlying hardware produce a search space where valid solutions are extremely sparse. In this paper, we present a strategy using a deep reinforcement learning (RL) framework to emit a possibly invalid candidate partition that is then corrected by a constraint solver. Using the constraint solver ensures that RL encounters valid solutions in the sparse space frequently enough to converge with fewer samples as compared to non-learned strategies. The architectural choices we make for the policy network allow us to generalize across different ML graphs. Our evaluation of a production-scale model, BERT, on real hardware reveals that the partitioning generated using RL policy achieves 6.11% and 5.85% higher throughput than random search and simulated annealing. In addition, fine-tuning the pre-trained RL policy reduces the search time from 3 hours to only 9 minutes, while achieving the same throughput as training RL policy from scratch.
FPSA: A Full System Stack Solution for Reconfigurable ReRAM-based NN Accelerator Architecture
Jan 28, 2019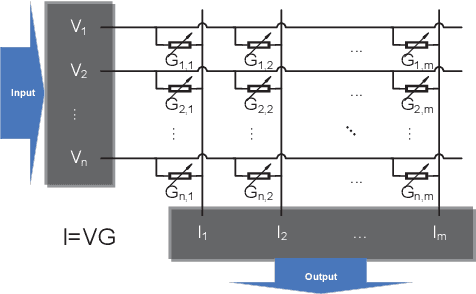
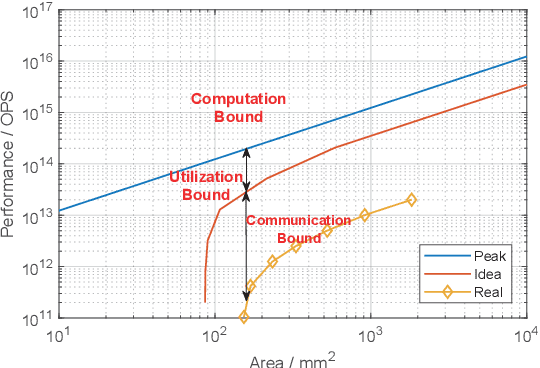
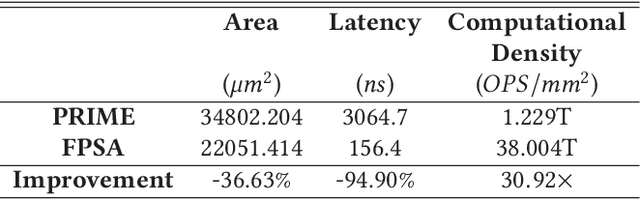
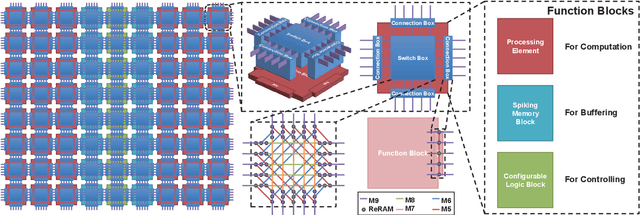
Neural Network (NN) accelerators with emerging ReRAM (resistive random access memory) technologies have been investigated as one of the promising solutions to address the \textit{memory wall} challenge, due to the unique capability of \textit{processing-in-memory} within ReRAM-crossbar-based processing elements (PEs). However, the high efficiency and high density advantages of ReRAM have not been fully utilized due to the huge communication demands among PEs and the overhead of peripheral circuits. In this paper, we propose a full system stack solution, composed of a reconfigurable architecture design, Field Programmable Synapse Array (FPSA) and its software system including neural synthesizer, temporal-to-spatial mapper, and placement & routing. We highly leverage the software system to make the hardware design compact and efficient. To satisfy the high-performance communication demand, we optimize it with a reconfigurable routing architecture and the placement & routing tool. To improve the computational density, we greatly simplify the PE circuit with the spiking schema and then adopt neural synthesizer to enable the high density computation-resources to support different kinds of NN operations. In addition, we provide spiking memory blocks (SMBs) and configurable logic blocks (CLBs) in hardware and leverage the temporal-to-spatial mapper to utilize them to balance the storage and computation requirements of NN. Owing to the end-to-end software system, we can efficiently deploy existing deep neural networks to FPSA. Evaluations show that, compared to one of state-of-the-art ReRAM-based NN accelerators, PRIME, the computational density of FPSA improves by 31x; for representative NNs, its inference performance can achieve up to 1000x speedup.
QGAN: Quantized Generative Adversarial Networks
Jan 24, 2019
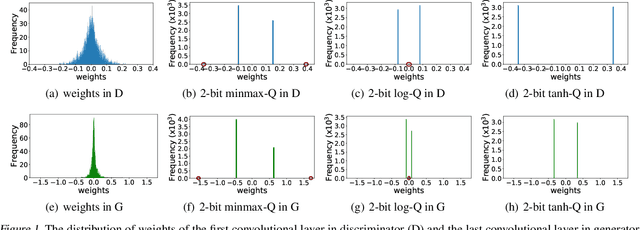
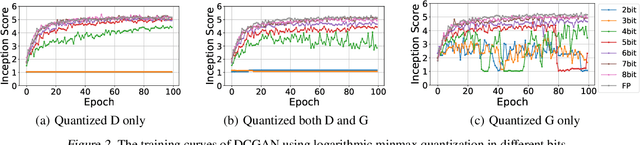
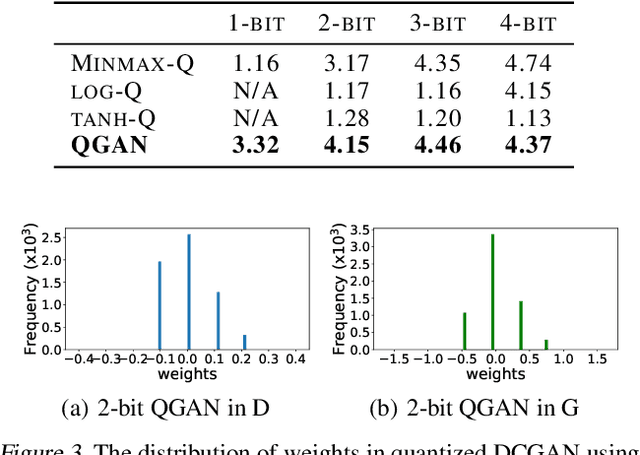
The intensive computation and memory requirements of generative adversarial neural networks (GANs) hinder its real-world deployment on edge devices such as smartphones. Despite the success in model reduction of CNNs, neural network quantization methods have not yet been studied on GANs, which are mainly faced with the issues of both the effectiveness of quantization algorithms and the instability of training GAN models. In this paper, we start with an extensive study on applying existing successful methods to quantize GANs. Our observation reveals that none of them generates samples with reasonable quality because of the underrepresentation of quantized values in model weights, and the generator and discriminator networks show different sensitivities upon quantization methods. Motivated by these observations, we develop a novel quantization method for GANs based on EM algorithms, named as QGAN. We also propose a multi-precision algorithm to help find the optimal number of bits of quantized GAN models in conjunction with corresponding result qualities. Experiments on CIFAR-10 and CelebA show that QGAN can quantize GANs to even 1-bit or 2-bit representations with results of quality comparable to original models.