 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPLOYO: A Pulmonary Nodule Detection Model with Multi-Scale Feature Fusion and Nonlinear Feature Learning
Mar 13, 2025

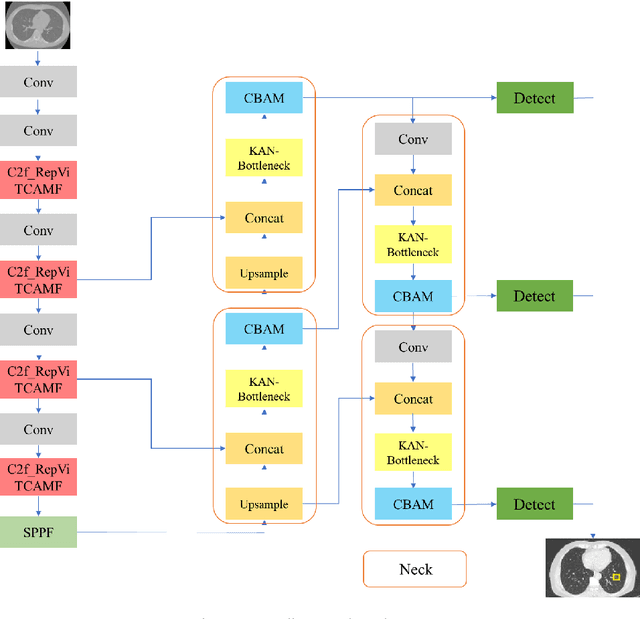

The integration of Internet of Things (IoT) technology in pulmonary nodule detection significantly enhances the intelligence and real-time capabilities of the detection system. Currently, lung nodule detection primarily focuses on the identification of solid nodules, but different types of lung nodules correspond to various forms of lung cancer. Multi-type detection contributes to improving the overall lung cancer detection rate and enhancing the cure rate. To achieve high sensitivity in nodule detection, targeted improvements were made to the YOLOv8 model. Firstly, the C2f\_RepViTCAMF module was introduced to augment the C2f module in the backbone, thereby enhancing detection accuracy for small lung nodules and achieving a lightweight model design. Secondly, the MSCAF module was incorporated to reconstruct the feature fusion section of the model, improving detection accuracy for lung nodules of varying scales. Furthermore, the KAN network was integrated into the model. By leveraging the KAN network's powerful nonlinear feature learning capability, detection accuracy for small lung nodules was further improved, and the model's generalization ability was enhanced. Tests conducted on the LUNA16 dataset demonstrate that the improved model outperforms the original model as well as other mainstream models such as YOLOv9 and RT-DETR across various evaluation metrics.
Multi-View Oriented GPLVM: Expressiveness and Efficiency
Feb 12, 2025



The multi-view Gaussian process latent variable model (MV-GPLVM) aims to learn a unified representation from multi-view data but is hindered by challenges such as limited kernel expressiveness and low computational efficiency. To overcome these issues, we first introduce a new duality between the spectral density and the kernel function. By modeling the spectral density with a bivariate Gaussian mixture, we then derive a generic and expressive kernel termed Next-Gen Spectral Mixture (NG-SM) for MV-GPLVMs. To address the inherent computational inefficiency of the NG-SM kernel, we propose a random Fourier feature approximation. Combined with a tailored reparameterization trick, this approximation enables scalable variational inference for both the model and the unified latent representations. Numerical evaluations across a diverse range of multi-view datasets demonstrate that our proposed method consistently outperforms state-of-the-art models in learning meaningful latent representations.
CLoQ: Enhancing Fine-Tuning of Quantized LLMs via Calibrated LoRA Initialization
Jan 30, 2025



Fine-tuning large language models (LLMs) using low-rank adaptation (LoRA) has become a highly efficient approach for downstream tasks, particularly in scenarios with limited computational resources. However, applying LoRA techniques to quantized LLMs poses unique challenges due to the reduced representational precision of quantized weights. In this paper, we introduce CLoQ (Calibrated LoRA initialization for Quantized LLMs), a simplistic initialization strategy designed to overcome these challenges. Our approach focuses on minimizing the layer-wise discrepancy between the original LLM and its quantized counterpart with LoRA components during initialization. By leveraging a small calibration dataset, CLoQ quantizes a pre-trained LLM and determines the optimal LoRA components for each layer, ensuring a strong foundation for subsequent fine-tuning. A key contribution of this work is a novel theoretical result that enables the accurate and closed-form construction of these optimal LoRA components. We validate the efficacy of CLoQ across multiple tasks such as language generation, arithmetic reasoning, and commonsense reasoning, demonstrating that it consistently outperforms existing LoRA fine-tuning methods for quantized LLMs, especially at ultra low-bit widths.
RFPPO: Motion Dynamic RRT based Fluid Field - PPO for Dynamic TF/TA Routing Planning
Dec 28, 2024



Existing local dynamic route planning algorithms, when directly applied to terrain following/terrain avoidance, or dynamic obstacle avoidance for large and medium-sized fixed-wing aircraft, fail to simultaneously meet the requirements of real-time performance, long-distance planning, and the dynamic constraints of large and medium-sized aircraft. To deal with this issue, this paper proposes the Motion Dynamic RRT based Fluid Field - PPO for dynamic TF/TA routing planning. Firstly, the action and state spaces of the proximal policy gradient algorithm are redesigned using disturbance flow fields and artificial potential field algorithms, establishing an aircraft dynamics model, and designing a state transition process based on this model. Additionally, a reward function is designed to encourage strategies for obstacle avoidance, terrain following, terrain avoidance, and safe flight. Experimental results on real DEM data demonstrate that our algorithm can complete long-distance flight tasks through collision-free trajectory planning that complies with dynamic constraints, without the need for prior global planning.
Data Pruning Can Do More: A Comprehensive Data Pruning Approach for Object Re-identification
Dec 13, 2024



Previous studies have demonstrated that not each sample in a dataset is of equal importance during training. Data pruning aims to remove less important or informative samples while still achieving comparable results as training on the original (untruncated) dataset, thereby reducing storage and training costs. However, the majority of data pruning methods are applied to image classification tasks. To our knowledge, this work is the first to explore the feasibility of these pruning methods applied to object re-identification (ReID) tasks, while also presenting a more comprehensive data pruning approach. By fully leveraging the logit history during training, our approach offers a more accurate and comprehensive metric for quantifying sample importance, as well as correcting mislabeled samples and recognizing outliers. Furthermore, our approach is highly efficient, reducing the cost of importance score estimation by 10 times compared to existing methods. Our approach is a plug-and-play, architecture-agnostic framework that can eliminate/reduce 35%, 30%, and 5% of samples/training time on the VeRi, MSMT17 and Market1501 datasets, respectively, with negligible loss in accuracy (< 0.1%). The lists of important, mislabeled, and outlier samples from these ReID datasets are available at https://github.com/Zi-Y/data-pruning-reid.
Retrieval Or Holistic Understanding? Dolce: Differentiate Our Long Context Evaluation Tasks
Sep 10, 2024



We argue that there are two major distinct capabilities in long context understanding: retrieval and holistic understanding. Understanding and further improving LLMs' long context capabilities would not be possible without knowing the tasks' focus categories. We aim to automatically identify retrieval focused and holistic understanding focused problems from suites of benchmarks and quantitatively measure the difficulty within each focus. In this paper, we present the Dolce framework, which parameterizes each problem by $\lambda$ (complexity) and $k$ (redundancy) and assigns to one of five predefined focus categories. We propose to sample short contexts from the full context and estimate the probability an LLM solves the problem using the sampled spans. To find the $\lambda$ and $k$ for each problem, we further propose a mixture model of a non-parametric background noise component and a parametric/non-parametric hybrid oracle component, where we derive the probability functions parameterized by $\lambda$ and $k$ for both the correct-or-wrong (COW) scenario and the partial-point-in-grading (PIG) scenario. Our proposed methods can identify 0% to 67% of the problems are retrieval focused and 0% to 90% of the problems are holistic understanding focused across 44 existing long context evaluation tasks.
MagR: Weight Magnitude Reduction for Enhancing Post-Training Quantization
Jun 02, 2024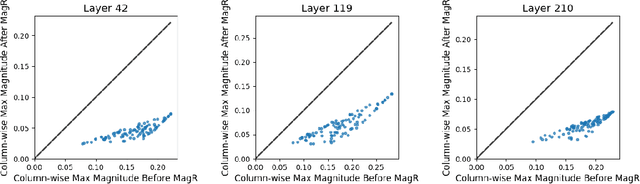
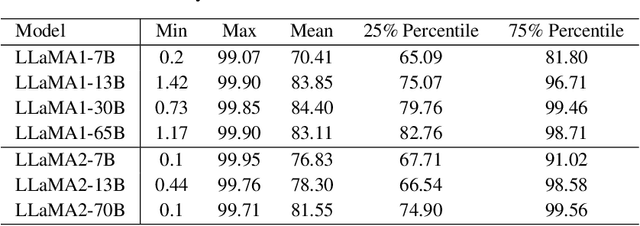
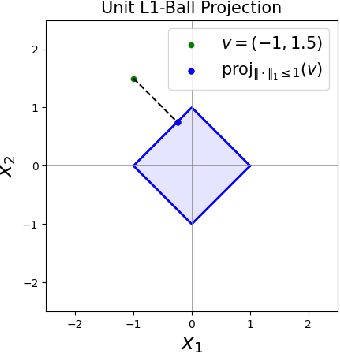
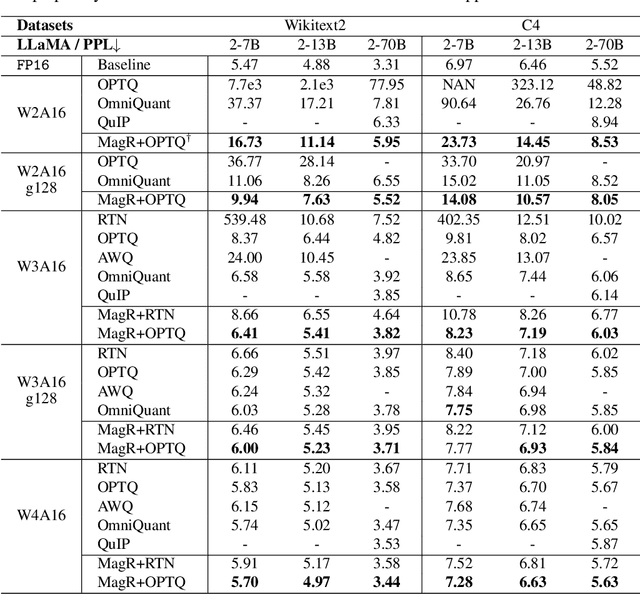
In this paper, we present a simple optimization-based preprocessing technique called Weight Magnitude Reduction (MagR) to improve the performance of post-training quantization. For each linear layer, we adjust the pre-trained floating-point weights by solving an $\ell_\infty$-regularized optimization problem. This process greatly diminishes the maximum magnitude of the weights and smooths out outliers, while preserving the layer's output. The preprocessed weights are centered more towards zero, which facilitates the subsequent quantization process. To implement MagR, we address the $\ell_\infty$-regularization by employing an efficient proximal gradient descent algorithm. Unlike existing preprocessing methods that involve linear transformations and subsequent post-processing steps, which can introduce significant overhead at inference time, MagR functions as a non-linear transformation, eliminating the need for any additional post-processing. This ensures that MagR introduces no overhead whatsoever during inference. Our experiments demonstrate that MagR achieves state-of-the-art performance on the Llama family of models. For example, we achieve a Wikitext2 perplexity of 5.95 on the LLaMA2-70B model for per-channel INT2 weight quantization without incurring any inference overhead.
CoMERA: Computing- and Memory-Efficient Training via Rank-Adaptive Tensor Optimization
May 23, 2024



Training large AI models such as deep learning recommendation systems and foundation language (or multi-modal) models costs massive GPUs and computing time. The high training cost has become only affordable to big tech companies, meanwhile also causing increasing concerns about the environmental impact. This paper presents CoMERA, a Computing- and Memory-Efficient training method via Rank-Adaptive tensor optimization. CoMERA achieves end-to-end rank-adaptive tensor-compressed training via a multi-objective optimization formulation, and improves the training to provide both a high compression ratio and excellent accuracy in the training process. Our optimized numerical computation (e.g., optimized tensorized embedding and tensor-vector contractions) and GPU implementation eliminate part of the run-time overhead in the tensorized training on GPU. This leads to, for the first time, $2-3\times$ speedup per training epoch compared with standard training. CoMERA also outperforms the recent GaLore in terms of both memory and computing efficiency. Specifically, CoMERA is $2\times$ faster per training epoch and $9\times$ more memory-efficient than GaLore on a tested six-encoder transformer with single-batch training. With further HPC optimization, CoMERA may significantly reduce the training cost of large language models.
Equipping Transformer with Random-Access Reading for Long-Context Understanding
May 21, 2024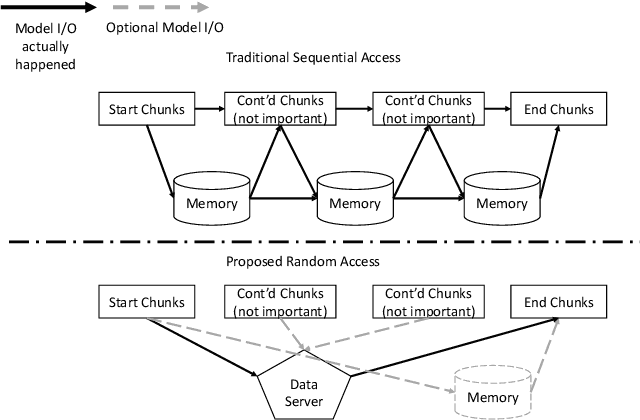

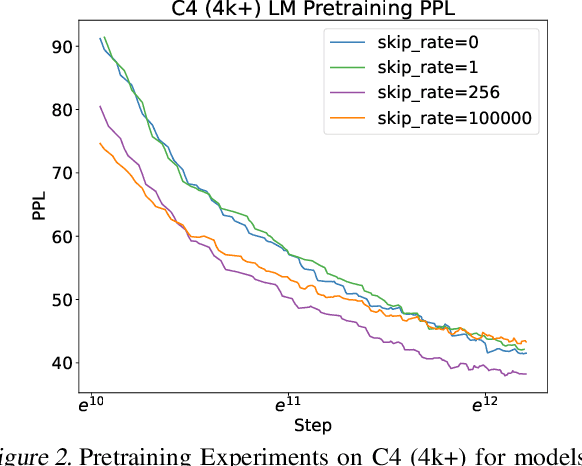
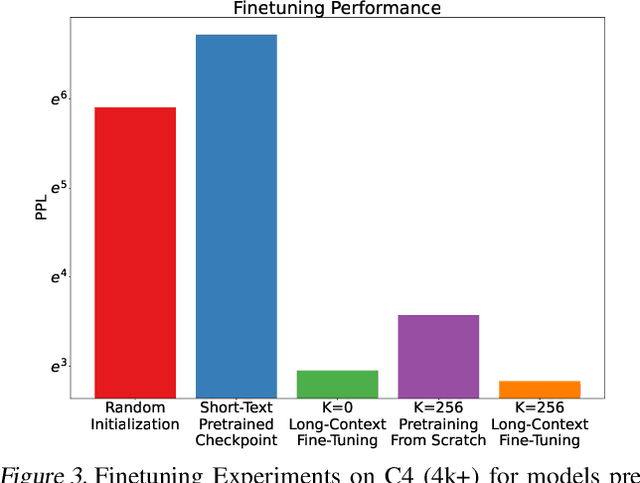
Long-context modeling presents a significant challenge for transformer-based large language models (LLMs) due to the quadratic complexity of the self-attention mechanism and issues with length extrapolation caused by pretraining exclusively on short inputs. Existing methods address computational complexity through techniques such as text chunking, the kernel approach, and structured attention, and tackle length extrapolation problems through positional encoding, continued pretraining, and data engineering. These approaches typically require $\textbf{sequential access}$ to the document, necessitating reading from the first to the last token. We contend that for goal-oriented reading of long documents, such sequential access is not necessary, and a proficiently trained model can learn to omit hundreds of less pertinent tokens. Inspired by human reading behaviors and existing empirical observations, we propose $\textbf{random access}$, a novel reading strategy that enables transformers to efficiently process long documents without examining every token. Experimental results from pretraining, fine-tuning, and inference phases validate the efficacy of our method.
Parameter-Efficient Fine-Tuning With Adapters
May 09, 2024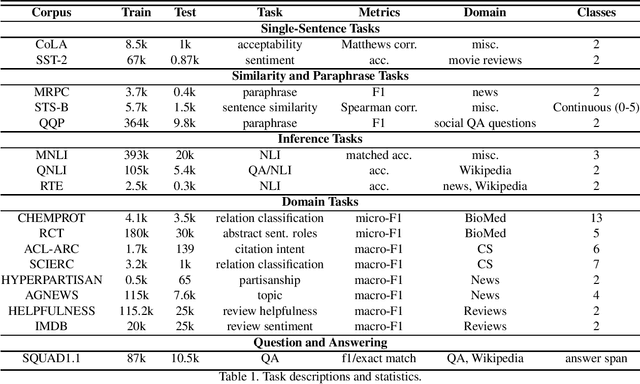



In the arena of language model fine-tuning, the traditional approaches, such as Domain-Adaptive Pretraining (DAPT) and Task-Adaptive Pretraining (TAPT), although effective, but computational intensive. This research introduces a novel adaptation method utilizing the UniPELT framework as a base and added a PromptTuning Layer, which significantly reduces the number of trainable parameters while maintaining competitive performance across various benchmarks. Our method employs adapters, which enable efficient transfer of pretrained models to new tasks with minimal retraining of the base model parameters. We evaluate our approach using three diverse datasets: the GLUE benchmark, a domain-specific dataset comprising four distinct areas, and the Stanford Question Answering Dataset 1.1 (SQuAD). Our results demonstrate that our customized adapter-based method achieves performance comparable to full model fine-tuning, DAPT+TAPT and UniPELT strategies while requiring fewer or equivalent amount of parameters. This parameter efficiency not only alleviates the computational burden but also expedites the adaptation process. The study underlines the potential of adapters in achieving high performance with significantly reduced resource consumption, suggesting a promising direction for future research in parameter-efficient fine-tuning.