 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Finer Better? The Limits of Microscaling Formats in Large Language Models
Jan 26, 2026Microscaling data formats leverage per-block tensor quantization to enable aggressive model compression with limited loss in accuracy. Unlocking their potential for efficient training and inference necessitates hardware-friendly implementations that handle matrix multiplications in a native format and adopt efficient error-mitigation strategies. Herein, we report the emergence of a surprising behavior associated with microscaling quantization, whereas the output of a quantized model degrades as block size is decreased below a given threshold. This behavior clashes with the expectation that a smaller block size should allow for a better representation of the tensor elements. We investigate this phenomenon both experimentally and theoretically, decoupling the sources of quantization error behind it. Experimentally, we analyze the distributions of several Large Language Models and identify the conditions driving the anomalous behavior. Theoretically, we lay down a framework showing remarkable agreement with experimental data from pretrained model distributions and ideal ones. Overall, we show that the anomaly is driven by the interplay between narrow tensor distributions and the limited dynamic range of the quantized scales. Based on these insights, we propose the use of FP8 unsigned E5M3 (UE5M3) as a novel hardware-friendly format for the scales in FP4 microscaling data types. We demonstrate that UE5M3 achieves comparable performance to the conventional FP8 unsigned E4M3 scales while obviating the need of global scaling operations on weights and activations.
Compressed Decentralized Momentum Stochastic Gradient Methods for Nonconvex Optimization
Aug 07, 2025In this paper, we design two compressed decentralized algorithms for solving nonconvex stochastic optimization under two different scenarios. Both algorithms adopt a momentum technique to achieve fast convergence and a message-compression technique to save communication costs. Though momentum acceleration and compressed communication have been used in literature, it is highly nontrivial to theoretically prove the effectiveness of their composition in a decentralized algorithm that can maintain the benefits of both sides, because of the need to simultaneously control the consensus error, the compression error, and the bias from the momentum gradient. For the scenario where gradients are bounded, our proposal is a compressed decentralized adaptive method. To the best of our knowledge, this is the first decentralized adaptive stochastic gradient method with compressed communication. For the scenario of data heterogeneity without bounded gradients, our proposal is a compressed decentralized heavy-ball method, which applies a gradient tracking technique to address the challenge of data heterogeneity. Notably, both methods achieve an optimal convergence rate, and they can achieve linear speed up and adopt topology-independent algorithmic parameters within a certain regime of the user-specified error tolerance. Superior empirical performance is observed over state-of-the-art methods on training deep neural networks (DNNs) and Transformers.
CLoQ: Enhancing Fine-Tuning of Quantized LLMs via Calibrated LoRA Initialization
Jan 30, 2025



Fine-tuning large language models (LLMs) using low-rank adaptation (LoRA) has become a highly efficient approach for downstream tasks, particularly in scenarios with limited computational resources. However, applying LoRA techniques to quantized LLMs poses unique challenges due to the reduced representational precision of quantized weights. In this paper, we introduce CLoQ (Calibrated LoRA initialization for Quantized LLMs), a simplistic initialization strategy designed to overcome these challenges. Our approach focuses on minimizing the layer-wise discrepancy between the original LLM and its quantized counterpart with LoRA components during initialization. By leveraging a small calibration dataset, CLoQ quantizes a pre-trained LLM and determines the optimal LoRA components for each layer, ensuring a strong foundation for subsequent fine-tuning. A key contribution of this work is a novel theoretical result that enables the accurate and closed-form construction of these optimal LoRA components. We validate the efficacy of CLoQ across multiple tasks such as language generation, arithmetic reasoning, and commonsense reasoning, demonstrating that it consistently outperforms existing LoRA fine-tuning methods for quantized LLMs, especially at ultra low-bit widths.
Unlocking Real-Time Fluorescence Lifetime Imaging: Multi-Pixel Parallelism for FPGA-Accelerated Processing
Oct 09, 2024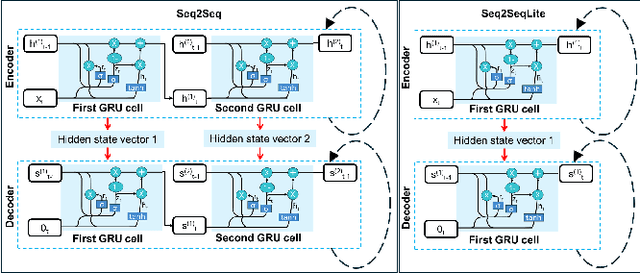
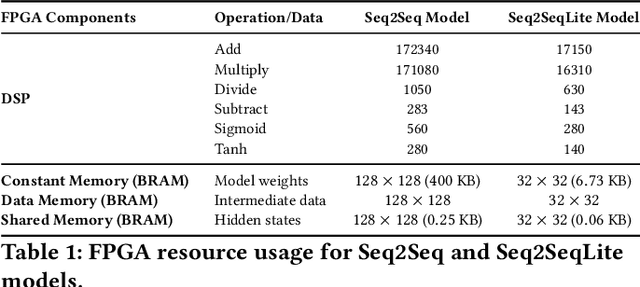


Fluorescence lifetime imaging (FLI) is a widely used technique in the biomedical field for measuring the decay times of fluorescent molecules, providing insights into metabolic states, protein interactions, and ligand-receptor bindings. However, its broader application in fast biological processes, such as dynamic activity monitoring, and clinical use, such as in guided surgery, is limited by long data acquisition times and computationally demanding data processing. While deep learning has reduced post-processing times, time-resolved data acquisition remains a bottleneck for real-time applications. To address this, we propose a method to achieve real-time FLI using an FPGA-based hardware accelerator. Specifically, we implemented a GRU-based sequence-to-sequence (Seq2Seq) model on an FPGA board compatible with time-resolved cameras. The GRU model balances accurate processing with the resource constraints of FPGAs, which have limited DSP units and BRAM. The limited memory and computational resources on the FPGA require efficient scheduling of operations and memory allocation to deploy deep learning models for low-latency applications. We address these challenges by using STOMP, a queue-based discrete-event simulator that automates and optimizes task scheduling and memory management on hardware. By integrating a GRU-based Seq2Seq model and its compressed version, called Seq2SeqLite, generated through knowledge distillation, we were able to process multiple pixels in parallel, reducing latency compared to sequential processing. We explore various levels of parallelism to achieve an optimal balance between performance and resource utilization. Our results indicate that the proposed techniques achieved a 17.7x and 52.0x speedup over manual scheduling for the Seq2Seq model and the Seq2SeqLite model, respectively.
Compressing Recurrent Neural Networks for FPGA-accelerated Implementation in Fluorescence Lifetime Imaging
Oct 01, 2024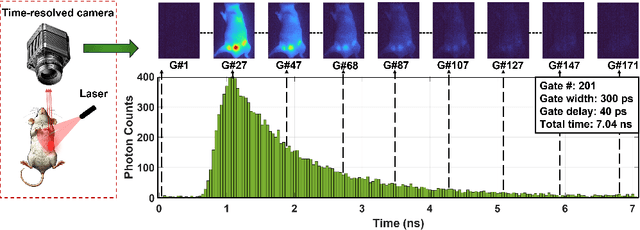

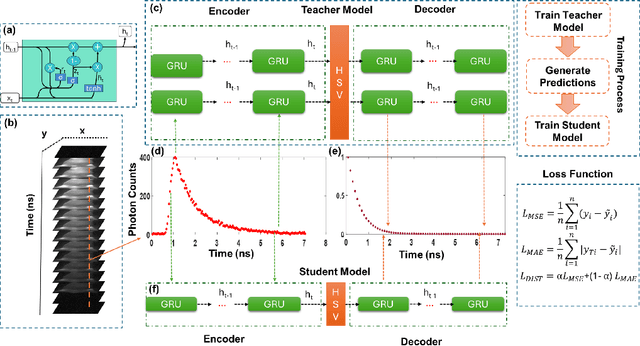
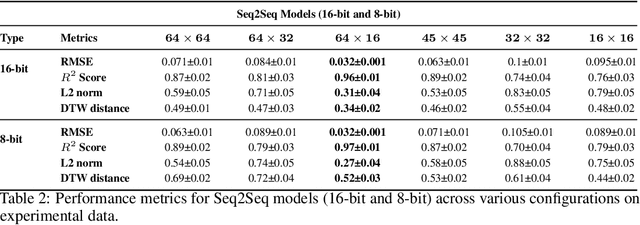
Fluorescence lifetime imaging (FLI) is an important technique for studying cellular environments and molecular interactions, but its real-time application is limited by slow data acquisition, which requires capturing large time-resolved images and complex post-processing using iterative fitting algorithms. Deep learning (DL) models enable real-time inference, but can be computationally demanding due to complex architectures and large matrix operations. This makes DL models ill-suited for direct implementation on field-programmable gate array (FPGA)-based camera hardware. Model compression is thus crucial for practical deployment for real-time inference generation. In this work, we focus on compressing recurrent neural networks (RNNs), which are well-suited for FLI time-series data processing, to enable deployment on resource-constrained FPGA boards. We perform an empirical evaluation of various compression techniques, including weight reduction, knowledge distillation (KD), post-training quantization (PTQ), and quantization-aware training (QAT), to reduce model size and computational load while preserving inference accuracy. Our compressed RNN model, Seq2SeqLite, achieves a balance between computational efficiency and prediction accuracy, particularly at 8-bit precision. By applying KD, the model parameter size was reduced by 98\% while retaining performance, making it suitable for concurrent real-time FLI analysis on FPGA during data capture. This work represents a big step towards integrating hardware-accelerated real-time FLI analysis for fast biological processes.
MagR: Weight Magnitude Reduction for Enhancing Post-Training Quantization
Jun 02, 2024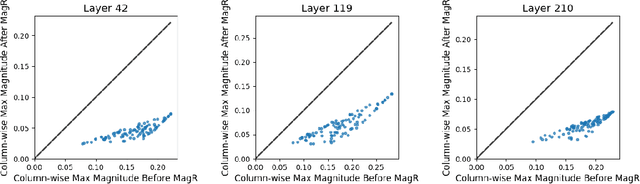
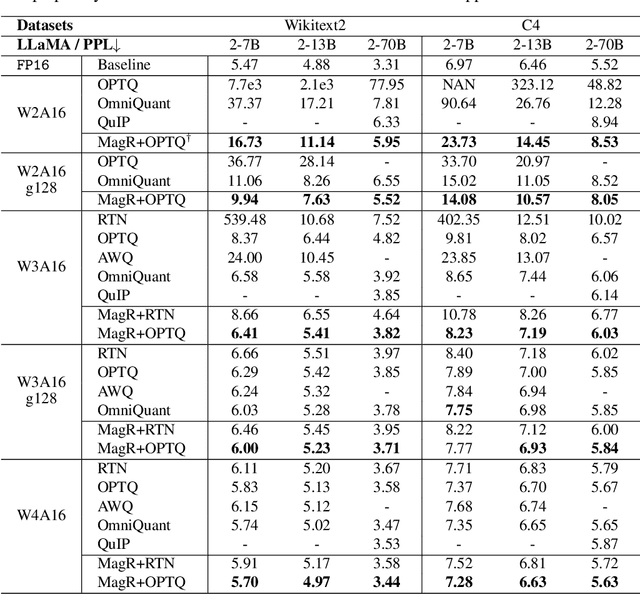
In this paper, we present a simple optimization-based preprocessing technique called Weight Magnitude Reduction (MagR) to improve the performance of post-training quantization. For each linear layer, we adjust the pre-trained floating-point weights by solving an $\ell_\infty$-regularized optimization problem. This process greatly diminishes the maximum magnitude of the weights and smooths out outliers, while preserving the layer's output. The preprocessed weights are centered more towards zero, which facilitates the subsequent quantization process. To implement MagR, we address the $\ell_\infty$-regularization by employing an efficient proximal gradient descent algorithm. Unlike existing preprocessing methods that involve linear transformations and subsequent post-processing steps, which can introduce significant overhead at inference time, MagR functions as a non-linear transformation, eliminating the need for any additional post-processing. This ensures that MagR introduces no overhead whatsoever during inference. Our experiments demonstrate that MagR achieves state-of-the-art performance on the Llama family of models. For example, we achieve a Wikitext2 perplexity of 5.95 on the LLaMA2-70B model for per-channel INT2 weight quantization without incurring any inference overhead.
A Provably Effective Method for Pruning Experts in Fine-tuned Sparse Mixture-of-Experts
May 28, 2024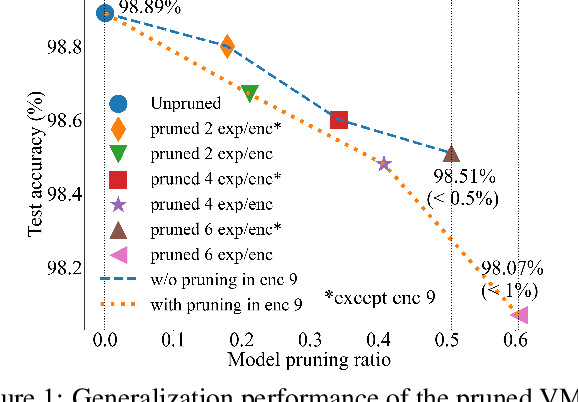
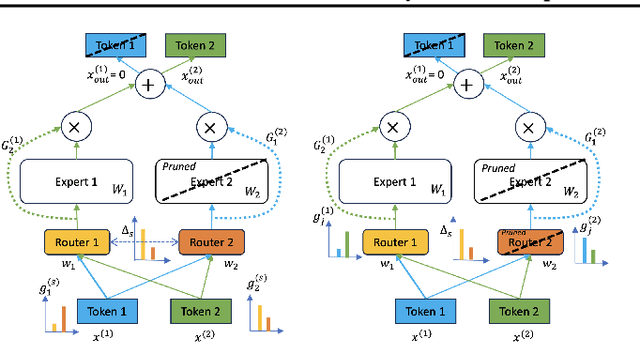
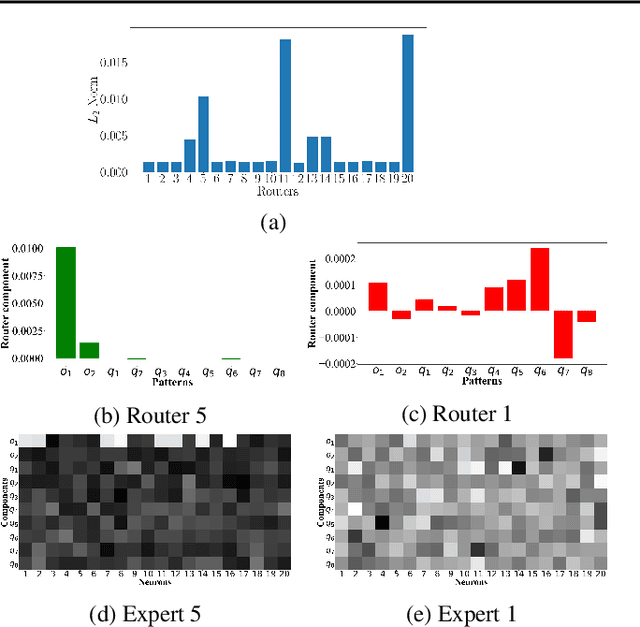
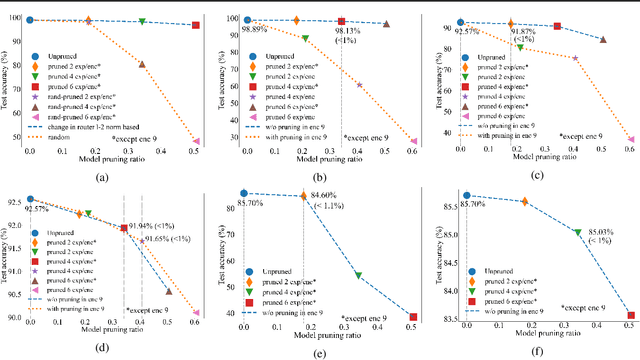
The sparsely gated mixture of experts (MoE) architecture sends different inputs to different subnetworks, i.e., experts, through trainable routers. MoE reduces the training computation significantly for large models, but its deployment can be still memory or computation expensive for some downstream tasks. Model pruning is a popular approach to reduce inference computation, but its application in MoE architecture is largely unexplored. To the best of our knowledge, this paper provides the first provably efficient technique for pruning experts in finetuned MoE models. We theoretically prove that prioritizing the pruning of the experts with a smaller change of the routers l2 norm from the pretrained model guarantees the preservation of test accuracy, while significantly reducing the model size and the computational requirements. Although our theoretical analysis is centered on binary classification tasks on simplified MoE architecture, our expert pruning method is verified on large vision MoE models such as VMoE and E3MoE finetuned on benchmark datasets such as CIFAR10, CIFAR100, and ImageNet.
Mitigating the Impact of Outlier Channels for Language Model Quantization with Activation Regularization
Apr 04, 2024

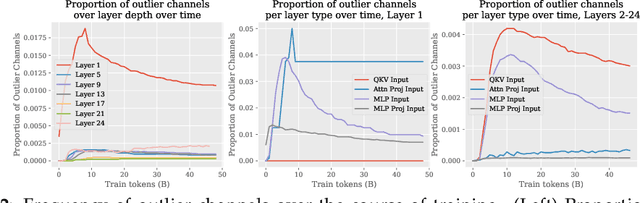

We consider the problem of accurate quantization for language models, where both the weights and activations are uniformly quantized to 4 bits per parameter, the lowest bitwidth format natively supported by GPU hardware. In this context, the key challenge is activation quantization: it is known that language models contain outlier channels whose values on average are orders of magnitude higher than than other channels, which prevents accurate low-bitwidth quantization with known techniques. We systematically study this phenomena and find that these outlier channels emerge early in training, and that they occur more frequently in layers with residual streams. We then propose a simple strategy which regularizes a layer's inputs via quantization-aware training (QAT) and its outputs via activation kurtosis regularization. We show that regularizing both the inputs and outputs is crucial for preventing a model's "migrating" the difficulty in input quantization to the weights, which makes post-training quantization (PTQ) of weights more difficult. When combined with weight PTQ, we show that our approach can obtain a W4A4 model that performs competitively to the standard-precision W16A16 baseline.
COMQ: A Backpropagation-Free Algorithm for Post-Training Quantization
Mar 11, 2024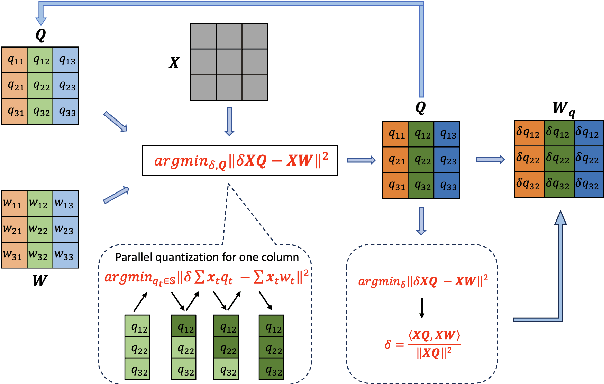
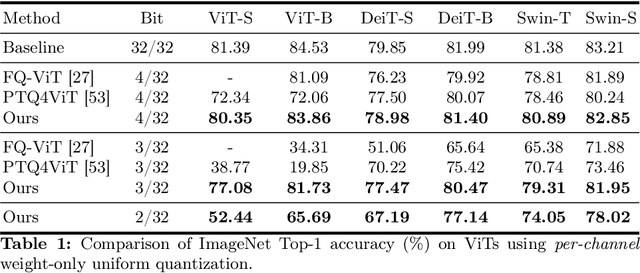
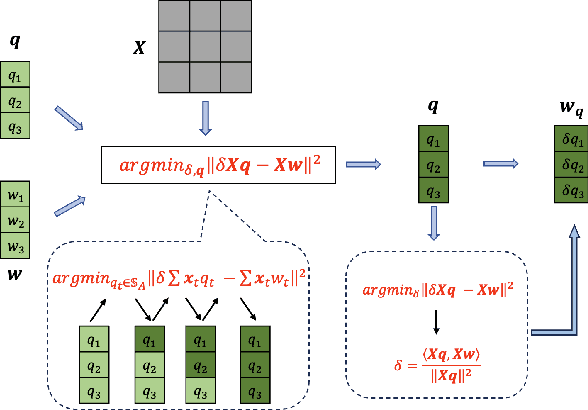
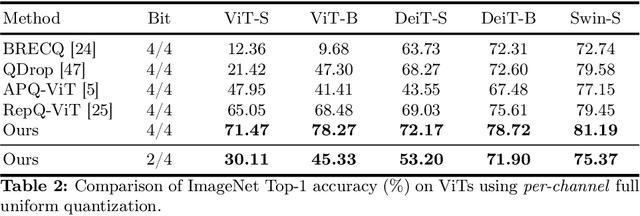
Post-training quantization (PTQ) has emerged as a practical approach to compress large neural networks, making them highly efficient for deployment. However, effectively reducing these models to their low-bit counterparts without compromising the original accuracy remains a key challenge. In this paper, we propose an innovative PTQ algorithm termed COMQ, which sequentially conducts coordinate-wise minimization of the layer-wise reconstruction errors. We consider the widely used integer quantization, where every quantized weight can be decomposed into a shared floating-point scalar and an integer bit-code. Within a fixed layer, COMQ treats all the scaling factor(s) and bit-codes as the variables of the reconstruction error. Every iteration improves this error along a single coordinate while keeping all other variables constant. COMQ is easy to use and requires no hyper-parameter tuning. It instead involves only dot products and rounding operations. We update these variables in a carefully designed greedy order, significantly enhancing the accuracy. COMQ achieves remarkable results in quantizing 4-bit Vision Transformers, with a negligible loss of less than 1% in Top-1 accuracy. In 4-bit INT quantization of convolutional neural networks, COMQ maintains near-lossless accuracy with a minimal drop of merely 0.3% in Top-1 accuracy.
4-bit Quantization of LSTM-based Speech Recognition Models
Aug 27, 2021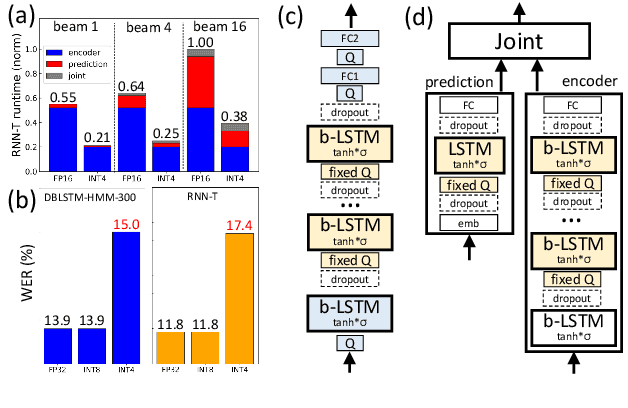
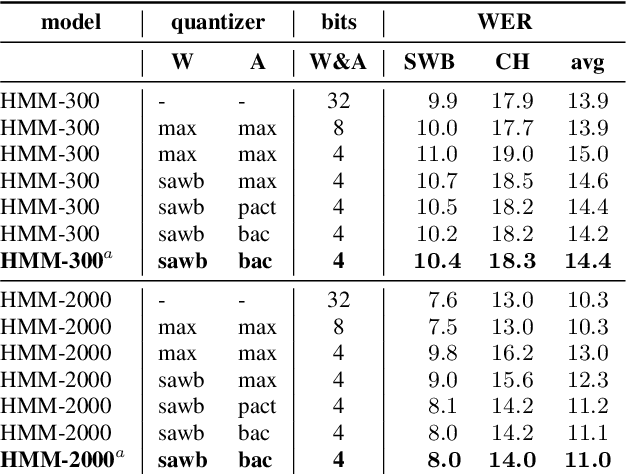
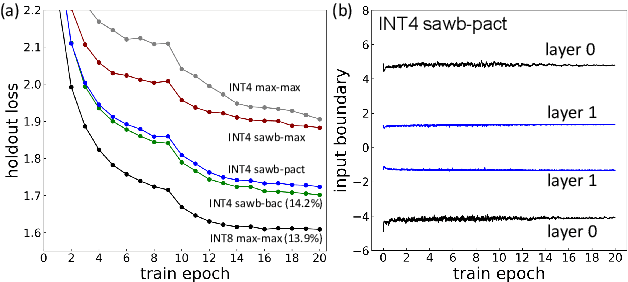
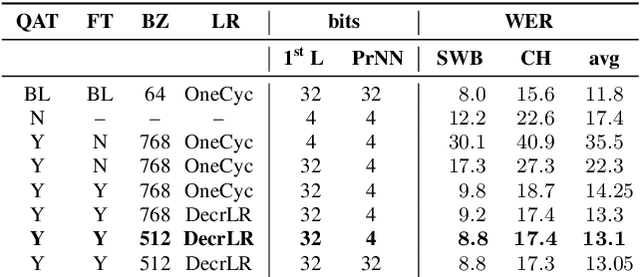
We investigate the impact of aggressive low-precision representations of weights and activations in two families of large LSTM-based architectures for Automatic Speech Recognition (ASR): hybrid Deep Bidirectional LSTM - Hidden Markov Models (DBLSTM-HMMs) and Recurrent Neural Network - Transducers (RNN-Ts). Using a 4-bit integer representation, a na\"ive quantization approach applied to the LSTM portion of these models results in significant Word Error Rate (WER) degradation. On the other hand, we show that minimal accuracy loss is achievable with an appropriate choice of quantizers and initializations. In particular, we customize quantization schemes depending on the local properties of the network, improving recognition performance while limiting computational time. We demonstrate our solution on the Switchboard (SWB) and CallHome (CH) test sets of the NIST Hub5-2000 evaluation. DBLSTM-HMMs trained with 300 or 2000 hours of SWB data achieves $<$0.5% and $<$1% average WER degradation, respectively. On the more challenging RNN-T models, our quantization strategy limits degradation in 4-bit inference to 1.3%.