 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Quantization of Mixture-of-Experts with Theoretical Generalization Guarantees
Apr 07, 2026Sparse Mixture-of-Experts (MoE) allows scaling of language and vision models efficiently by activating only a small subset of experts per input. While this reduces computation, the large number of parameters still incurs substantial memory overhead during inference. Post-training quantization has been explored to address this issue. Because uniform quantization suffers from significant accuracy loss at low bit-widths, mixed-precision methods have been recently explored; however, they often require substantial computation for bit-width allocation and overlook the varying sensitivity of model performance to the quantization of different experts. We propose a theoretically grounded expert-wise mixed precision strategy that assigns bit-width to each expert primarily based on their change in routers l2 norm during training. Experts with smaller changes are shown to capture less frequent but critical features, and model performance is more sensitive to the quantization of these experts, thus requiring higher precision. Furthermore, to avoid allocating experts to lower precision that inject high quantization noise, experts with large maximum intra-neuron variance are also allocated higher precision. Experiments on large-scale MoE models, including Switch Transformer and Mixtral, show that our method achieves higher accuracy than existing approaches, while also reducing inference cost and incurring only negligible overhead for bit-width assignment.
Evaluating Fine-Tuned LLM Model For Medical Transcription With Small Low-Resource Languages Validated Dataset
Mar 25, 2026Clinical documentation is a critical factor for patient safety, diagnosis, and continuity of care. The administrative burden of EHRs is a significant factor in physician burnout. This is a critical issue for low-resource languages, including Finnish. This study aims to investigate the effectiveness of a domain-aligned natural language processing (NLP); large language model for medical transcription in Finnish by fine-tuning LLaMA 3.1-8B on a small validated corpus of simulated clinical conversations by students at Metropolia University of Applied Sciences. The fine-tuning process for medical transcription used a controlled preprocessing and optimization approach. The fine-tuning effectiveness was evaluated by sevenfold cross-validation. The evaluation metrics for fine-tuned LLaMA 3.1-8B were BLEU = 0.1214, ROUGE-L = 0.4982, and BERTScore F1 = 0.8230. The results showed a low n-gram overlap but a strong semantic similarity with reference transcripts. This study indicate that fine-tuning can be an effective approach for translation of medical discourse in spoken Finnish and support the feasibility of fine-tuning a privacy-oriented domain-specific large language model for clinical documentation in Finnish. Beside that provide directions for future work.
Robust Heterogeneous Analog-Digital Computing for Mixture-of-Experts Models with Theoretical Generalization Guarantees
Mar 03, 2026Sparse Mixture-of-Experts (MoE) models enable efficient scalability by activating only a small sub-set of experts per input, yet their massive parameter counts lead to substantial memory and energy inefficiency during inference. Analog in-memory computing (AIMC) offers a promising solution by eliminating frequent data movement between memory and compute units. However, mitigating hardware nonidealities of AIMC typically requires noise-aware retraining, which is infeasible for large MoE models. In this paper, we propose a retraining-free heterogeneous computation framework in which noise-sensitive experts, which are provably identifiable by their maximum neuron norm, are computed digitally while the majority of the experts are executed on AIMC hardware. We further assign densely activated modules, such as attention layers, to digital computation due to their high noise sensitivity despite comprising a small fraction of parameters. Extensive experiments on large MoE language models, including DeepSeekMoE and OLMoE, across multiple benchmark tasks validate the robustness of our approach in maintaining accuracy under analog nonidealities.
A Provably Effective Method for Pruning Experts in Fine-tuned Sparse Mixture-of-Experts
May 28, 2024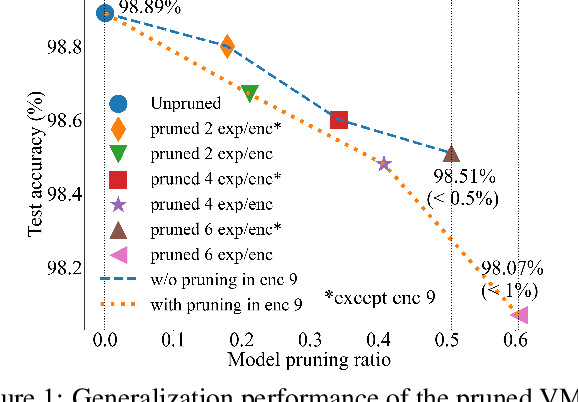
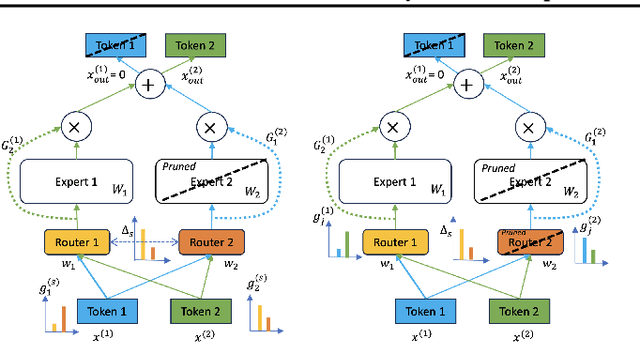
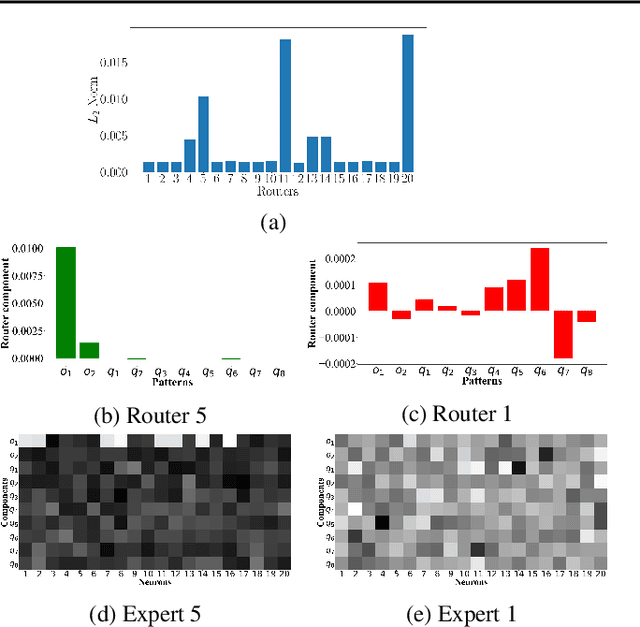
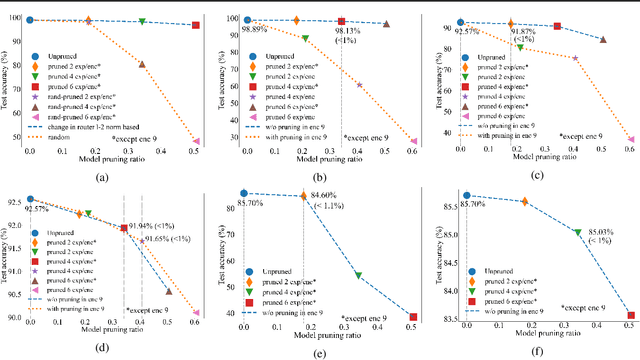
The sparsely gated mixture of experts (MoE) architecture sends different inputs to different subnetworks, i.e., experts, through trainable routers. MoE reduces the training computation significantly for large models, but its deployment can be still memory or computation expensive for some downstream tasks. Model pruning is a popular approach to reduce inference computation, but its application in MoE architecture is largely unexplored. To the best of our knowledge, this paper provides the first provably efficient technique for pruning experts in finetuned MoE models. We theoretically prove that prioritizing the pruning of the experts with a smaller change of the routers l2 norm from the pretrained model guarantees the preservation of test accuracy, while significantly reducing the model size and the computational requirements. Although our theoretical analysis is centered on binary classification tasks on simplified MoE architecture, our expert pruning method is verified on large vision MoE models such as VMoE and E3MoE finetuned on benchmark datasets such as CIFAR10, CIFAR100, and ImageNet.
Patch-level Routing in Mixture-of-Experts is Provably Sample-efficient for Convolutional Neural Networks
Jun 07, 2023


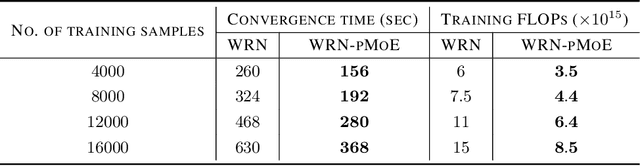
In deep learning, mixture-of-experts (MoE) activates one or few experts (sub-networks) on a per-sample or per-token basis, resulting in significant computation reduction. The recently proposed \underline{p}atch-level routing in \underline{MoE} (pMoE) divides each input into $n$ patches (or tokens) and sends $l$ patches ($l\ll n$) to each expert through prioritized routing. pMoE has demonstrated great empirical success in reducing training and inference costs while maintaining test accuracy. However, the theoretical explanation of pMoE and the general MoE remains elusive. Focusing on a supervised classification task using a mixture of two-layer convolutional neural networks (CNNs), we show for the first time that pMoE provably reduces the required number of training samples to achieve desirable generalization (referred to as the sample complexity) by a factor in the polynomial order of $n/l$, and outperforms its single-expert counterpart of the same or even larger capacity. The advantage results from the discriminative routing property, which is justified in both theory and practice that pMoE routers can filter label-irrelevant patches and route similar class-discriminative patches to the same expert. Our experimental results on MNIST, CIFAR-10, and CelebA support our theoretical findings on pMoE's generalization and show that pMoE can avoid learning spurious correlations.