 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Temporal Semantic Caching and Workflow Optimization in Agentic Plan-Execute Pipelines
May 20, 2026Industrial asset operations workflows are latency-sensitive because a single user query may require coordination over sensor data, work orders, failure modes, forecasting tools, and domain-specific agents. We evaluate this problem on AssetOpsBench (AOB), an industrial agent benchmark whose plan-execute pipeline exposes repeated overhead from tool discovery, LLM planning, MCP tool execution, and final summarization. Existing LLM caching techniques such as KV-cache reuse and embedding-based semantic caching were designed for chatbot serving and break down when output validity depends on time, asset, or sensor parameters. We propose two complementary optimization layers for AOB plan-execute pipelines: a temporal semantic cache and a set of MCP workflow optimizations combining disk-backed tool-discovery caching and dependency-aware parallel step execution. MCP workflow optimizations corresponded to a 1.67x speedup and reduced median end-to-end latency by about 40.0% while the temporal-cache benchmark achieved a median of 30.6x speedup on cache hits. Beyond the speedup, our results expose a concrete failure mode of pure semantic caching for parameter-rich industrial queries, providing a critical analysis of how caching choices interact with evaluation correctness in MCP-backed agent benchmarks.
Efficient Quantization of Mixture-of-Experts with Theoretical Generalization Guarantees
Apr 07, 2026Sparse Mixture-of-Experts (MoE) allows scaling of language and vision models efficiently by activating only a small subset of experts per input. While this reduces computation, the large number of parameters still incurs substantial memory overhead during inference. Post-training quantization has been explored to address this issue. Because uniform quantization suffers from significant accuracy loss at low bit-widths, mixed-precision methods have been recently explored; however, they often require substantial computation for bit-width allocation and overlook the varying sensitivity of model performance to the quantization of different experts. We propose a theoretically grounded expert-wise mixed precision strategy that assigns bit-width to each expert primarily based on their change in routers l2 norm during training. Experts with smaller changes are shown to capture less frequent but critical features, and model performance is more sensitive to the quantization of these experts, thus requiring higher precision. Furthermore, to avoid allocating experts to lower precision that inject high quantization noise, experts with large maximum intra-neuron variance are also allocated higher precision. Experiments on large-scale MoE models, including Switch Transformer and Mixtral, show that our method achieves higher accuracy than existing approaches, while also reducing inference cost and incurring only negligible overhead for bit-width assignment.
Robust Heterogeneous Analog-Digital Computing for Mixture-of-Experts Models with Theoretical Generalization Guarantees
Mar 03, 2026Sparse Mixture-of-Experts (MoE) models enable efficient scalability by activating only a small sub-set of experts per input, yet their massive parameter counts lead to substantial memory and energy inefficiency during inference. Analog in-memory computing (AIMC) offers a promising solution by eliminating frequent data movement between memory and compute units. However, mitigating hardware nonidealities of AIMC typically requires noise-aware retraining, which is infeasible for large MoE models. In this paper, we propose a retraining-free heterogeneous computation framework in which noise-sensitive experts, which are provably identifiable by their maximum neuron norm, are computed digitally while the majority of the experts are executed on AIMC hardware. We further assign densely activated modules, such as attention layers, to digital computation due to their high noise sensitivity despite comprising a small fraction of parameters. Extensive experiments on large MoE language models, including DeepSeekMoE and OLMoE, across multiple benchmark tasks validate the robustness of our approach in maintaining accuracy under analog nonidealities.
SparseST: Exploiting Data Sparsity in Spatiotemporal Modeling and Prediction
Nov 18, 2025Spatiotemporal data mining (STDM) has a wide range of applications in various complex physical systems (CPS), i.e., transportation, manufacturing, healthcare, etc. Among all the proposed methods, the Convolutional Long Short-Term Memory (ConvLSTM) has proved to be generalizable and extendable in different applications and has multiple variants achieving state-of-the-art performance in various STDM applications. However, ConvLSTM and its variants are computationally expensive, which makes them inapplicable in edge devices with limited computational resources. With the emerging need for edge computing in CPS, efficient AI is essential to reduce the computational cost while preserving the model performance. Common methods of efficient AI are developed to reduce redundancy in model capacity (i.e., model pruning, compression, etc.). However, spatiotemporal data mining naturally requires extensive model capacity, as the embedded dependencies in spatiotemporal data are complex and hard to capture, which limits the model redundancy. Instead, there is a fairly high level of data and feature redundancy that introduces an unnecessary computational burden, which has been largely overlooked in existing research. Therefore, we developed a novel framework SparseST, that pioneered in exploiting data sparsity to develop an efficient spatiotemporal model. In addition, we explore and approximate the Pareto front between model performance and computational efficiency by designing a multi-objective composite loss function, which provides a practical guide for practitioners to adjust the model according to computational resource constraints and the performance requirements of downstream tasks.
Paged Attention Meets FlexAttention: Unlocking Long-Context Efficiency in Deployed Inference
Jun 08, 2025



Large Language Models (LLMs) encounter severe memory inefficiencies during long-context inference due to conventional handling of key-value (KV) caches. In this work, we introduce a novel integration of PagedAttention with PyTorch's FlexAttention, addressing internal fragmentation and inefficiencies associated with monolithic KV cache allocations. Implemented within IBM's Foundation Model Stack (FMS), our fused attention kernel efficiently gathers scattered KV data. Our benchmarks on an NVIDIA L4 GPU (24GB) demonstrate significantly reduced inference latency, growing only linearly (~2x) with sequence length from 128 to 2048 tokens when utilizing a global KV cache, compared to exponential latency increases without caching. While peak memory usage remains largely unchanged for single-step evaluations (dominated by model weights and activations), paged attention causes minimal incremental memory usage, observable only at sequence lengths exceeding 2048 tokens due to its power-of-two cache allocations. We open-source the full implementation and discuss its implications for future long-context model deployment.
Analog Foundation Models
May 14, 2025Analog in-memory computing (AIMC) is a promising compute paradigm to improve speed and power efficiency of neural network inference beyond the limits of conventional von Neumann-based architectures. However, AIMC introduces fundamental challenges such as noisy computations and strict constraints on input and output quantization. Because of these constraints and imprecisions, off-the-shelf LLMs are not able to achieve 4-bit-level performance when deployed on AIMC-based hardware. While researchers previously investigated recovering this accuracy gap on small, mostly vision-based models, a generic method applicable to LLMs pre-trained on trillions of tokens does not yet exist. In this work, we introduce a general and scalable method to robustly adapt LLMs for execution on noisy, low-precision analog hardware. Our approach enables state-of-the-art models $\unicode{x2013}$ including Phi-3-mini-4k-instruct and Llama-3.2-1B-Instruct $\unicode{x2013}$ to retain performance comparable to 4-bit weight, 8-bit activation baselines, despite the presence of analog noise and quantization constraints. Additionally, we show that as a byproduct of our training methodology, analog foundation models can be quantized for inference on low-precision digital hardware. Finally, we show that our models also benefit from test-time compute scaling, showing better scaling behavior than models trained with 4-bit weight and 8-bit static input quantization. Our work bridges the gap between high-capacity LLMs and efficient analog hardware, offering a path toward energy-efficient foundation models. Code is available at https://github.com/IBM/analog-foundation-models .
Pipeline Gradient-based Model Training on Analog In-memory Accelerators
Oct 19, 2024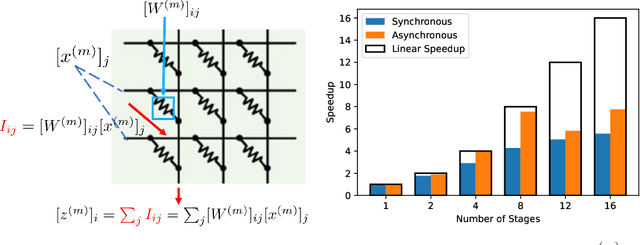

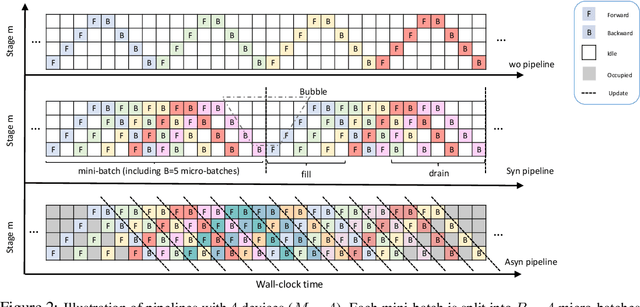
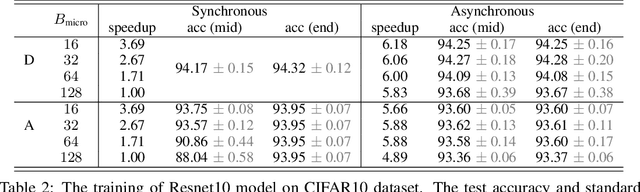
Aiming to accelerate the training of large deep neural models (DNN) in an energy-efficient way, an analog in-memory computing (AIMC) accelerator emerges as a solution with immense potential. In AIMC accelerators, trainable weights are kept in memory without the need to move from memory to processors during the training, reducing a bunch of overhead. However, although the in-memory feature enables efficient computation, it also constrains the use of data parallelism since copying weights from one AIMC to another is expensive. To enable parallel training using AIMC, we propose synchronous and asynchronous pipeline parallelism for AIMC accelerators inspired by the pipeline in digital domains. This paper provides a theoretical convergence guarantee for both synchronous and asynchronous pipelines in terms of both sampling and clock cycle complexity, which is non-trivial since the physical characteristic of AIMC accelerators leads to analog updates that suffer from asymmetric bias. The simulations of training DNN on real datasets verify the efficiency of pipeline training.
A Provably Effective Method for Pruning Experts in Fine-tuned Sparse Mixture-of-Experts
May 28, 2024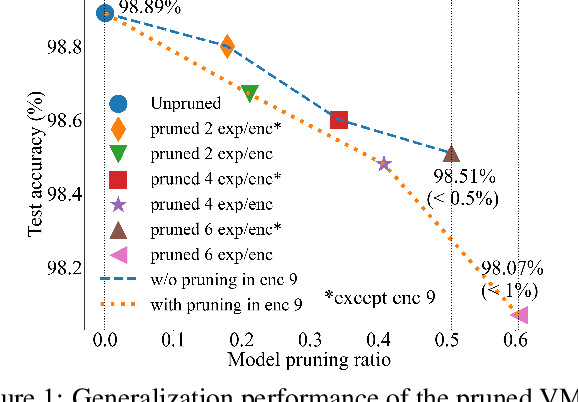
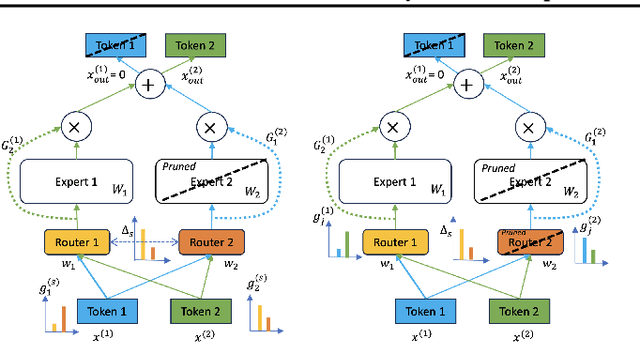
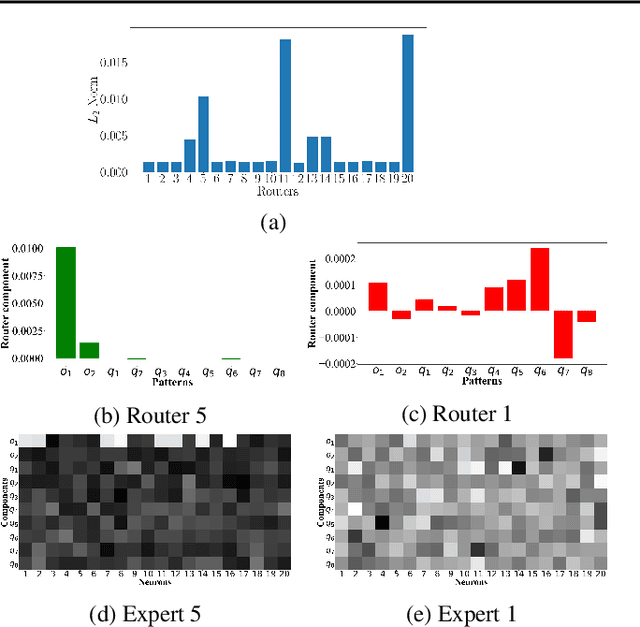
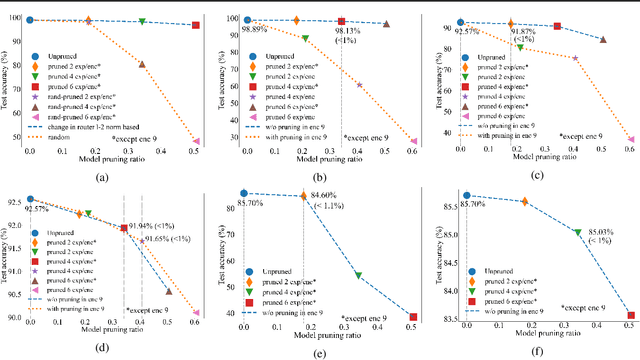
The sparsely gated mixture of experts (MoE) architecture sends different inputs to different subnetworks, i.e., experts, through trainable routers. MoE reduces the training computation significantly for large models, but its deployment can be still memory or computation expensive for some downstream tasks. Model pruning is a popular approach to reduce inference computation, but its application in MoE architecture is largely unexplored. To the best of our knowledge, this paper provides the first provably efficient technique for pruning experts in finetuned MoE models. We theoretically prove that prioritizing the pruning of the experts with a smaller change of the routers l2 norm from the pretrained model guarantees the preservation of test accuracy, while significantly reducing the model size and the computational requirements. Although our theoretical analysis is centered on binary classification tasks on simplified MoE architecture, our expert pruning method is verified on large vision MoE models such as VMoE and E3MoE finetuned on benchmark datasets such as CIFAR10, CIFAR100, and ImageNet.
Grassroots Operator Search for Model Edge Adaptation
Sep 20, 2023



Hardware-aware Neural Architecture Search (HW-NAS) is increasingly being used to design efficient deep learning architectures. An efficient and flexible search space is crucial to the success of HW-NAS. Current approaches focus on designing a macro-architecture and searching for the architecture's hyperparameters based on a set of possible values. This approach is biased by the expertise of deep learning (DL) engineers and standard modeling approaches. In this paper, we present a Grassroots Operator Search (GOS) methodology. Our HW-NAS adapts a given model for edge devices by searching for efficient operator replacement. We express each operator as a set of mathematical instructions that capture its behavior. The mathematical instructions are then used as the basis for searching and selecting efficient replacement operators that maintain the accuracy of the original model while reducing computational complexity. Our approach is grassroots since it relies on the mathematical foundations to construct new and efficient operators for DL architectures. We demonstrate on various DL models, that our method consistently outperforms the original models on two edge devices, namely Redmi Note 7S and Raspberry Pi3, with a minimum of 2.2x speedup while maintaining high accuracy. Additionally, we showcase a use case of our GOS approach in pulse rate estimation on wristband devices, where we achieve state-of-the-art performance, while maintaining reduced computational complexity, demonstrating the effectiveness of our approach in practical applications.
Using the IBM Analog In-Memory Hardware Acceleration Kit for Neural Network Training and Inference
Jul 18, 2023

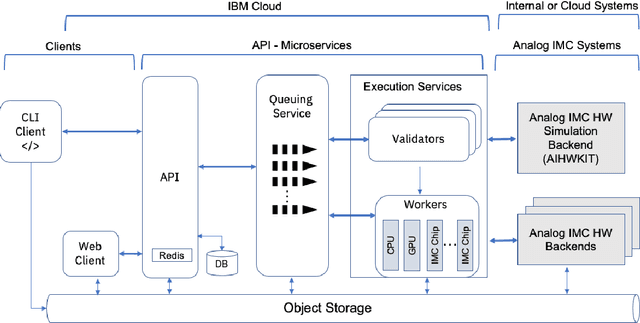

Analog In-Memory Computing (AIMC) is a promising approach to reduce the latency and energy consumption of Deep Neural Network (DNN) inference and training. However, the noisy and non-linear device characteristics, and the non-ideal peripheral circuitry in AIMC chips, require adapting DNNs to be deployed on such hardware to achieve equivalent accuracy to digital computing. In this tutorial, we provide a deep dive into how such adaptations can be achieved and evaluated using the recently released IBM Analog Hardware Acceleration Kit (AIHWKit), freely available at https://github.com/IBM/aihwkit. The AIHWKit is a Python library that simulates inference and training of DNNs using AIMC. We present an in-depth description of the AIHWKit design, functionality, and best practices to properly perform inference and training. We also present an overview of the Analog AI Cloud Composer, that provides the benefits of using the AIHWKit simulation platform in a fully managed cloud setting. Finally, we show examples on how users can expand and customize AIHWKit for their own needs. This tutorial is accompanied by comprehensive Jupyter Notebook code examples that can be run using AIHWKit, which can be downloaded from https://github.com/IBM/aihwkit/tree/master/notebooks/tutorial.