 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAda2MS: A Hybrid Optimization Algorithm Based on Exponential Mixing of Elementwise and Global Second-Moment Estimates
May 19, 2026Optimization algorithms are core methods by which machine learning models iteratively minimize loss functions, update parameters, learn from data, and improve performance. Momentum SGD and AdamW represent two important optimization paradigms. AdamW produces stable updates and usually has strong robustness across training scenarios, but its generalization performance is sometimes weaker than that of momentum methods. Momentum SGD can often obtain better generalization after careful tuning, but it is more sensitive to gradient-scale variation and hyperparameter settings. To balance the strengths and weaknesses of the two paradigms, this paper proposes Ada2MS, an optimization algorithm that achieves a smooth transition between AdamW-like behavior and momentum-SGD-like behavior through continuous exponential interpolation between elementwise second-moment estimates and global second-moment estimates. On the visual tasks evaluated in this study, Ada2MS obtains competitive results under a unified optimizer-comparison protocol. The code will be released at https://github.com/mengzhu0308/Ada2MS
Dynamic Symmetric Point Tracking: Tackling Non-ideal Reference in Analog In-memory Training
Feb 24, 2026Analog in-memory computing (AIMC) performs computation directly within resistive crossbar arrays, offering an energy-efficient platform to scale large vision and language models. However, non-ideal analog device properties make the training on AIMC devices challenging. In particular, its update asymmetry can induce a systematic drift of weight updates towards a device-specific symmetric point (SP), which typically does not align with the optimum of the training objective. To mitigate this bias, most existing works assume the SP is known and pre-calibrate it to zero before training by setting the reference point as the SP. Nevertheless, calibrating AIMC devices requires costly pulse updates, and residual calibration error can directly degrade training accuracy. In this work, we present the first theoretical characterization of the pulse complexity of SP calibration and the resulting estimation error. We further propose a dynamic SP estimation method that tracks the SP during model training, and establishes its convergence guarantees. In addition, we develop an enhanced variant based on chopping and filtering techniques from digital signal processing. Numerical experiments demonstrate both the efficiency and effectiveness of the proposed method.
AdamX: An Adam improvement algorithm based on a novel exponential decay mechanism for the second-order moment estimate
Nov 19, 2025

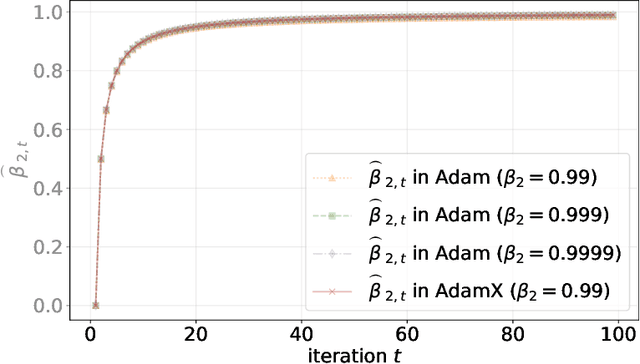

Since the 21st century, artificial intelligence has been leading a new round of industrial revolution. Under the training framework, the optimization algorithm aims to stably converge high-dimensional optimization to local and even global minima. Entering the era of large language models, although the scale of model parameters and data has increased, Adam remains the mainstream optimization algorithm. However, compared with stochastic gradient descent (SGD) based optimization algorithms, Adam is more likely to converge to non-flat minima. To address this issue, the AdamX algorithm is proposed. Its core innovation lies in the proposition of a novel type of second-order moment estimation exponential decay rate, which gradually weakens the learning step correction strength as training progresses, and degrades to SGD in the stable training period, thereby improving the stability of training in the stable period and possibly enhancing generalization ability. Experimental results show that our second-order moment estimation exponential decay rate is better than the current second-order moment estimation exponential decay rate, and AdamX can stably outperform Adam and its variants in terms of performance. Our code is open-sourced at https://github.com/mengzhu0308/AdamX.
Geometric Iterative Approach for Efficient Inverse Kinematics and Planning of Continuum Robots with a Floating Base Under Environment Constraints
Mar 19, 2025Continuum robots with floating bases demonstrate exceptional operational capabilities in confined spaces, such as those encountered in medical surgeries and equipment maintenance. However, developing low-cost solutions for their motion and planning problems remains a significant challenge in this field. This paper investigates the application of geometric iterative strategy methods to continuum robots, and proposes the algorithm based on an improved two-layer geometric iterative strategy for motion planning. First, we thoroughly study the kinematics and effective workspace of a multi-segment tendon-driven continuum robot with a floating base. Then, generalized iterative algorithms for solving arbitrary-segment continuum robots are proposed based on a series of problems such as initial arm shape dependence exhibited by similar methods when applied to continuum robots. Further, the task scenario is extended to a follow-the-leader task considering environmental factors, and further extended algorithm are proposed. Simulation comparison results with similar methods demonstrate the effectiveness of the proposed method in eliminating the initial arm shape dependence and improving the solution efficiency and accuracy. The experimental results further demonstrate that the method based on improved two-layer geometric iteration can be used for motion planning task of a continuum robot with a floating base, under an average deviation of about 4 mm in the end position, an average orientation deviation of no more than 1 degree, and the reduction of average number of iterations and time cost is 127.4 iterations and 72.6 ms compared with similar methods, respectively.
A First-order Generative Bilevel Optimization Framework for Diffusion Models
Feb 12, 2025Diffusion models, which iteratively denoise data samples to synthesize high-quality outputs, have achieved empirical success across domains. However, optimizing these models for downstream tasks often involves nested bilevel structures, such as tuning hyperparameters for fine-tuning tasks or noise schedules in training dynamics, where traditional bilevel methods fail due to the infinite-dimensional probability space and prohibitive sampling costs. We formalize this challenge as a generative bilevel optimization problem and address two key scenarios: (1) fine-tuning pre-trained models via an inference-only lower-level solver paired with a sample-efficient gradient estimator for the upper level, and (2) training diffusion models from scratch with noise schedule optimization by reparameterizing the lower-level problem and designing a computationally tractable gradient estimator. Our first-order bilevel framework overcomes the incompatibility of conventional bilevel methods with diffusion processes, offering theoretical grounding and computational practicality. Experiments demonstrate that our method outperforms existing fine-tuning and hyperparameter search baselines.
Pipeline Gradient-based Model Training on Analog In-memory Accelerators
Oct 19, 2024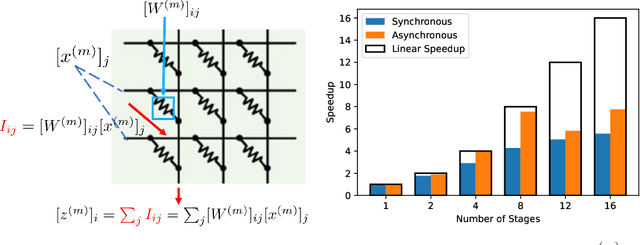

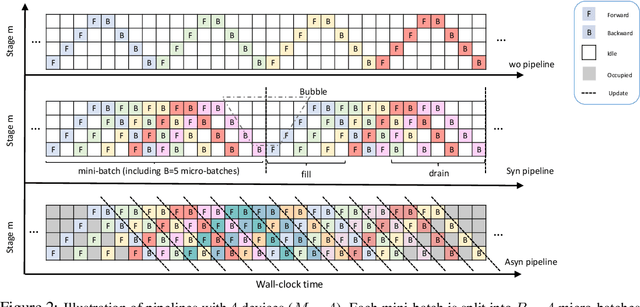
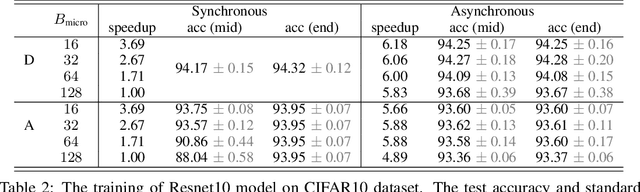
Aiming to accelerate the training of large deep neural models (DNN) in an energy-efficient way, an analog in-memory computing (AIMC) accelerator emerges as a solution with immense potential. In AIMC accelerators, trainable weights are kept in memory without the need to move from memory to processors during the training, reducing a bunch of overhead. However, although the in-memory feature enables efficient computation, it also constrains the use of data parallelism since copying weights from one AIMC to another is expensive. To enable parallel training using AIMC, we propose synchronous and asynchronous pipeline parallelism for AIMC accelerators inspired by the pipeline in digital domains. This paper provides a theoretical convergence guarantee for both synchronous and asynchronous pipelines in terms of both sampling and clock cycle complexity, which is non-trivial since the physical characteristic of AIMC accelerators leads to analog updates that suffer from asymmetric bias. The simulations of training DNN on real datasets verify the efficiency of pipeline training.
Unlocking Global Optimality in Bilevel Optimization: A Pilot Study
Aug 28, 2024Bilevel optimization has witnessed a resurgence of interest, driven by its critical role in trustworthy and efficient machine learning applications. Recent research has focused on proposing efficient methods with provable convergence guarantees. However, while many prior works have established convergence to stationary points or local minima, obtaining the global optimum of bilevel optimization remains an important yet open problem. The difficulty lies in the fact that unlike many prior non-convex single-level problems, this bilevel problem does not admit a ``benign" landscape, and may indeed have multiple spurious local solutions. Nevertheless, attaining the global optimality is indispensable for ensuring reliability, safety, and cost-effectiveness, particularly in high-stakes engineering applications that rely on bilevel optimization. In this paper, we first explore the challenges of establishing a global convergence theory for bilevel optimization, and present two sufficient conditions for global convergence. We provide algorithm-specific proofs to rigorously substantiate these sufficient conditions along the optimization trajectory, focusing on two specific bilevel learning scenarios: representation learning and data hypercleaning (a.k.a. reweighting). Experiments corroborate the theoretical findings, demonstrating convergence to global minimum in both cases.
A Primal-Dual-Assisted Penalty Approach to Bilevel Optimization with Coupled Constraints
Jun 14, 2024Interest in bilevel optimization has grown in recent years, partially due to its applications to tackle challenging machine-learning problems. Several exciting recent works have been centered around developing efficient gradient-based algorithms that can solve bilevel optimization problems with provable guarantees. However, the existing literature mainly focuses on bilevel problems either without constraints, or featuring only simple constraints that do not couple variables across the upper and lower levels, excluding a range of complex applications. Our paper studies this challenging but less explored scenario and develops a (fully) first-order algorithm, which we term BLOCC, to tackle BiLevel Optimization problems with Coupled Constraints. We establish rigorous convergence theory for the proposed algorithm and demonstrate its effectiveness on two well-known real-world applications - hyperparameter selection in support vector machine (SVM) and infrastructure planning in transportation networks using the real data from the city of Seville.
A Generalized Alternating Method for Bilevel Learning under the Polyak-Łojasiewicz Condition
Jun 06, 2023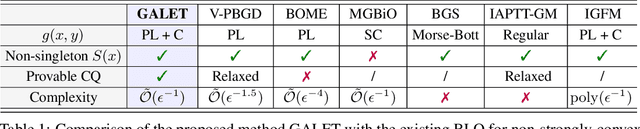
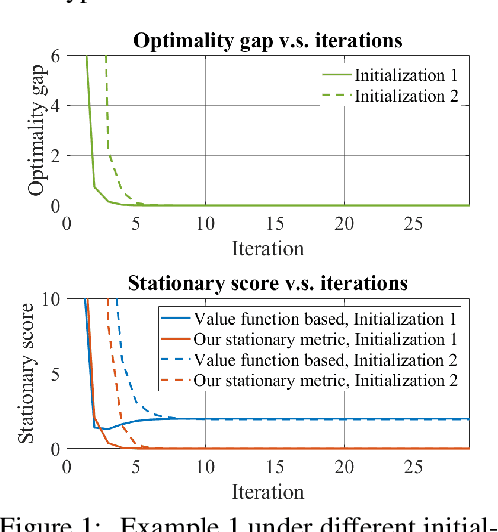
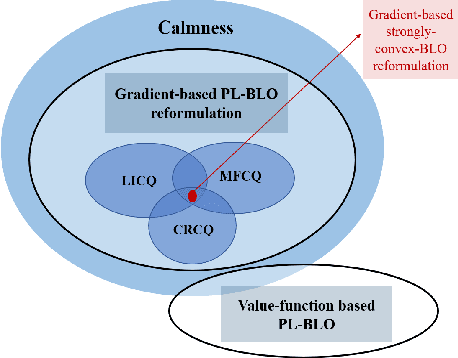

Bilevel optimization has recently regained interest owing to its applications in emerging machine learning fields such as hyperparameter optimization, meta-learning, and reinforcement learning. Recent results have shown that simple alternating (implicit) gradient-based algorithms can achieve the same convergence rate of single-level gradient descent (GD) for bilevel problems with a strongly convex lower-level objective. However, it remains unclear whether this result can be generalized to bilevel problems beyond this basic setting. In this paper, we propose a Generalized ALternating mEthod for bilevel opTimization (GALET) with a nonconvex lower-level objective that satisfies the Polyak-{\L}ojasiewicz (PL) condition. We first introduce a stationary metric for the considered bilevel problems, which generalizes the existing metric. We then establish that GALET achieves an $\epsilon$-stationary metric for the considered problem within $\tilde{\cal O}(\epsilon^{-1})$ iterations, which matches the iteration complexity of GD for smooth nonconvex problems.
Alternating Implicit Projected SGD and Its Efficient Variants for Equality-constrained Bilevel Optimization
Nov 14, 2022Stochastic bilevel optimization, which captures the inherent nested structure of machine learning problems, is gaining popularity in many recent applications. Existing works on bilevel optimization mostly consider either unconstrained problems or constrained upper-level problems. This paper considers the stochastic bilevel optimization problems with equality constraints both in the upper and lower levels. By leveraging the special structure of the equality constraints problem, the paper first presents an alternating implicit projected SGD approach and establishes the $\tilde{\cal O}(\epsilon^{-2})$ sample complexity that matches the state-of-the-art complexity of ALSET \citep{chen2021closing} for unconstrained bilevel problems. To further save the cost of projection, the paper presents two alternating implicit projection-efficient SGD approaches, where one algorithm enjoys the $\tilde{\cal O}(\epsilon^{-2}/T)$ upper-level and ${\cal O}(\epsilon^{-1.5}/T^{\frac{3}{4}})$ lower-level projection complexity with ${\cal O}(T)$ lower-level batch size, and the other one enjoys $\tilde{\cal O}(\epsilon^{-1.5})$ upper-level and lower-level projection complexity with ${\cal O}(1)$ batch size. Application to federated bilevel optimization has been presented to showcase the empirical performance of our algorithms. Our results demonstrate that equality-constrained bilevel optimization with strongly-convex lower-level problems can be solved as efficiently as stochastic single-level optimization problems.