 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Evaluation framework of Alignment Techniques for LLMs
Aug 13, 2025As Large Language Models (LLMs) become increasingly integrated into real-world applications, ensuring their outputs align with human values and safety standards has become critical. The field has developed diverse alignment approaches including traditional fine-tuning methods (RLHF, instruction tuning), post-hoc correction systems, and inference-time interventions, each with distinct advantages and limitations. However, the lack of unified evaluation frameworks makes it difficult to systematically compare these paradigms and guide deployment decisions. This paper introduces a multi-dimensional evaluation of alignment techniques for LLMs, a comprehensive evaluation framework that provides a systematic comparison across all major alignment paradigms. Our framework assesses methods along four key dimensions: alignment detection, alignment quality, computational efficiency, and robustness. Through experiments across diverse base models and alignment strategies, we demonstrate the utility of our framework in identifying strengths and limitations of current state-of-the-art models, providing valuable insights for future research directions.
Out-of-Distribution Detection using Synthetic Data Generation
Feb 05, 2025Distinguishing in- and out-of-distribution (OOD) inputs is crucial for reliable deployment of classification systems. However, OOD data is typically unavailable or difficult to collect, posing a significant challenge for accurate OOD detection. In this work, we present a method that harnesses the generative capabilities of Large Language Models (LLMs) to create high-quality synthetic OOD proxies, eliminating the dependency on any external OOD data source. We study the efficacy of our method on classical text classification tasks such as toxicity detection and sentiment classification as well as classification tasks arising in LLM development and deployment, such as training a reward model for RLHF and detecting misaligned generations. Extensive experiments on nine InD-OOD dataset pairs and various model sizes show that our approach dramatically lowers false positive rates (achieving a perfect zero in some cases) while maintaining high accuracy on in-distribution tasks, outperforming baseline methods by a significant margin.
Leveraging Large Language Models for Wireless Symbol Detection via In-Context Learning
Aug 28, 2024
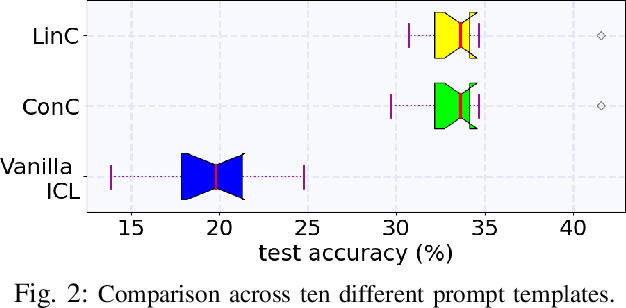
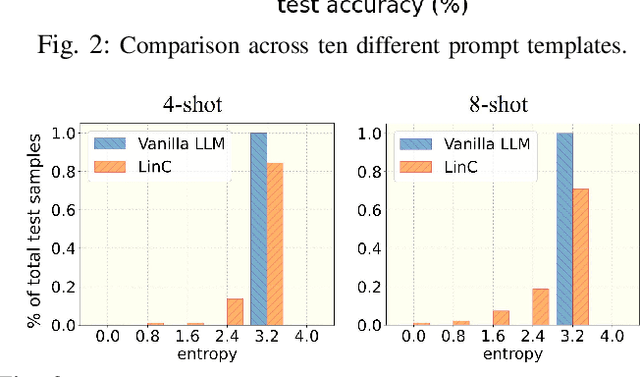
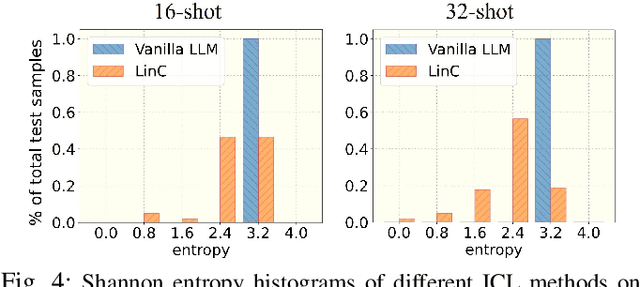
Deep neural networks (DNNs) have made significant strides in tackling challenging tasks in wireless systems, especially when an accurate wireless model is not available. However, when available data is limited, traditional DNNs often yield subpar results due to underfitting. At the same time, large language models (LLMs) exemplified by GPT-3, have remarkably showcased their capabilities across a broad range of natural language processing tasks. But whether and how LLMs can benefit challenging non-language tasks in wireless systems is unexplored. In this work, we propose to leverage the in-context learning ability (a.k.a. prompting) of LLMs to solve wireless tasks in the low data regime without any training or fine-tuning, unlike DNNs which require training. We further demonstrate that the performance of LLMs varies significantly when employed with different prompt templates. To solve this issue, we employ the latest LLM calibration methods. Our results reveal that using LLMs via ICL methods generally outperforms traditional DNNs on the symbol demodulation task and yields highly confident predictions when coupled with calibration techniques.
Enhancing In-context Learning via Linear Probe Calibration
Jan 22, 2024In-context learning (ICL) is a new paradigm for natural language processing that utilizes Generative Pre-trained Transformer (GPT)-like models. This approach uses prompts that include in-context demonstrations to generate the corresponding output for a new query input. However, applying ICL in real cases does not scale with the number of samples, and lacks robustness to different prompt templates and demonstration permutations. In this paper, we first show that GPT-like models using ICL result in unreliable predictions based on a new metric based on Shannon entropy. Then, to solve this problem, we propose a new technique called the Linear Probe Calibration (LinC), a method that calibrates the model's output probabilities, resulting in reliable predictions and improved performance, while requiring only minimal additional samples (as few as five labeled data samples). LinC significantly enhances the ICL test performance of GPT models on various benchmark datasets, with an average improvement of up to 21%, and up to a 50% improvement in some cases, and significantly boosts the performance of PEFT methods, especially in the low resource regime. Moreover, LinC achieves lower expected calibration error, and is highly robust to varying label proportions, prompt templates, and demonstration permutations. Our code is available at \url{https://github.com/mominabbass/LinC}.
Sharp-MAML: Sharpness-Aware Model-Agnostic Meta Learning
Jun 10, 2022



Model-agnostic meta learning (MAML) is currently one of the dominating approaches for few-shot meta-learning. Albeit its effectiveness, the optimization of MAML can be challenging due to the innate bilevel problem structure. Specifically, the loss landscape of MAML is much more complex with possibly more saddle points and local minimizers than its empirical risk minimization counterpart. To address this challenge, we leverage the recently invented sharpness-aware minimization and develop a sharpness-aware MAML approach that we term Sharp-MAML. We empirically demonstrate that Sharp-MAML and its computation-efficient variant can outperform popular existing MAML baselines (e.g., $+12\%$ accuracy on Mini-Imagenet). We complement the empirical study with the convergence rate analysis and the generalization bound of Sharp-MAML. To the best of our knowledge, this is the first empirical and theoretical study on sharpness-aware minimization in the context of bilevel learning. The code is available at https://github.com/mominabbass/Sharp-MAML.