 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unlearning Mirage: A Dynamic Framework for Evaluating LLM Unlearning
Mar 11, 2026Unlearning in Large Language Models (LLMs) aims to enhance safety, mitigate biases, and comply with legal mandates, such as the right to be forgotten. However, existing unlearning methods are brittle: minor query modifications, such as multi-hop reasoning and entity aliasing, can recover supposedly forgotten information. As a result, current evaluation metrics often create an illusion of effectiveness, failing to detect these vulnerabilities due to reliance on static, unstructured benchmarks. We propose a dynamic framework that stress tests unlearning robustness using complex structured queries. Our approach first elicits knowledge from the target model (pre-unlearning) and constructs targeted probes, ranging from simple queries to multi-hop chains, allowing precise control over query difficulty. Our experiments show that the framework (1) shows comparable coverage to existing benchmarks by automatically generating semantically equivalent Q&A probes, (2) aligns with prior evaluations, and (3) uncovers new unlearning failures missed by other benchmarks, particularly in multi-hop settings. Furthermore, activation analyses show that single-hop queries typically follow dominant computation pathways, which are more likely to be disrupted by unlearning methods. In contrast, multi-hop queries tend to use alternative pathways that often remain intact, explaining the brittleness of unlearning techniques in multi-hop settings. Our framework enables practical and scalable evaluation of unlearning methods without the need for manual construction of forget test sets, enabling easier adoption for real-world applications. We release the pip package and the code at https://sites.google.com/view/unlearningmirage/home.
In-Context Probing for Membership Inference in Fine-Tuned Language Models
Dec 21, 2025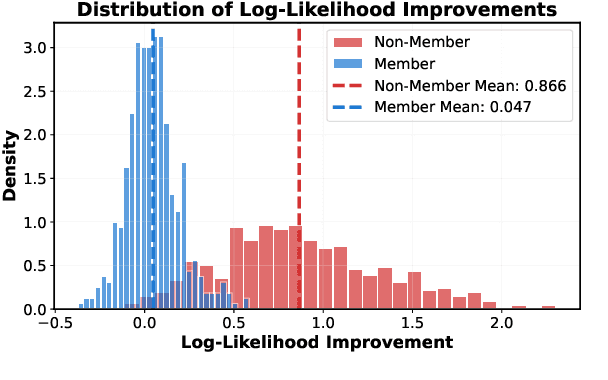
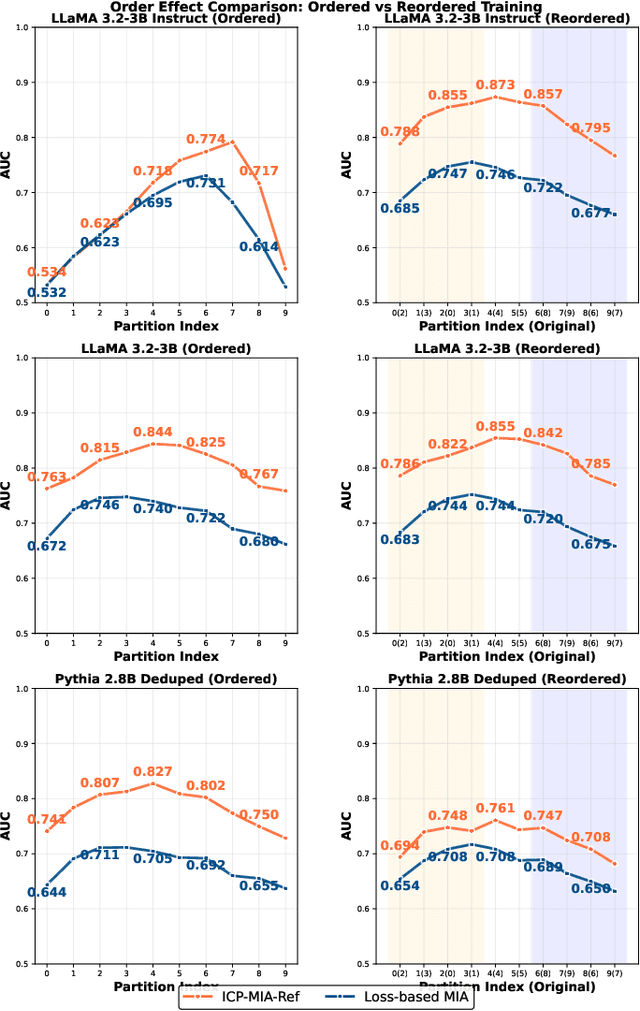
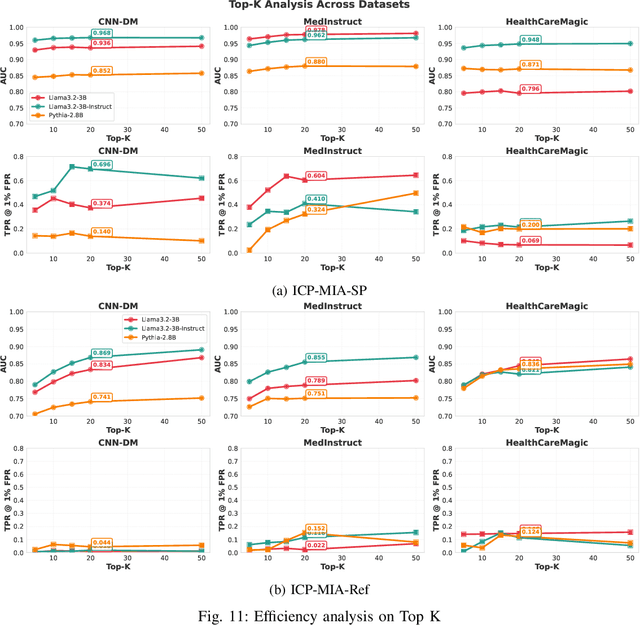
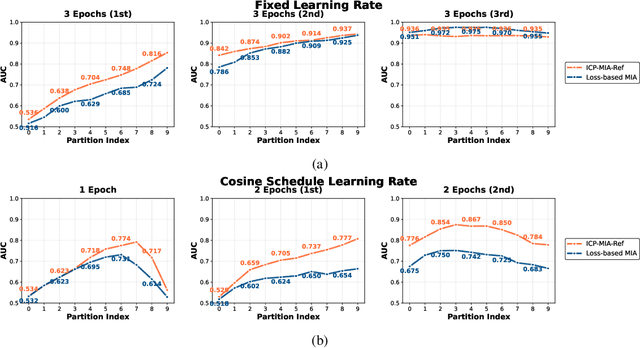
Membership inference attacks (MIAs) pose a critical privacy threat to fine-tuned large language models (LLMs), especially when models are adapted to domain-specific tasks using sensitive data. While prior black-box MIA techniques rely on confidence scores or token likelihoods, these signals are often entangled with a sample's intrinsic properties - such as content difficulty or rarity - leading to poor generalization and low signal-to-noise ratios. In this paper, we propose ICP-MIA, a novel MIA framework grounded in the theory of training dynamics, particularly the phenomenon of diminishing returns during optimization. We introduce the Optimization Gap as a fundamental signal of membership: at convergence, member samples exhibit minimal remaining loss-reduction potential, while non-members retain significant potential for further optimization. To estimate this gap in a black-box setting, we propose In-Context Probing (ICP), a training-free method that simulates fine-tuning-like behavior via strategically constructed input contexts. We propose two probing strategies: reference-data-based (using semantically similar public samples) and self-perturbation (via masking or generation). Experiments on three tasks and multiple LLMs show that ICP-MIA significantly outperforms prior black-box MIAs, particularly at low false positive rates. We further analyze how reference data alignment, model type, PEFT configurations, and training schedules affect attack effectiveness. Our findings establish ICP-MIA as a practical and theoretically grounded framework for auditing privacy risks in deployed LLMs.
Mitigating Modality Imbalance in Multi-modal Learning via Multi-objective Optimization
Nov 10, 2025Multi-modal learning (MML) aims to integrate information from multiple modalities, which is expected to lead to superior performance over single-modality learning. However, recent studies have shown that MML can underperform, even compared to single-modality approaches, due to imbalanced learning across modalities. Methods have been proposed to alleviate this imbalance issue using different heuristics, which often lead to computationally intensive subroutines. In this paper, we reformulate the MML problem as a multi-objective optimization (MOO) problem that overcomes the imbalanced learning issue among modalities and propose a gradient-based algorithm to solve the modified MML problem. We provide convergence guarantees for the proposed method, and empirical evaluations on popular MML benchmarks showcasing the improved performance of the proposed method over existing balanced MML and MOO baselines, with up to ~20x reduction in subroutine computation time. Our code is available at https://github.com/heshandevaka/MIMO.
Reasoning Model Unlearning: Forgetting Traces, Not Just Answers, While Preserving Reasoning Skills
Jun 15, 2025Recent advances in large reasoning models (LRMs) have enabled strong chain-of-thought (CoT) generation through test-time computation. While these multi-step reasoning capabilities represent a major milestone in language model performance, they also introduce new safety risks. In this work, we present the first systematic study to revisit the problem of machine unlearning in the context of LRMs. Machine unlearning refers to the process of removing the influence of sensitive, harmful, or undesired data or knowledge from a trained model without full retraining. We show that conventional unlearning algorithms, originally designed for non-reasoning models, are inadequate for LRMs. In particular, even when final answers are successfully erased, sensitive information often persists within the intermediate reasoning steps, i.e., CoT trajectories. To address this challenge, we extend conventional unlearning and propose Reasoning-aware Representation Misdirection for Unlearning ($R^2MU$), a novel method that effectively suppresses sensitive reasoning traces and prevents the generation of associated final answers, while preserving the model's reasoning ability. Our experiments demonstrate that $R^2MU$ significantly reduces sensitive information leakage within reasoning traces and achieves strong performance across both safety and reasoning benchmarks, evaluated on state-of-the-art models such as DeepSeek-R1-Distill-LLaMA-8B and DeepSeek-R1-Distill-Qwen-14B.
EPiC: Towards Lossless Speedup for Reasoning Training through Edge-Preserving CoT Condensation
Jun 04, 2025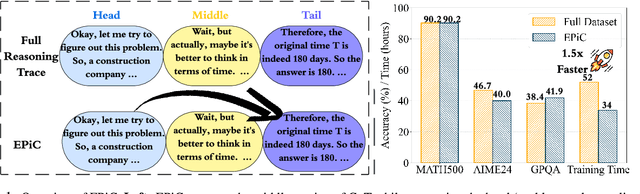
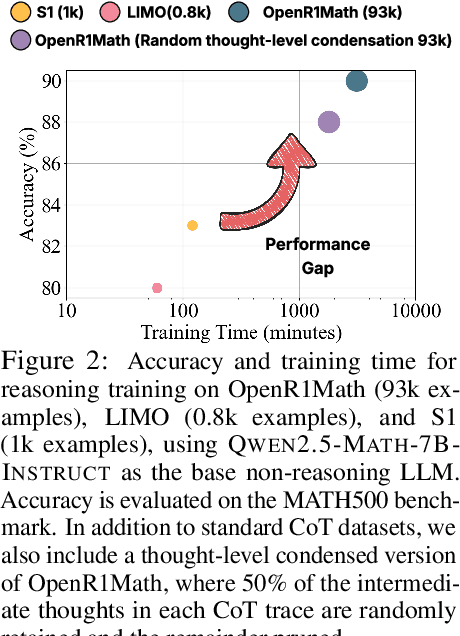

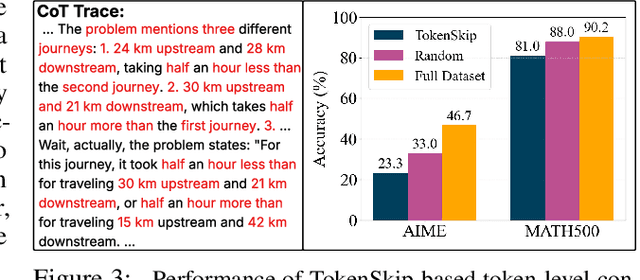
Large language models (LLMs) have shown remarkable reasoning capabilities when trained with chain-of-thought (CoT) supervision. However, the long and verbose CoT traces, especially those distilled from large reasoning models (LRMs) such as DeepSeek-R1, significantly increase training costs during the distillation process, where a non-reasoning base model is taught to replicate the reasoning behavior of an LRM. In this work, we study the problem of CoT condensation for resource-efficient reasoning training, aimed at pruning intermediate reasoning steps (i.e., thoughts) in CoT traces, enabling supervised model training on length-reduced CoT data while preserving both answer accuracy and the model's ability to generate coherent reasoning. Our rationale is that CoT traces typically follow a three-stage structure: problem understanding, exploration, and solution convergence. Through empirical analysis, we find that retaining the structure of the reasoning trace, especially the early stage of problem understanding (rich in reflective cues) and the final stage of solution convergence, is sufficient to achieve lossless reasoning supervision. To this end, we propose an Edge-Preserving Condensation method, EPiC, which selectively retains only the initial and final segments of each CoT trace while discarding the middle portion. This design draws an analogy to preserving the "edge" of a reasoning trajectory, capturing both the initial problem framing and the final answer synthesis, to maintain logical continuity. Experiments across multiple model families (Qwen and LLaMA) and benchmarks show that EPiC reduces training time by over 34% while achieving lossless reasoning accuracy on MATH500, comparable to full CoT supervision. To the best of our knowledge, this is the first study to explore thought-level CoT condensation for efficient reasoning model distillation.
MAP: Multi-Human-Value Alignment Palette
Oct 24, 2024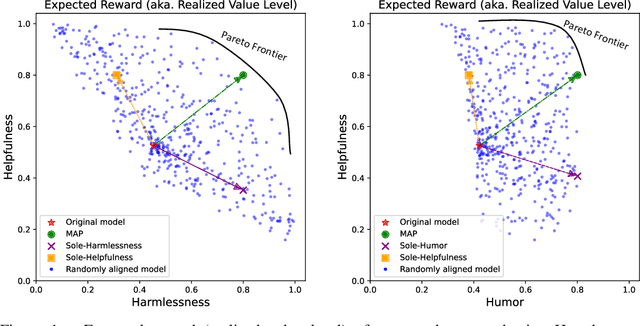
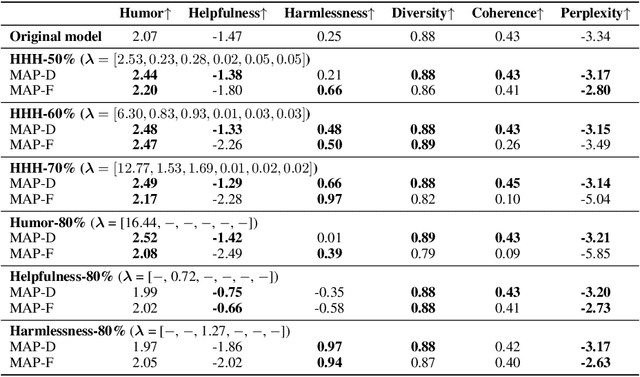
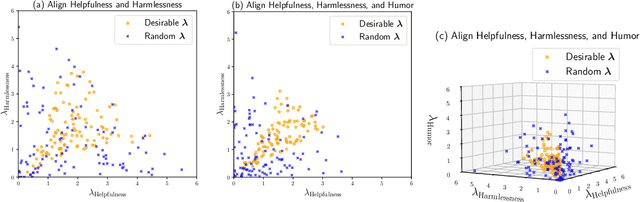
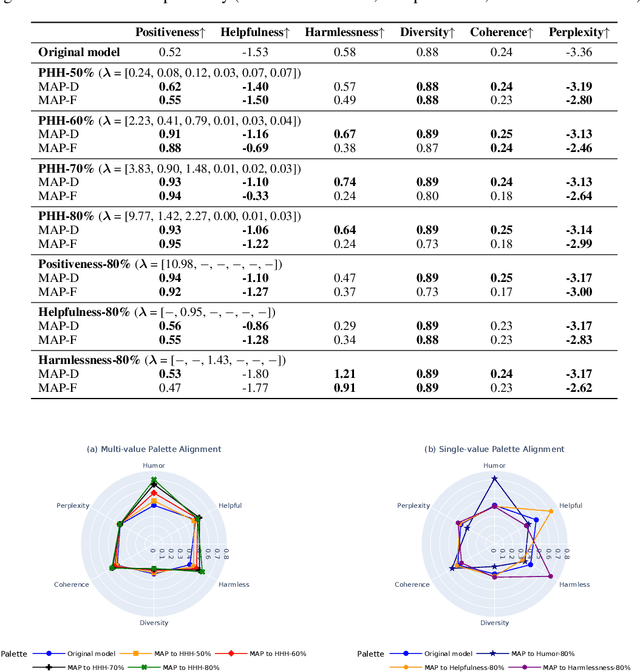
Ensuring that generative AI systems align with human values is essential but challenging, especially when considering multiple human values and their potential trade-offs. Since human values can be personalized and dynamically change over time, the desirable levels of value alignment vary across different ethnic groups, industry sectors, and user cohorts. Within existing frameworks, it is hard to define human values and align AI systems accordingly across different directions simultaneously, such as harmlessness, helpfulness, and positiveness. To address this, we develop a novel, first-principle approach called Multi-Human-Value Alignment Palette (MAP), which navigates the alignment across multiple human values in a structured and reliable way. MAP formulates the alignment problem as an optimization task with user-defined constraints, which define human value targets. It can be efficiently solved via a primal-dual approach, which determines whether a user-defined alignment target is achievable and how to achieve it. We conduct a detailed theoretical analysis of MAP by quantifying the trade-offs between values, the sensitivity to constraints, the fundamental connection between multi-value alignment and sequential alignment, and proving that linear weighted rewards are sufficient for multi-value alignment. Extensive experiments demonstrate MAP's ability to align multiple values in a principled manner while delivering strong empirical performance across various tasks.
WAGLE: Strategic Weight Attribution for Effective and Modular Unlearning in Large Language Models
Oct 23, 2024The need for effective unlearning mechanisms in large language models (LLMs) is increasingly urgent, driven by the necessity to adhere to data regulations and foster ethical generative AI practices. Despite growing interest of LLM unlearning, much of the existing research has focused on varied unlearning method designs to boost effectiveness and efficiency. However, the inherent relationship between model weights and LLM unlearning has not been extensively examined. In this paper, we systematically explore how model weights interact with unlearning processes in LLMs and we design the weight attribution-guided LLM unlearning method, WAGLE, which unveils the interconnections between 'influence' of weights and 'influence' of data to forget and retain in LLM generation. By strategically guiding the LLM unlearning across different types of unlearning methods and tasks, WAGLE can erase the undesired content, while maintaining the performance of the original tasks. We refer to the weight attribution-guided LLM unlearning method as WAGLE, which unveils the interconnections between 'influence' of weights and 'influence' of data to forget and retain in LLM generation. Our extensive experiments show that WAGLE boosts unlearning performance across a range of LLM unlearning methods such as gradient difference and (negative) preference optimization, applications such as fictitious unlearning, malicious use prevention, and copyrighted information removal, and models including Zephyr-7b-beta and Llama2-7b. To the best of our knowledge, our work offers the first principled method for attributing and pinpointing the influential weights in enhancing LLM unlearning. It stands in contrast to previous methods that lack weight attribution and simpler weight attribution techniques.
Mitigating Forgetting in LLM Supervised Fine-Tuning and Preference Learning
Oct 20, 2024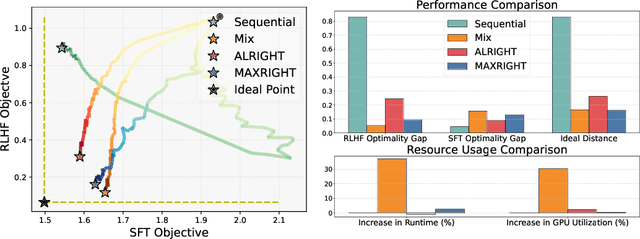
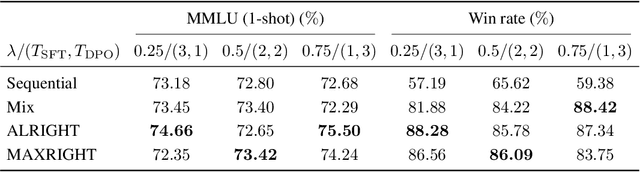
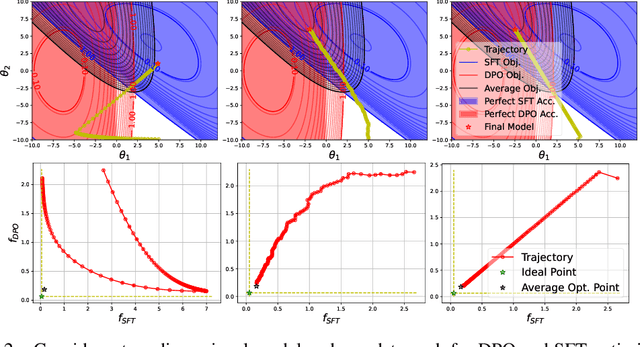
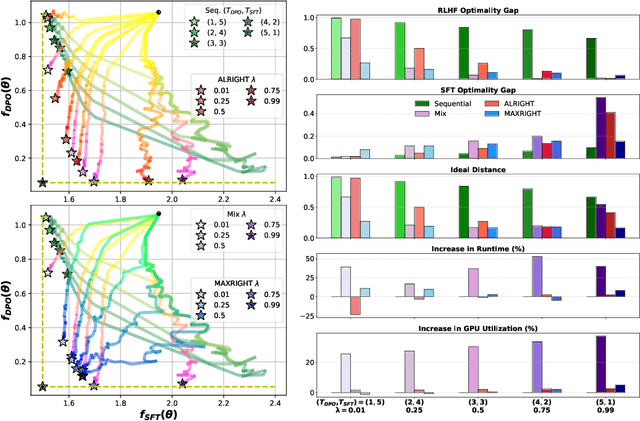
Post-training of pre-trained LLMs, which typically consists of the supervised fine-tuning (SFT) stage and the preference learning (RLHF or DPO) stage, is crucial to effective and safe LLM applications. The widely adopted approach in post-training popular open-source LLMs is to sequentially perform SFT and RLHF/DPO. However, sequential training is sub-optimal in terms of SFT and RLHF/DPO trade-off: the LLM gradually forgets about the first stage's training when undergoing the second stage's training. We theoretically prove the sub-optimality of sequential post-training. Furthermore, we propose a practical joint post-training framework with theoretical convergence guarantees and empirically outperforms sequential post-training framework, while having similar computational cost. Our code is available at https://github.com/heshandevaka/XRIGHT.
Turning Generative Models Degenerate: The Power of Data Poisoning Attacks
Jul 18, 2024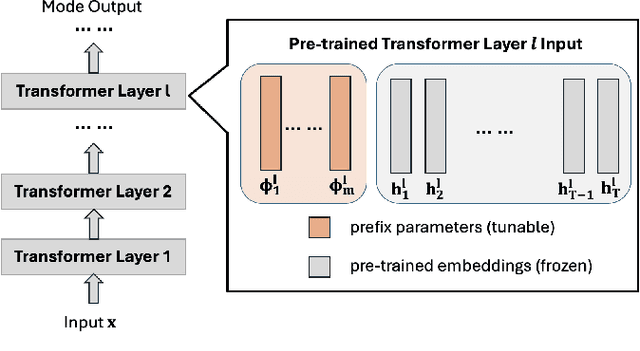
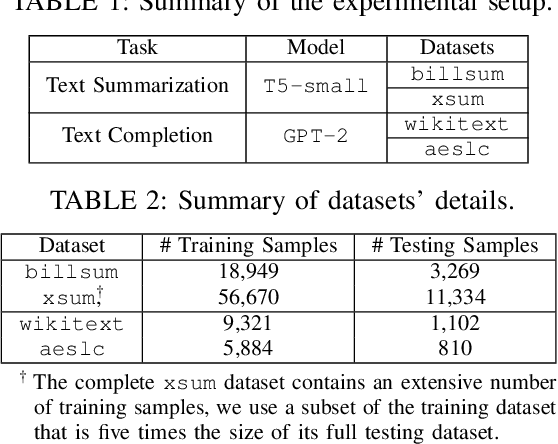
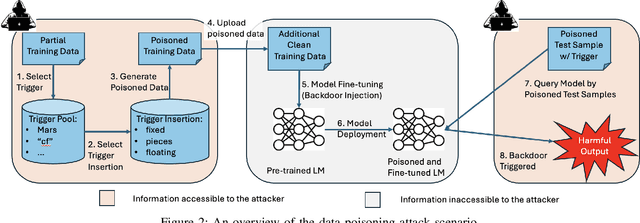

The increasing use of large language models (LLMs) trained by third parties raises significant security concerns. In particular, malicious actors can introduce backdoors through poisoning attacks to generate undesirable outputs. While such attacks have been extensively studied in image domains and classification tasks, they remain underexplored for natural language generation (NLG) tasks. To address this gap, we conduct an investigation of various poisoning techniques targeting the LLM's fine-tuning phase via prefix-tuning, a Parameter Efficient Fine-Tuning (PEFT) method. We assess their effectiveness across two generative tasks: text summarization and text completion; and we also introduce new metrics to quantify the success and stealthiness of such NLG poisoning attacks. Through our experiments, we find that the prefix-tuning hyperparameters and trigger designs are the most crucial factors to influence attack success and stealthiness. Moreover, we demonstrate that existing popular defenses are ineffective against our poisoning attacks. Our study presents the first systematic approach to understanding poisoning attacks targeting NLG tasks during fine-tuning via PEFT across a wide range of triggers and attack settings. We hope our findings will aid the AI security community in developing effective defenses against such threats.
Split, Unlearn, Merge: Leveraging Data Attributes for More Effective Unlearning in LLMs
Jun 17, 2024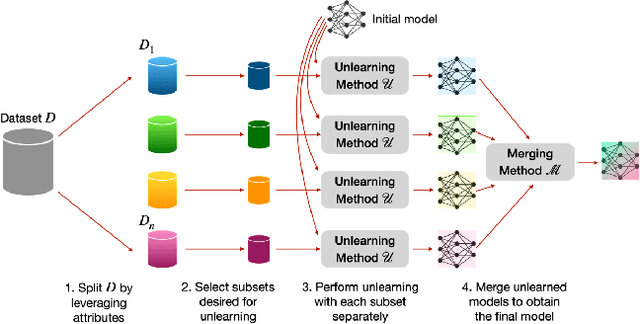
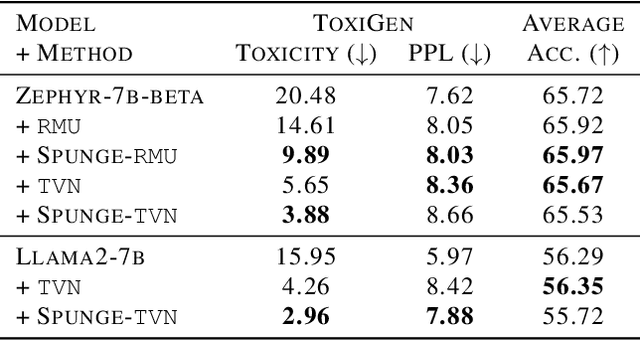
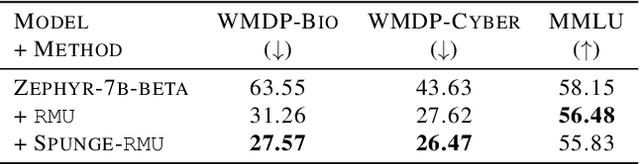
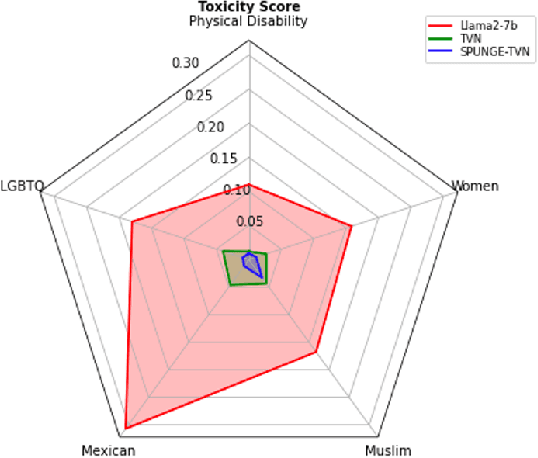
Large language models (LLMs) have shown to pose social and ethical risks such as generating toxic language or facilitating malicious use of hazardous knowledge. Machine unlearning is a promising approach to improve LLM safety by directly removing harmful behaviors and knowledge. In this paper, we propose "SPlit, UNlearn, MerGE" (SPUNGE), a framework that can be used with any unlearning method to amplify its effectiveness. SPUNGE leverages data attributes during unlearning by splitting unlearning data into subsets based on specific attribute values, unlearning each subset separately, and merging the unlearned models. We empirically demonstrate that SPUNGE significantly improves the performance of two recent unlearning methods on state-of-the-art LLMs while maintaining their general capabilities on standard academic benchmarks.