 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbe Pruning: Accelerating LLMs through Dynamic Pruning via Model-Probing
Feb 21, 2025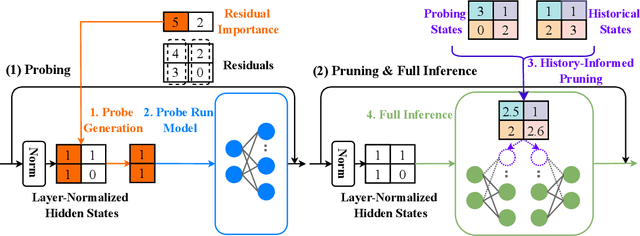


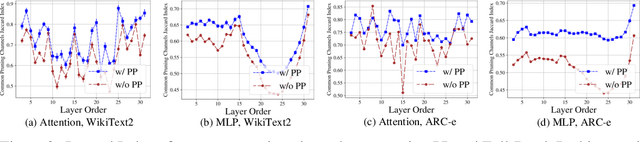
We introduce Probe Pruning (PP), a novel framework for online, dynamic, structured pruning of Large Language Models (LLMs) applied in a batch-wise manner. PP leverages the insight that not all samples and tokens contribute equally to the model's output, and probing a small portion of each batch effectively identifies crucial weights, enabling tailored dynamic pruning for different batches. It comprises three main stages: probing, history-informed pruning, and full inference. In the probing stage, PP selects a small yet crucial set of hidden states, based on residual importance, to run a few model layers ahead. During the history-informed pruning stage, PP strategically integrates the probing states with historical states. Subsequently, it structurally prunes weights based on the integrated states and the PP importance score, a metric developed specifically to assess the importance of each weight channel in maintaining performance. In the final stage, full inference is conducted on the remaining weights. A major advantage of PP is its compatibility with existing models, as it operates without requiring additional neural network modules or fine-tuning. Comprehensive evaluations of PP on LLaMA-2/3 and OPT models reveal that even minimal probing-using just 1.5% of FLOPs-can substantially enhance the efficiency of structured pruning of LLMs. For instance, when evaluated on LLaMA-2-7B with WikiText2, PP achieves a 2.56 times lower ratio of performance degradation per unit of runtime reduction compared to the state-of-the-art method at a 40% pruning ratio. Our code is available at https://github.com/Qi-Le1/Probe_Pruning.
MAP: Multi-Human-Value Alignment Palette
Oct 24, 2024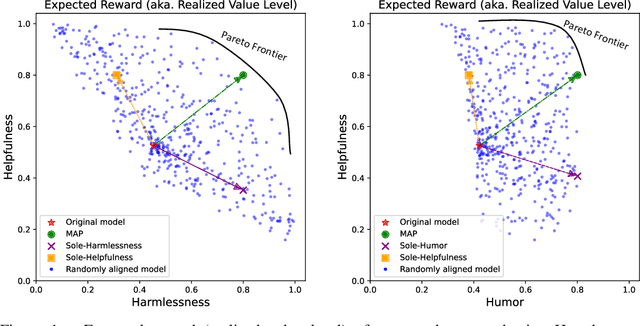
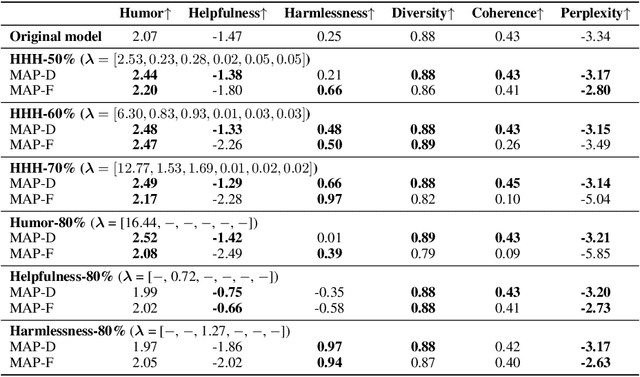
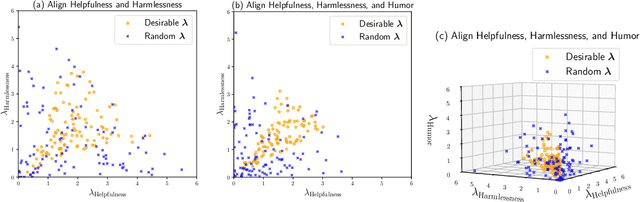
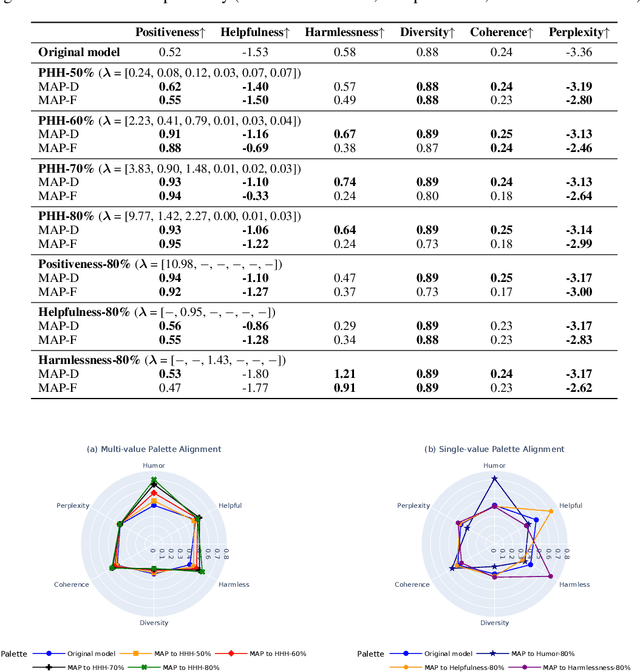
Ensuring that generative AI systems align with human values is essential but challenging, especially when considering multiple human values and their potential trade-offs. Since human values can be personalized and dynamically change over time, the desirable levels of value alignment vary across different ethnic groups, industry sectors, and user cohorts. Within existing frameworks, it is hard to define human values and align AI systems accordingly across different directions simultaneously, such as harmlessness, helpfulness, and positiveness. To address this, we develop a novel, first-principle approach called Multi-Human-Value Alignment Palette (MAP), which navigates the alignment across multiple human values in a structured and reliable way. MAP formulates the alignment problem as an optimization task with user-defined constraints, which define human value targets. It can be efficiently solved via a primal-dual approach, which determines whether a user-defined alignment target is achievable and how to achieve it. We conduct a detailed theoretical analysis of MAP by quantifying the trade-offs between values, the sensitivity to constraints, the fundamental connection between multi-value alignment and sequential alignment, and proving that linear weighted rewards are sufficient for multi-value alignment. Extensive experiments demonstrate MAP's ability to align multiple values in a principled manner while delivering strong empirical performance across various tasks.
DynamicFL: Federated Learning with Dynamic Communication Resource Allocation
Sep 08, 2024



Federated Learning (FL) is a collaborative machine learning framework that allows multiple users to train models utilizing their local data in a distributed manner. However, considerable statistical heterogeneity in local data across devices often leads to suboptimal model performance compared with independently and identically distributed (IID) data scenarios. In this paper, we introduce DynamicFL, a new FL framework that investigates the trade-offs between global model performance and communication costs for two widely adopted FL methods: Federated Stochastic Gradient Descent (FedSGD) and Federated Averaging (FedAvg). Our approach allocates diverse communication resources to clients based on their data statistical heterogeneity, considering communication resource constraints, and attains substantial performance enhancements compared to uniform communication resource allocation. Notably, our method bridges the gap between FedSGD and FedAvg, providing a flexible framework leveraging communication heterogeneity to address statistical heterogeneity in FL. Through extensive experiments, we demonstrate that DynamicFL surpasses current state-of-the-art methods with up to a 10% increase in model accuracy, demonstrating its adaptability and effectiveness in tackling data statistical heterogeneity challenges.
Robust Score-Based Quickest Change Detection
Jul 15, 2024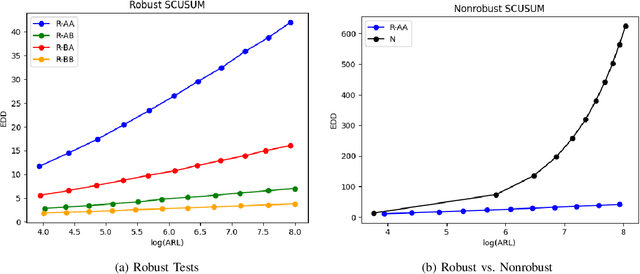
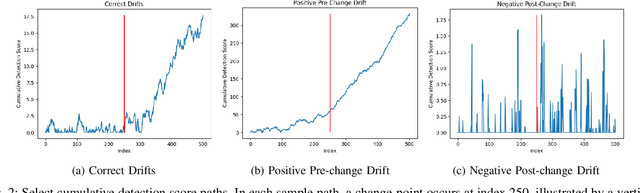
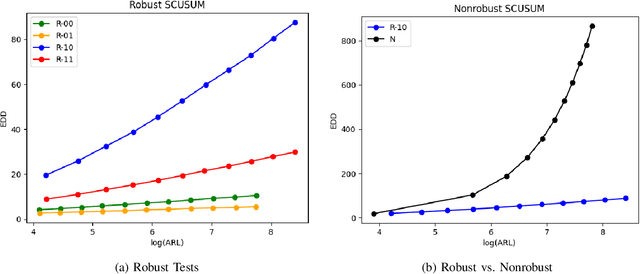
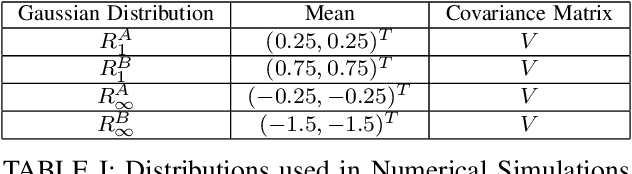
Methods in the field of quickest change detection rapidly detect in real-time a change in the data-generating distribution of an online data stream. Existing methods have been able to detect this change point when the densities of the pre- and post-change distributions are known. Recent work has extended these results to the case where the pre- and post-change distributions are known only by their score functions. This work considers the case where the pre- and post-change score functions are known only to correspond to distributions in two disjoint sets. This work employs a pair of "least-favorable" distributions to robustify the existing score-based quickest change detection algorithm, the properties of which are studied. This paper calculates the least-favorable distributions for specific model classes and provides methods of estimating the least-favorable distributions for common constructions. Simulation results are provided demonstrating the performance of our robust change detection algorithm.
ESC: Efficient Speech Coding with Cross-Scale Residual Vector Quantized Transformers
Apr 30, 2024



Existing neural audio codecs usually sacrifice computational complexity for audio quality. They build the feature transformation layers mainly on convolutional blocks, which are not inherently appropriate for capturing local redundancies of audio signals. As compensation, either adversarial losses from a discriminator or a large number of model parameters are required to improve the codec. To that end, we propose Efficient Speech Codec (ESC), a lightweight parameter-efficient codec laid on cross-scale residual vector quantization and transformers. Our model leverages mirrored hierarchical window-attention transformer blocks and performs step-wise decoding from coarse-to-fine feature representations. To enhance codebook utilization, we design a learning paradigm that involves a pre-training stage to assist with codec training. Extensive results show that ESC can achieve high audio quality with much lower complexity, which is a prospective alternative in place of existing codecs.
ColA: Collaborative Adaptation with Gradient Learning
Apr 22, 2024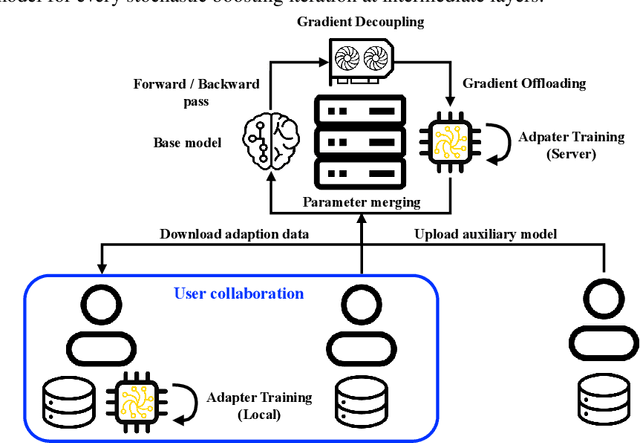
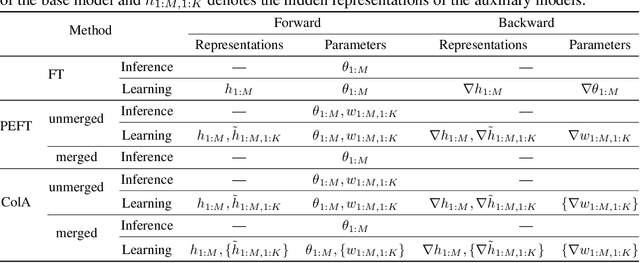
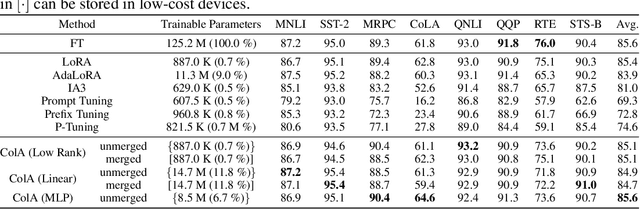
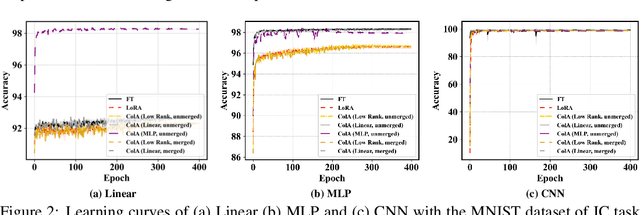
A primary function of back-propagation is to compute both the gradient of hidden representations and parameters for optimization with gradient descent. Training large models requires high computational costs due to their vast parameter sizes. While Parameter-Efficient Fine-Tuning (PEFT) methods aim to train smaller auxiliary models to save computational space, they still present computational overheads, especially in Fine-Tuning as a Service (FTaaS) for numerous users. We introduce Collaborative Adaptation (ColA) with Gradient Learning (GL), a parameter-free, model-agnostic fine-tuning approach that decouples the computation of the gradient of hidden representations and parameters. In comparison to PEFT methods, ColA facilitates more cost-effective FTaaS by offloading the computation of the gradient to low-cost devices. We also provide a theoretical analysis of ColA and experimentally demonstrate that ColA can perform on par or better than existing PEFT methods on various benchmarks.
Large Deviation Analysis of Score-based Hypothesis Testing
Feb 03, 2024Score-based statistical models play an important role in modern machine learning, statistics, and signal processing. For hypothesis testing, a score-based hypothesis test is proposed in \cite{wu2022score}. We analyze the performance of this score-based hypothesis testing procedure and derive upper bounds on the probabilities of its Type I and II errors. We prove that the exponents of our error bounds are asymptotically (in the number of samples) tight for the case of simple null and alternative hypotheses. We calculate these error exponents explicitly in specific cases and provide numerical studies for various other scenarios of interest.
Robust Quickest Change Detection for Unnormalized Models
Jun 08, 2023



Detecting an abrupt and persistent change in the underlying distribution of online data streams is an important problem in many applications. This paper proposes a new robust score-based algorithm called RSCUSUM, which can be applied to unnormalized models and addresses the issue of unknown post-change distributions. RSCUSUM replaces the Kullback-Leibler divergence with the Fisher divergence between pre- and post-change distributions for computational efficiency in unnormalized statistical models and introduces a notion of the ``least favorable'' distribution for robust change detection. The algorithm and its theoretical analysis are demonstrated through simulation studies.
Semi-Supervised Federated Learning for Keyword Spotting
May 09, 2023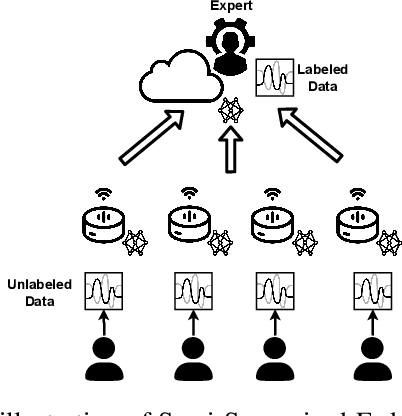
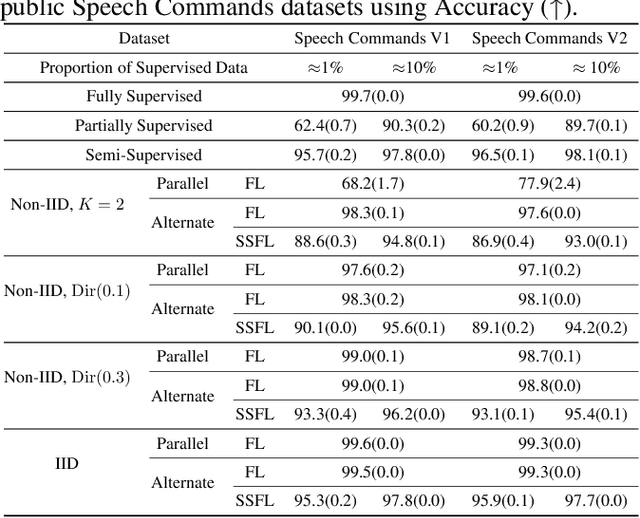
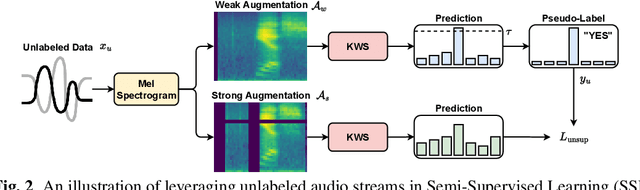
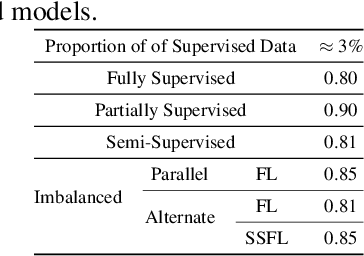
Keyword Spotting (KWS) is a critical aspect of audio-based applications on mobile devices and virtual assistants. Recent developments in Federated Learning (FL) have significantly expanded the ability to train machine learning models by utilizing the computational and private data resources of numerous distributed devices. However, existing FL methods typically require that devices possess accurate ground-truth labels, which can be both expensive and impractical when dealing with local audio data. In this study, we first demonstrate the effectiveness of Semi-Supervised Federated Learning (SSL) and FL for KWS. We then extend our investigation to Semi-Supervised Federated Learning (SSFL) for KWS, where devices possess completely unlabeled data, while the server has access to a small amount of labeled data. We perform numerical analyses using state-of-the-art SSL, FL, and SSFL techniques to demonstrate that the performance of KWS models can be significantly improved by leveraging the abundant unlabeled heterogeneous data available on devices.
Pruning Deep Neural Networks from a Sparsity Perspective
Feb 11, 2023In recent years, deep network pruning has attracted significant attention in order to enable the rapid deployment of AI into small devices with computation and memory constraints. Pruning is often achieved by dropping redundant weights, neurons, or layers of a deep network while attempting to retain a comparable test performance. Many deep pruning algorithms have been proposed with impressive empirical success. However, existing approaches lack a quantifiable measure to estimate the compressibility of a sub-network during each pruning iteration and thus may under-prune or over-prune the model. In this work, we propose PQ Index (PQI) to measure the potential compressibility of deep neural networks and use this to develop a Sparsity-informed Adaptive Pruning (SAP) algorithm. Our extensive experiments corroborate the hypothesis that for a generic pruning procedure, PQI decreases first when a large model is being effectively regularized and then increases when its compressibility reaches a limit that appears to correspond to the beginning of underfitting. Subsequently, PQI decreases again when the model collapse and significant deterioration in the performance of the model start to occur. Additionally, our experiments demonstrate that the proposed adaptive pruning algorithm with proper choice of hyper-parameters is superior to the iterative pruning algorithms such as the lottery ticket-based pruning methods, in terms of both compression efficiency and robustness.