 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Federated Learning for Keyword Spotting
Paper and Code
May 09, 2023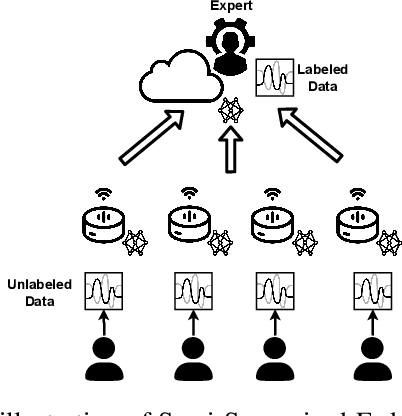
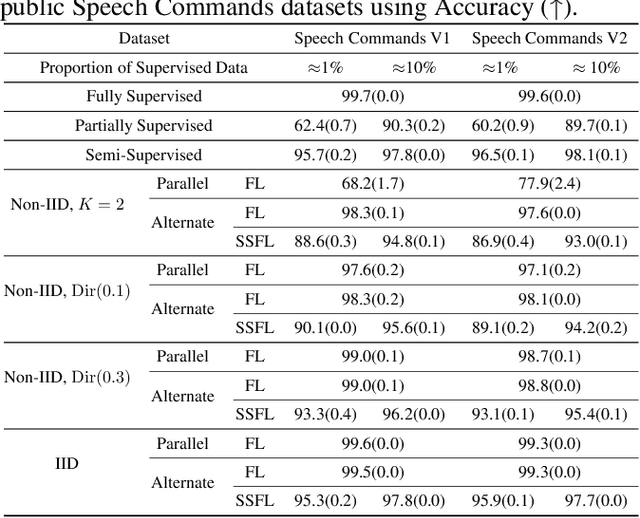
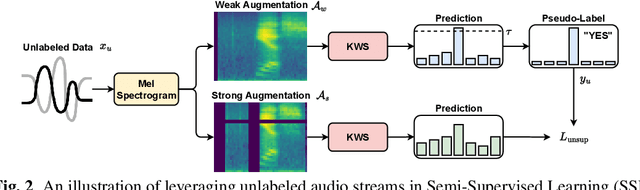
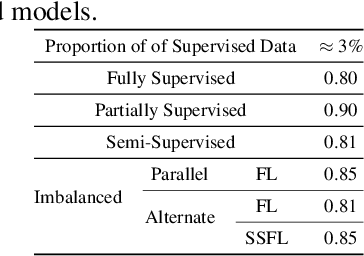
Keyword Spotting (KWS) is a critical aspect of audio-based applications on mobile devices and virtual assistants. Recent developments in Federated Learning (FL) have significantly expanded the ability to train machine learning models by utilizing the computational and private data resources of numerous distributed devices. However, existing FL methods typically require that devices possess accurate ground-truth labels, which can be both expensive and impractical when dealing with local audio data. In this study, we first demonstrate the effectiveness of Semi-Supervised Federated Learning (SSL) and FL for KWS. We then extend our investigation to Semi-Supervised Federated Learning (SSFL) for KWS, where devices possess completely unlabeled data, while the server has access to a small amount of labeled data. We perform numerical analyses using state-of-the-art SSL, FL, and SSFL techniques to demonstrate that the performance of KWS models can be significantly improved by leveraging the abundant unlabeled heterogeneous data available on devices.