 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Evaluation of Optimization Techniques for Long-Context Language Models
Aug 01, 2025Large language models (LLMs) excel across diverse natural language processing tasks but face resource demands and limited context windows. Although techniques like pruning, quantization, and token dropping can mitigate these issues, their efficacy in long-context scenarios and system evaluation remains underexplored. This paper systematically benchmarks these optimizations, characterizing memory usage, latency, and throughput, and studies how these methods impact the quality of text generation. We first analyze individual optimization methods for two LLM architectures supporting long context and then systematically evaluate combinations of these techniques to assess how this deeper analysis impacts performance metrics. We subsequently study the scalability of individual optimization methods on a larger variant with 70 billion-parameter model. Our novel insights reveal that naive combination inference optimization algorithms can adversely affect larger models due to compounded approximation errors, as compared to their smaller counterparts. Experiments show that relying solely on F1 obscures these effects by hiding precision-recall trade-offs in question answering tasks. By integrating system-level profiling with task-specific insights, this study helps LLM practitioners and researchers explore and balance efficiency, accuracy, and scalability across tasks and hardware configurations.
Demographic-aware fine-grained classification of pediatric wrist fractures
Jul 18, 2025Wrist pathologies are frequently observed, particularly among children who constitute the majority of fracture cases. However, diagnosing these conditions is time-consuming and requires specialized expertise. Computer vision presents a promising avenue, contingent upon the availability of extensive datasets, a notable challenge in medical imaging. Therefore, reliance solely on one modality, such as images, proves inadequate, especially in an era of diverse and plentiful data types. In this study, we employ a multifaceted approach to address the challenge of recognizing wrist pathologies using an extremely limited dataset. Initially, we approach the problem as a fine-grained recognition task, aiming to identify subtle X-ray pathologies that conventional CNNs overlook. Secondly, we enhance network performance by fusing patient metadata with X-ray images. Thirdly, rather than pre-training on a coarse-grained dataset like ImageNet, we utilize weights trained on a fine-grained dataset. While metadata integration has been used in other medical domains, this is a novel application for wrist pathologies. Our results show that a fine-grained strategy and metadata integration improve diagnostic accuracy by 2% with a limited dataset and by over 10% with a larger fracture-focused dataset.
From Code to Compliance: Assessing ChatGPT's Utility in Designing an Accessible Webpage -- A Case Study
Jan 07, 2025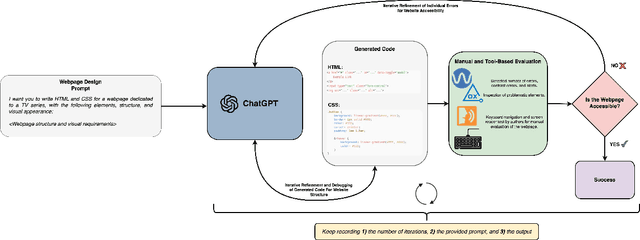
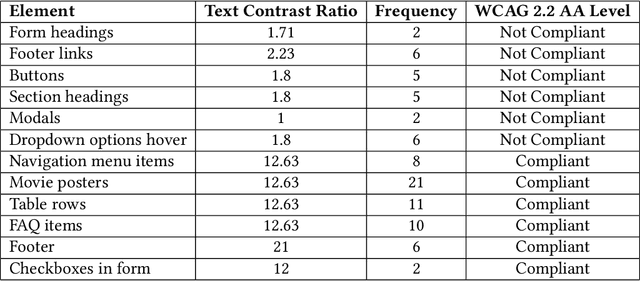

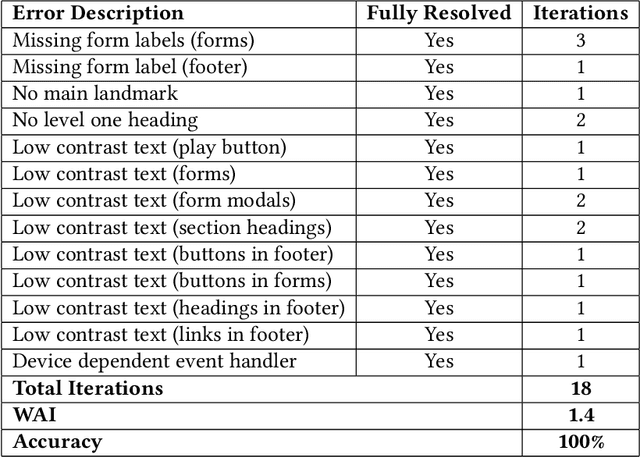
Web accessibility ensures that individuals with disabilities can access and interact with digital content without barriers, yet a significant majority of most used websites fail to meet accessibility standards. This study evaluates ChatGPT's (GPT-4o) ability to generate and improve web pages in line with Web Content Accessibility Guidelines (WCAG). While ChatGPT can effectively address accessibility issues when prompted, its default code often lacks compliance, reflecting limitations in its training data and prevailing inaccessible web practices. Automated and manual testing revealed strengths in resolving simple issues but challenges with complex tasks, requiring human oversight and additional iterations. Unlike prior studies, we incorporate manual evaluation, dynamic elements, and use the visual reasoning capability of ChatGPT along with the prompts to fix accessibility issues. Providing screenshots alongside prompts enhances the LLM's ability to address accessibility issues by allowing it to analyze surrounding components, such as determining appropriate contrast colors. We found that effective prompt engineering, such as providing concise, structured feedback and incorporating visual aids, significantly enhances ChatGPT's performance. These findings highlight the potential and limitations of large language models for accessible web development, offering practical guidance for developers to create more inclusive websites.
Navigating limitations with precision: A fine-grained ensemble approach to wrist pathology recognition on a limited x-ray dataset
Dec 18, 2024

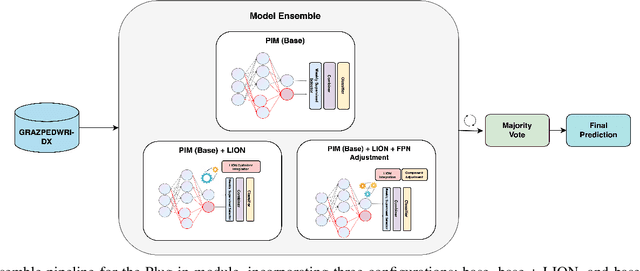

The exploration of automated wrist fracture recognition has gained considerable research attention in recent years. In practical medical scenarios, physicians and surgeons may lack the specialized expertise required for accurate X-ray interpretation, highlighting the need for machine vision to enhance diagnostic accuracy. However, conventional recognition techniques face challenges in discerning subtle differences in X-rays when classifying wrist pathologies, as many of these pathologies, such as fractures, can be small and hard to distinguish. This study tackles wrist pathology recognition as a fine-grained visual recognition (FGVR) problem, utilizing a limited, custom-curated dataset that mirrors real-world medical constraints, relying solely on image-level annotations. We introduce a specialized FGVR-based ensemble approach to identify discriminative regions within X-rays. We employ an Explainable AI (XAI) technique called Grad-CAM to pinpoint these regions. Our ensemble approach outperformed many conventional SOTA and FGVR techniques, underscoring the effectiveness of our strategy in enhancing accuracy in wrist pathology recognition.
MAP: Multi-Human-Value Alignment Palette
Oct 24, 2024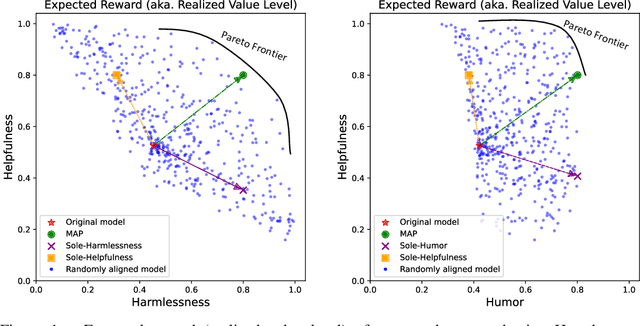
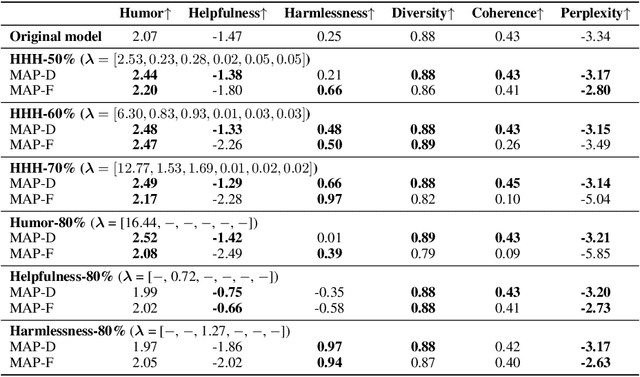
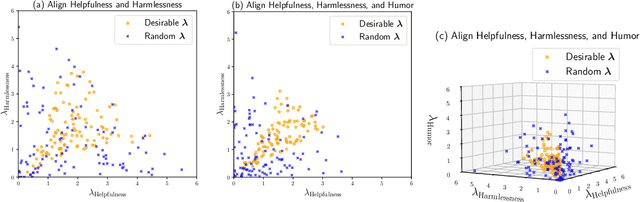
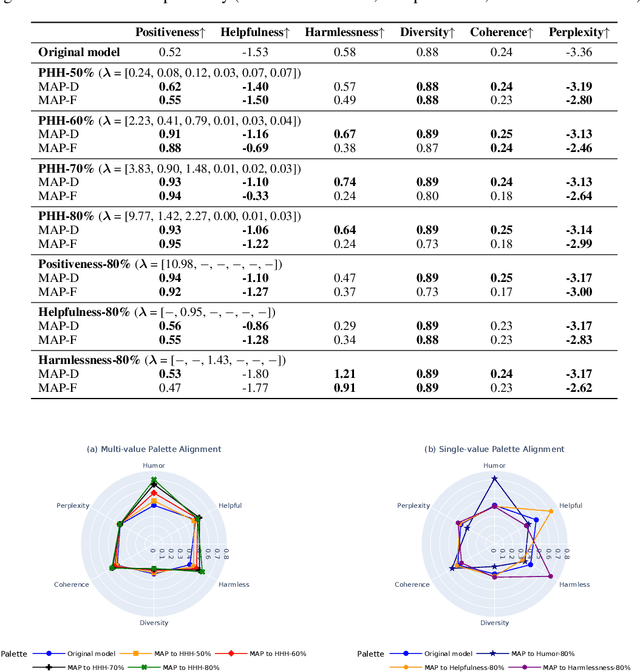
Ensuring that generative AI systems align with human values is essential but challenging, especially when considering multiple human values and their potential trade-offs. Since human values can be personalized and dynamically change over time, the desirable levels of value alignment vary across different ethnic groups, industry sectors, and user cohorts. Within existing frameworks, it is hard to define human values and align AI systems accordingly across different directions simultaneously, such as harmlessness, helpfulness, and positiveness. To address this, we develop a novel, first-principle approach called Multi-Human-Value Alignment Palette (MAP), which navigates the alignment across multiple human values in a structured and reliable way. MAP formulates the alignment problem as an optimization task with user-defined constraints, which define human value targets. It can be efficiently solved via a primal-dual approach, which determines whether a user-defined alignment target is achievable and how to achieve it. We conduct a detailed theoretical analysis of MAP by quantifying the trade-offs between values, the sensitivity to constraints, the fundamental connection between multi-value alignment and sequential alignment, and proving that linear weighted rewards are sufficient for multi-value alignment. Extensive experiments demonstrate MAP's ability to align multiple values in a principled manner while delivering strong empirical performance across various tasks.
Metadata augmented deep neural networks for wild animal classification
Sep 07, 2024



Camera trap imagery has become an invaluable asset in contemporary wildlife surveillance, enabling researchers to observe and investigate the behaviors of wild animals. While existing methods rely solely on image data for classification, this may not suffice in cases of suboptimal animal angles, lighting, or image quality. This study introduces a novel approach that enhances wild animal classification by combining specific metadata (temperature, location, time, etc) with image data. Using a dataset focused on the Norwegian climate, our models show an accuracy increase from 98.4% to 98.9% compared to existing methods. Notably, our approach also achieves high accuracy with metadata-only classification, highlighting its potential to reduce reliance on image quality. This work paves the way for integrated systems that advance wildlife classification technology.
Learning from the few: Fine-grained approach to pediatric wrist pathology recognition on a limited dataset
Aug 24, 2024


Wrist pathologies, {particularly fractures common among children and adolescents}, present a critical diagnostic challenge. While X-ray imaging remains a prevalent diagnostic tool, the increasing misinterpretation rates highlight the need for more accurate analysis, especially considering the lack of specialized training among many surgeons and physicians. Recent advancements in deep convolutional neural networks offer promise in automating pathology detection in trauma X-rays. However, distinguishing subtle variations between {pediatric} wrist pathologies in X-rays remains challenging. Traditional manual annotation, though effective, is laborious, costly, and requires specialized expertise. {In this paper, we address the challenge of pediatric wrist pathology recognition with a fine-grained approach, aimed at automatically identifying discriminative regions in X-rays without manual intervention. We refine our fine-grained architecture through ablation analysis and the integration of LION.} Leveraging Grad-CAM, an explainable AI technique, we highlight these regions. Despite using limited data, reflective of real-world medical study constraints, our method consistently outperforms state-of-the-art image recognition models on both augmented and original (challenging) test sets. {Our proposed refined architecture achieves an increase in accuracy of 1.06% and 1.25% compared to the baseline method, resulting in accuracies of 86% and 84%, respectively. Moreover, our approach demonstrates the highest fracture sensitivity of 97%, highlighting its potential to enhance wrist pathology recognition. The implementation code can be found at https://github.com/ammarlodhi255/fine-grained-approach-to-wrist-pathology-recognition
Pediatric Wrist Fracture Detection in X-rays via YOLOv10 Algorithm and Dual Label Assignment System
Jul 31, 2024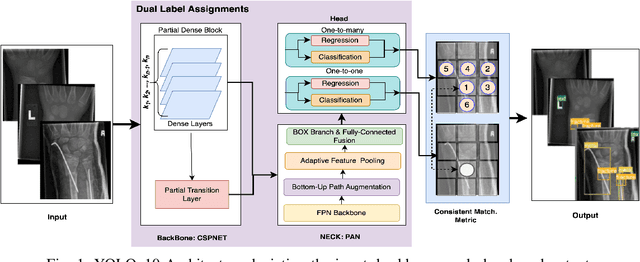
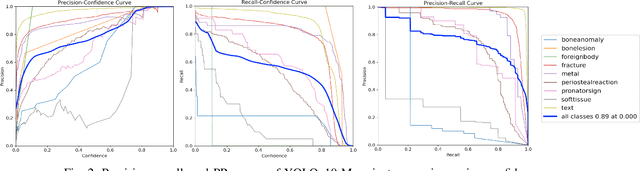
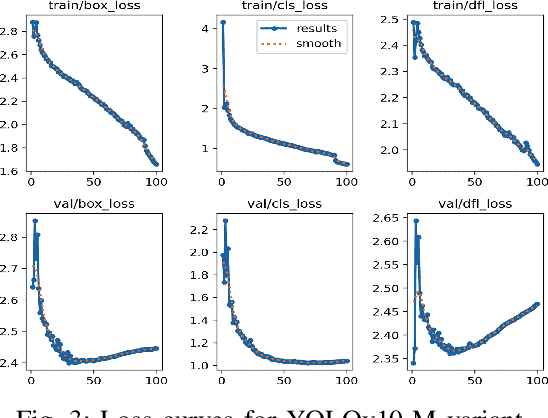
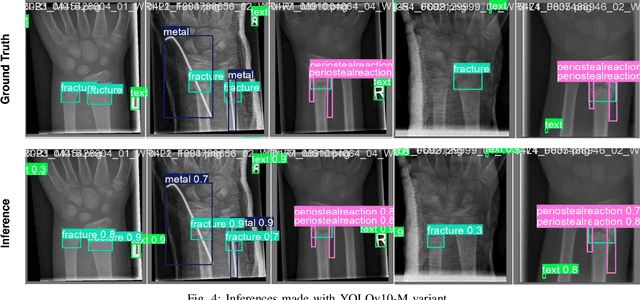
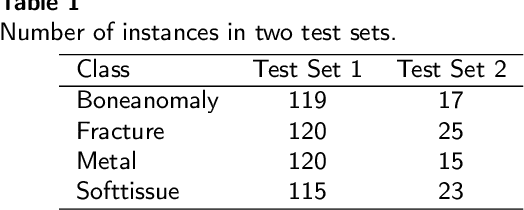
Wrist fractures are highly prevalent among children and can significantly impact their daily activities, such as attending school, participating in sports, and performing basic self-care tasks. If not treated properly, these fractures can result in chronic pain, reduced wrist functionality, and other long-term complications. Recently, advancements in object detection have shown promise in enhancing fracture detection, with systems achieving accuracy comparable to, or even surpassing, that of human radiologists. The YOLO series, in particular, has demonstrated notable success in this domain. This study is the first to provide a thorough evaluation of various YOLOv10 variants to assess their performance in detecting pediatric wrist fractures using the GRAZPEDWRI-DX dataset. It investigates how changes in model complexity, scaling the architecture, and implementing a dual-label assignment strategy can enhance detection performance. Experimental results indicate that our trained model achieved mean average precision (mAP@50-95) of 51.9\% surpassing the current YOLOv9 benchmark of 43.3\% on this dataset. This represents an improvement of 8.6\%. The implementation code is publicly available at https://github.com/ammarlodhi255/YOLOv10-Fracture-Detection
YOLOv10 for Automated Fracture Detection in Pediatric Wrist Trauma X-rays
Jul 22, 2024Wrist fractures are highly prevalent among children and can significantly impact their daily activities, such as attending school, participating in sports, and performing basic self-care tasks. If not treated properly, these fractures can result in chronic pain, reduced wrist functionality, and other long-term complications. Recently, advancements in object detection have shown promise in enhancing fracture detection, with systems achieving accuracy comparable to, or even surpassing, that of human radiologists. The YOLO series, in particular, has demonstrated notable success in this domain. This study is the first to provide a thorough evaluation of various YOLOv10 variants to assess their performance in detecting pediatric wrist fractures using the GRAZPEDWRI-DX dataset. It investigates how changes in model complexity, scaling the architecture, and implementing a dual-label assignment strategy can enhance detection performance. Experimental results indicate that our trained model achieved mean average precision (mAP@50-95) of 51.9\% surpassing the current YOLOv9 benchmark of 43.3\% on this dataset. This represents an improvement of 8.6\%. The implementation code is publicly available at https://github.com/ammarlodhi255/YOLOv10-Fracture-Detection
Enhancing Wrist Abnormality Detection with YOLO: Analysis of State-of-the-art Single-stage Detection Models
Jul 17, 2024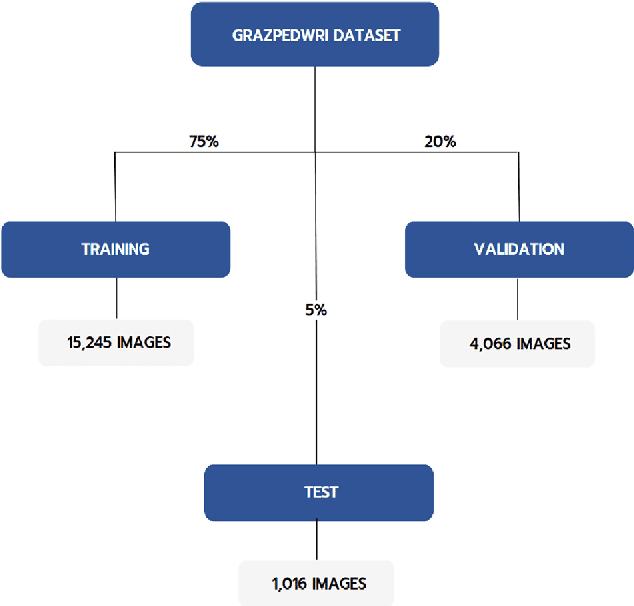
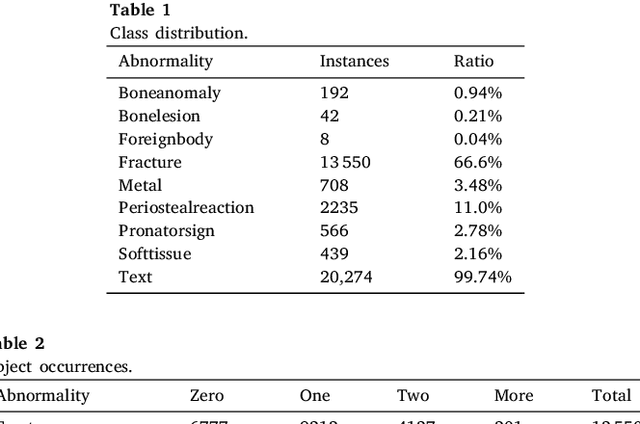
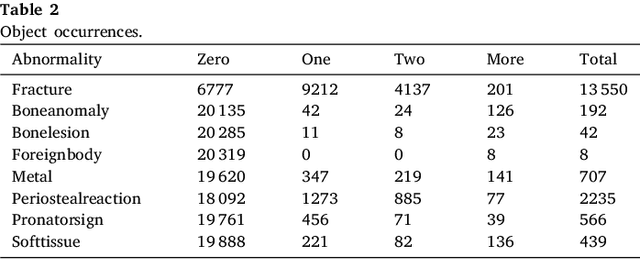
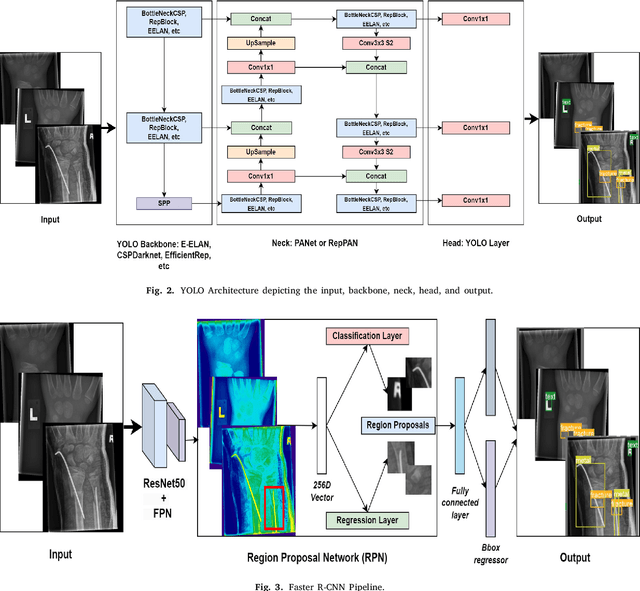
Diagnosing and treating abnormalities in the wrist, specifically distal radius, and ulna fractures, is a crucial concern among children, adolescents, and young adults, with a higher incidence rate during puberty. However, the scarcity of radiologists and the lack of specialized training among medical professionals pose a significant risk to patient care. This problem is further exacerbated by the rising number of imaging studies and limited access to specialist reporting in certain regions. This highlights the need for innovative solutions to improve the diagnosis and treatment of wrist abnormalities. Automated wrist fracture detection using object detection has shown potential, but current studies mainly use two-stage detection methods with limited evidence for single-stage effectiveness. This study employs state-of-the-art single-stage deep neural network-based detection models YOLOv5, YOLOv6, YOLOv7, and YOLOv8 to detect wrist abnormalities. Through extensive experimentation, we found that these YOLO models outperform the commonly used two-stage detection algorithm, Faster R-CNN, in bone fracture detection. Additionally, compound-scaled variants of each YOLO model were compared, with YOLOv8x demonstrating a fracture detection mean average precision (mAP) of 0.95 and an overall mAP of 0.77 on the GRAZPEDWRI-DX pediatric wrist dataset, highlighting the potential of single-stage models for enhancing pediatric wrist imaging.