 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom GPT-3 to GPT-5: Mapping their capabilities, scope, limitations, and consequences
Apr 11, 2026We present the progress of the GPT family from GPT-3 through GPT-3.5, GPT-4, GPT-4 Turbo, GPT-4o, GPT-4.1, and the GPT-5 family. Our work is comparative rather than merely historical. We investigates how the family evolved in technical framing, user interaction, modality, deployment architecture, and governance viewpoint. The work focuses on five recurring themes: technical progression, capability changes, deployment shifts, persistent limitations, and downstream consequences. In term of research design, we consider official technical reports, system cards, API and model documentation, product announcements, release notes, and peer-reviewed secondary studies. A primary assertion is that later GPT generations should not be interpreted only as larger or more accurate language models. Instead, the family evolves from a scaled few-shot text predictor into a set of aligned, multimodal, tool-oriented, long-context, and increasingly workflow-integrated systems. This development complicates simple model-to-model comparison because product routing, tool access, safety tuning, and interface design become part of the effective system. Across generations, several limitations remain unchanged: hallucination, prompt sensitivity, benchmark fragility, uneven behavior across domains and populations, and incomplete public transparency about architecture and training. However, the family has evolved software development, educational practice, information work, interface design, and discussions of frontier-model governance. We infer that the transition from GPT-3 to GPT-5 is best understood not only as an improvement in model capability, but also as a broader reformulation of what a deployable AI system is, how it is evaluated, and where responsibility should be located when such systems are used at scale.
Navigating limitations with precision: A fine-grained ensemble approach to wrist pathology recognition on a limited x-ray dataset
Dec 18, 2024

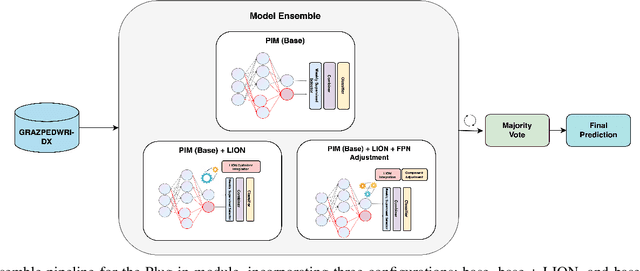

The exploration of automated wrist fracture recognition has gained considerable research attention in recent years. In practical medical scenarios, physicians and surgeons may lack the specialized expertise required for accurate X-ray interpretation, highlighting the need for machine vision to enhance diagnostic accuracy. However, conventional recognition techniques face challenges in discerning subtle differences in X-rays when classifying wrist pathologies, as many of these pathologies, such as fractures, can be small and hard to distinguish. This study tackles wrist pathology recognition as a fine-grained visual recognition (FGVR) problem, utilizing a limited, custom-curated dataset that mirrors real-world medical constraints, relying solely on image-level annotations. We introduce a specialized FGVR-based ensemble approach to identify discriminative regions within X-rays. We employ an Explainable AI (XAI) technique called Grad-CAM to pinpoint these regions. Our ensemble approach outperformed many conventional SOTA and FGVR techniques, underscoring the effectiveness of our strategy in enhancing accuracy in wrist pathology recognition.
Metadata augmented deep neural networks for wild animal classification
Sep 07, 2024



Camera trap imagery has become an invaluable asset in contemporary wildlife surveillance, enabling researchers to observe and investigate the behaviors of wild animals. While existing methods rely solely on image data for classification, this may not suffice in cases of suboptimal animal angles, lighting, or image quality. This study introduces a novel approach that enhances wild animal classification by combining specific metadata (temperature, location, time, etc) with image data. Using a dataset focused on the Norwegian climate, our models show an accuracy increase from 98.4% to 98.9% compared to existing methods. Notably, our approach also achieves high accuracy with metadata-only classification, highlighting its potential to reduce reliance on image quality. This work paves the way for integrated systems that advance wildlife classification technology.
Learning from the few: Fine-grained approach to pediatric wrist pathology recognition on a limited dataset
Aug 24, 2024


Wrist pathologies, {particularly fractures common among children and adolescents}, present a critical diagnostic challenge. While X-ray imaging remains a prevalent diagnostic tool, the increasing misinterpretation rates highlight the need for more accurate analysis, especially considering the lack of specialized training among many surgeons and physicians. Recent advancements in deep convolutional neural networks offer promise in automating pathology detection in trauma X-rays. However, distinguishing subtle variations between {pediatric} wrist pathologies in X-rays remains challenging. Traditional manual annotation, though effective, is laborious, costly, and requires specialized expertise. {In this paper, we address the challenge of pediatric wrist pathology recognition with a fine-grained approach, aimed at automatically identifying discriminative regions in X-rays without manual intervention. We refine our fine-grained architecture through ablation analysis and the integration of LION.} Leveraging Grad-CAM, an explainable AI technique, we highlight these regions. Despite using limited data, reflective of real-world medical study constraints, our method consistently outperforms state-of-the-art image recognition models on both augmented and original (challenging) test sets. {Our proposed refined architecture achieves an increase in accuracy of 1.06% and 1.25% compared to the baseline method, resulting in accuracies of 86% and 84%, respectively. Moreover, our approach demonstrates the highest fracture sensitivity of 97%, highlighting its potential to enhance wrist pathology recognition. The implementation code can be found at https://github.com/ammarlodhi255/fine-grained-approach-to-wrist-pathology-recognition
A New Lightweight Hybrid Graph Convolutional Neural Network -- CNN Scheme for Scene Classification using Object Detection Inference
Jul 19, 2024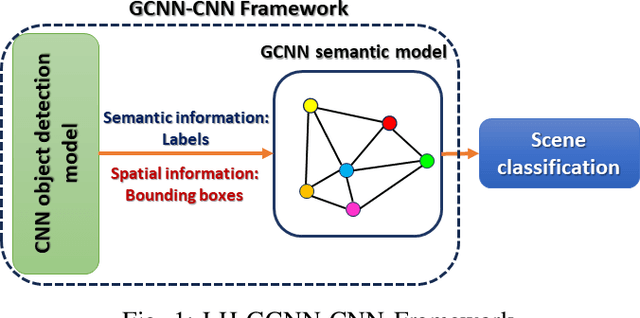
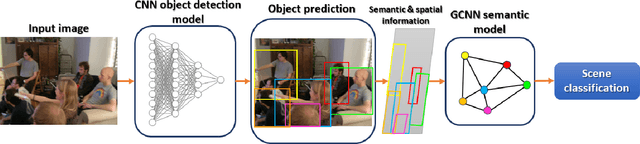
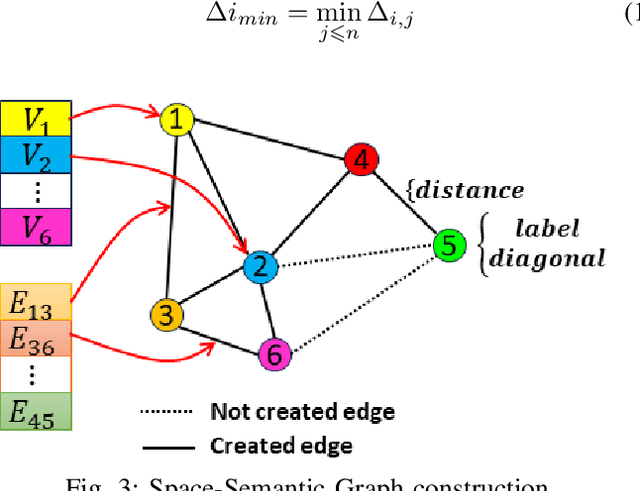
Scene understanding plays an important role in several high-level computer vision applications, such as autonomous vehicles, intelligent video surveillance, or robotics. However, too few solutions have been proposed for indoor/outdoor scene classification to ensure scene context adaptability for computer vision frameworks. We propose the first Lightweight Hybrid Graph Convolutional Neural Network (LH-GCNN)-CNN framework as an add-on to object detection models. The proposed approach uses the output of the CNN object detection model to predict the observed scene type by generating a coherent GCNN representing the semantic and geometric content of the observed scene. This new method, applied to natural scenes, achieves an efficiency of over 90\% for scene classification in a COCO-derived dataset containing a large number of different scenes, while requiring fewer parameters than traditional CNN methods. For the benefit of the scientific community, we will make the source code publicly available: https://github.com/Aymanbegh/Hybrid-GCNN-CNN.
Deep Learning for Multi-Label Learning: A Comprehensive Survey
Jan 29, 2024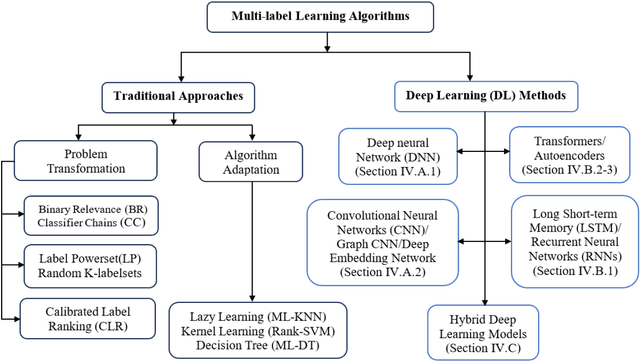
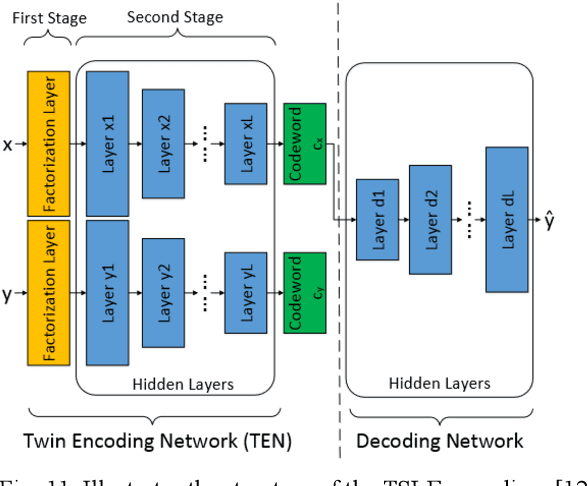
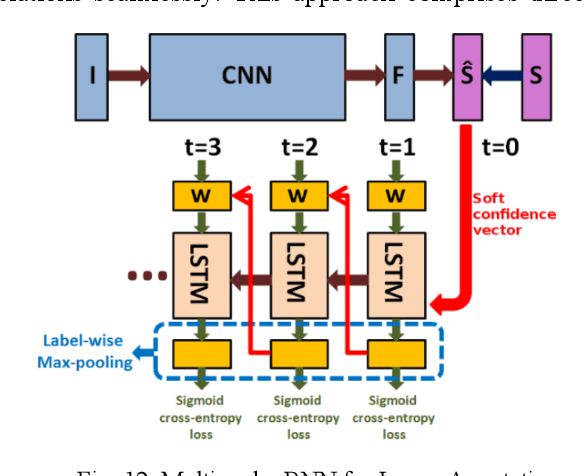
Multi-label learning is a rapidly growing research area that aims to predict multiple labels from a single input data point. In the era of big data, tasks involving multi-label classification (MLC) or ranking present significant and intricate challenges, capturing considerable attention in diverse domains. Inherent difficulties in MLC include dealing with high-dimensional data, addressing label correlations, and handling partial labels, for which conventional methods prove ineffective. Recent years have witnessed a notable increase in adopting deep learning (DL) techniques to address these challenges more effectively in MLC. Notably, there is a burgeoning effort to harness the robust learning capabilities of DL for improved modelling of label dependencies and other challenges in MLC. However, it is noteworthy that comprehensive studies specifically dedicated to DL for multi-label learning are limited. Thus, this survey aims to thoroughly review recent progress in DL for multi-label learning, along with a summary of open research problems in MLC. The review consolidates existing research efforts in DL for MLC,including deep neural networks, transformers, autoencoders, and convolutional and recurrent architectures. Finally, the study presents a comparative analysis of the existing methods to provide insightful observations and stimulate future research directions in this domain.
Kalman Filter Based Multiple Person Head Tracking
Jun 11, 2020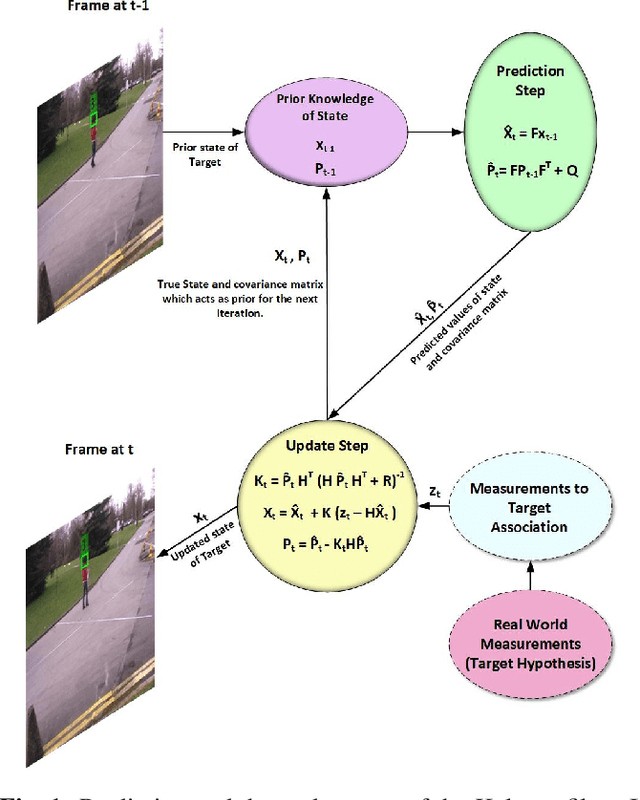

For multi-target tracking, target representation plays a crucial rule in performance. State-of-the-art approaches rely on the deep learning-based visual representation that gives an optimal performance at the cost of high computational complexity. In this paper, we come up with a simple yet effective target representation for human tracking. Our inspiration comes from the fact that the human body goes through severe deformation and inter/intra occlusion over the passage of time. So, instead of tracking the whole body part, a relative rigid organ tracking is selected for tracking the human over an extended period of time. Hence, we followed the tracking-by-detection paradigm and generated the target hypothesis of only the spatial locations of heads in every frame. After the localization of head location, a Kalman filter with a constant velocity motion model is instantiated for each target that follows the temporal evolution of the targets in the scene. For associating the targets in the consecutive frames, combinatorial optimization is used that associates the corresponding targets in a greedy fashion. Qualitative results are evaluated on four challenging video surveillance dataset and promising results has been achieved.
Multi-Modal Machine Learning for Flood Detection in News, Social Media and Satellite Sequences
Oct 07, 2019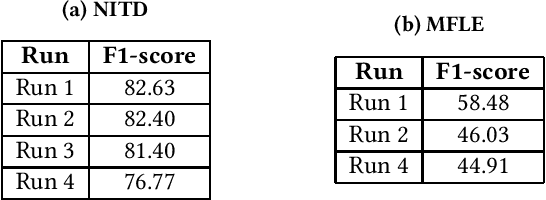
In this paper we present our methods for the MediaEval 2019 Mul-timedia Satellite Task, which is aiming to extract complementaryinformation associated with adverse events from Social Media andsatellites. For the first challenge, we propose a framework jointly uti-lizing colour, object and scene-level information to predict whetherthe topic of an article containing an image is a flood event or not.Visual features are combined using early and late fusion techniquesachieving an average F1-score of82.63,82.40,81.40and76.77. Forthe multi-modal flood level estimation, we rely on both visualand textual information achieving an average F1-score of58.48and46.03, respectively. Finally, for the flooding detection in time-based satellite image sequences we used a combination of classicalcomputer-vision and machine learning approaches achieving anaverage F1-score of58.82%
A deep learning approach for analyzing the composition of chemometric data
May 07, 2019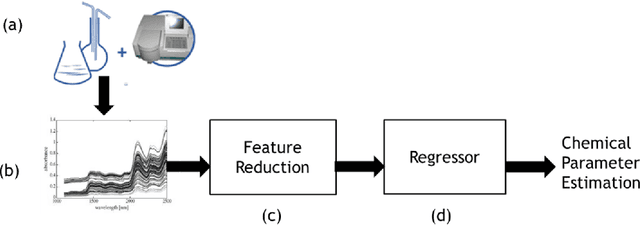
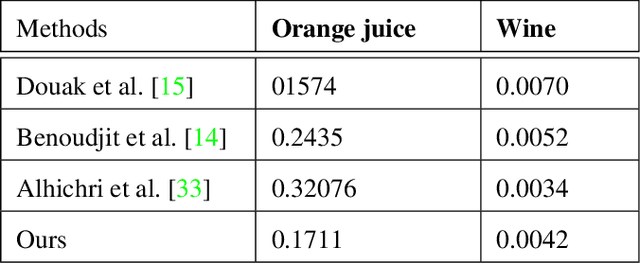
We propose novel deep learning based chemometric data analysis technique. We trained L2 regularized sparse autoencoder end-to-end for reducing the size of the feature vector to handle the classic problem of the curse of dimensionality in chemometric data analysis. We introduce a novel technique of automatic selection of nodes inside the hidden layer of an autoencoder through Pareto optimization. Moreover, Gaussian process regressor is applied on the reduced size feature vector for the regression. We evaluated our technique on orange juice and wine dataset and results are compared against 3 state-of-the-art methods. Quantitative results are shown on Normalized Mean Square Error (NMSE) and the results show considerable improvement in the state-of-the-art.