 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing sleep detection by modelling weak label sets: A novel weakly supervised learning approach
Feb 27, 2024



Understanding sleep and activity patterns plays a crucial role in physical and mental health. This study introduces a novel approach for sleep detection using weakly supervised learning for scenarios where reliable ground truth labels are unavailable. The proposed method relies on a set of weak labels, derived from the predictions generated by conventional sleep detection algorithms. Introducing a novel approach, we suggest a novel generalised non-linear statistical model in which the number of weak sleep labels is modelled as outcome of a binomial distribution. The probability of sleep in the binomial distribution is linked to the outcomes of neural networks trained to detect sleep based on actigraphy. We show that maximizing the likelihood function of the model, is equivalent to minimizing the soft cross-entropy loss. Additionally, we explored the use of the Brier score as a loss function for weak labels. The efficacy of the suggested modelling framework was demonstrated using the Multi-Ethnic Study of Atherosclerosis dataset. A \gls{lstm} trained on the soft cross-entropy outperformed conventional sleep detection algorithms, other neural network architectures and loss functions in accuracy and model calibration. This research not only advances sleep detection techniques in scenarios where ground truth data is scarce but also contributes to the broader field of weakly supervised learning by introducing innovative approach in modelling sets of weak labels.
Grand Challenge On Detecting Cheapfakes
Apr 03, 2023Cheapfake is a recently coined term that encompasses non-AI ("cheap") manipulations of multimedia content. Cheapfakes are known to be more prevalent than deepfakes. Cheapfake media can be created using editing software for image/video manipulations, or even without using any software, by simply altering the context of an image/video by sharing the media alongside misleading claims. This alteration of context is referred to as out-of-context (OOC) misuse of media. OOC media is much harder to detect than fake media, since the images and videos are not tampered. In this challenge, we focus on detecting OOC images, and more specifically the misuse of real photographs with conflicting image captions in news items. The aim of this challenge is to develop and benchmark models that can be used to detect whether given samples (news image and associated captions) are OOC, based on the recently compiled COSMOS dataset.
Visual explanations for polyp detection: How medical doctors assess intrinsic versus extrinsic explanations
Mar 23, 2022
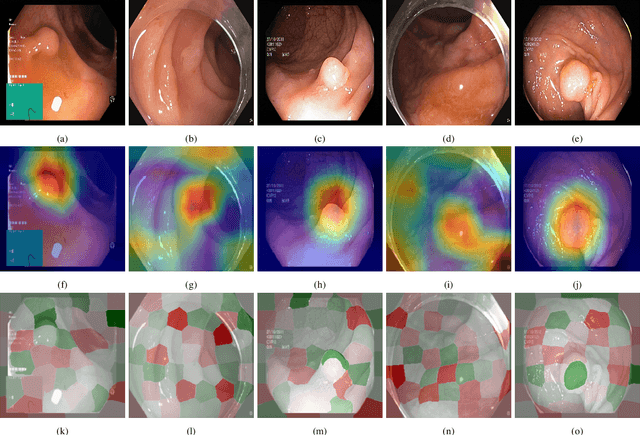
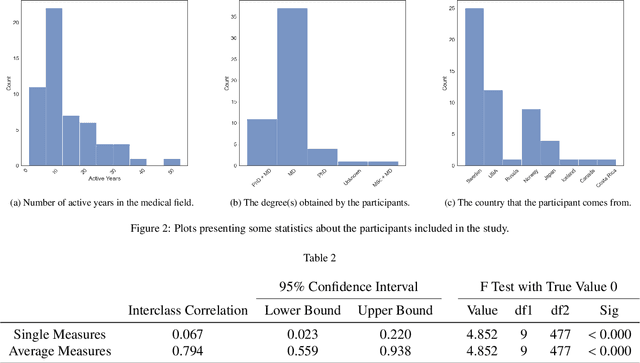

Deep learning has in recent years achieved immense success in all areas of computer vision and has the potential of assisting medical doctors in analyzing visual content for disease and other abnormalities. However, the current state of deep learning is very much a black box, making medical professionals highly skeptical about integrating these methods into clinical practice. Several methods have been proposed in order to shine some light onto these black boxes, but there is no consensus on the opinion of the medical doctors that will consume these explanations. This paper presents a study asking medical doctors about their opinion of current state-of-the-art explainable artificial intelligence methods when applied to a gastrointestinal disease detection use case. We compare two different categories of explanation methods, intrinsic and extrinsic, and gauge their opinion of the current value of these explanations. The results indicate that intrinsic explanations are preferred and that explanation.
Parallel feature selection based on the trace ratio criterion
Mar 03, 2022
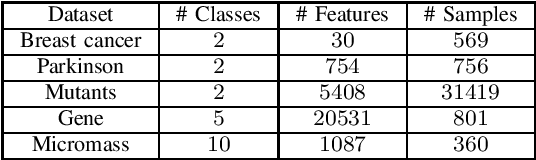


The growth of data today poses a challenge in management and inference. While feature extraction methods are capable of reducing the size of the data for inference, they do not help in minimizing the cost of data storage. On the other hand, feature selection helps to remove the redundant features and therefore is helpful not only in inference but also in reducing management costs. This work presents a novel parallel feature selection approach for classification, namely Parallel Feature Selection using Trace criterion (PFST), which scales up to very large datasets. Our method uses trace criterion, a measure of class separability used in Fisher's Discriminant Analysis, to evaluate feature usefulness. We analyzed the criterion's desirable properties theoretically. Based on the criterion, PFST rapidly finds important features out of a set of features for big datasets by first making a forward selection with early removal of seemingly redundant features parallelly. After the most important features are included in the model, we check back their contribution for possible interaction that may improve the fit. Lastly, we make a backward selection to check back possible redundant added by the forward steps. We evaluate our methods via various experiments using Linear Discriminant Analysis as the classifier on selected features. The experiments show that our method can produce a small set of features in a fraction of the amount of time by the other methods under comparison. In addition, the classifier trained on the features selected by PFST not only achieves better accuracy than the ones chosen by other approaches but can also achieve better accuracy than the classification on all available features.
Long Short Term Memory Networks for Bandwidth Forecasting in Mobile Broadband Networks under Mobility
Nov 20, 2020

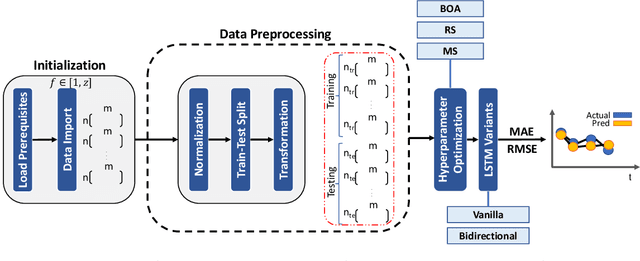

Bandwidth forecasting in Mobile Broadband (MBB) networks is a challenging task, particularly when coupled with a degree of mobility. In this work, we introduce HINDSIGHT++, an open-source R-based framework for bandwidth forecasting experimentation in MBB networks with Long Short Term Memory (LSTM) networks. We instrument HINDSIGHT++ following an Automated Machine Learning (AutoML) paradigm to first, alleviate the burden of data preprocessing, and second, enhance performance related aspects. We primarily focus on bandwidth forecasting for Fifth Generation (5G) networks. In particular, we leverage 5Gophers, the first open-source attempt to measure network performance on operational 5G networks in the US. We further explore the LSTM performance boundaries on Fourth Generation (4G) commercial settings using NYU-METS, an open-source dataset comprising of hundreds of bandwidth traces spanning different mobility scenarios. Our study aims to investigate the impact of hyperparameter optimization on achieving state-of-the-art performance and beyond. Results highlight its significance under 5G scenarios showing an average Mean Absolute Error (MAE) decrease of near 30% when compared to prior state-of-the-art values. Due to its universal design, we argue that HINDSIGHT++ can serve as a handy software tool for a multitude of applications in other scientific fields.
Visual Sentiment Analysis from Disaster Images in Social Media
Sep 04, 2020


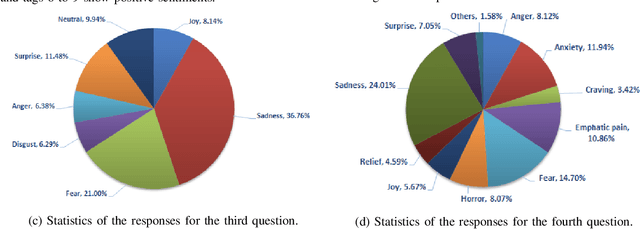
The increasing popularity of social networks and users' tendency towards sharing their feelings, expressions, and opinions in text, visual, and audio content, have opened new opportunities and challenges in sentiment analysis. While sentiment analysis of text streams has been widely explored in literature, sentiment analysis from images and videos is relatively new. This article focuses on visual sentiment analysis in a societal important domain, namely disaster analysis in social media. To this aim, we propose a deep visual sentiment analyzer for disaster related images, covering different aspects of visual sentiment analysis starting from data collection, annotation, model selection, implementation, and evaluations. For data annotation, and analyzing peoples' sentiments towards natural disasters and associated images in social media, a crowd-sourcing study has been conducted with a large number of participants worldwide. The crowd-sourcing study resulted in a large-scale benchmark dataset with four different sets of annotations, each aiming a separate task. The presented analysis and the associated dataset will provide a baseline/benchmark for future research in the domain. We believe the proposed system can contribute toward more livable communities by helping different stakeholders, such as news broadcasters, humanitarian organizations, as well as the general public.
Extracting temporal features into a spatial domain using autoencoders for sperm video analysis
Nov 08, 2019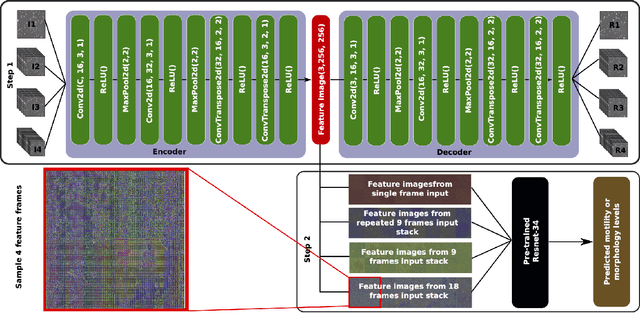
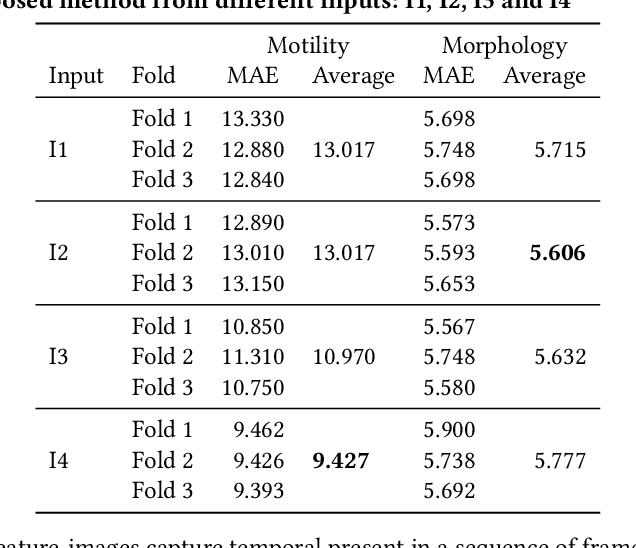
In this paper, we present a two-step deep learning method that is used to predict sperm motility and morphology-based on video recordings of human spermatozoa. First, we use an autoencoder to extract temporal features from a given semen video and plot these into image-space, which we call feature-images. Second, these feature-images are used to perform transfer learning to predict the motility and morphology values of human sperm. The presented method shows it's capability to extract temporal information into spatial domain feature-images which can be used with traditional convolutional neural networks. Furthermore, the accuracy of the predicted motility of a given semen sample shows that a deep learning-based model can capture the temporal information of microscopic recordings of human semen.
Stacked dense optical flows and dropout layers to predict sperm motility and morphology
Nov 08, 2019
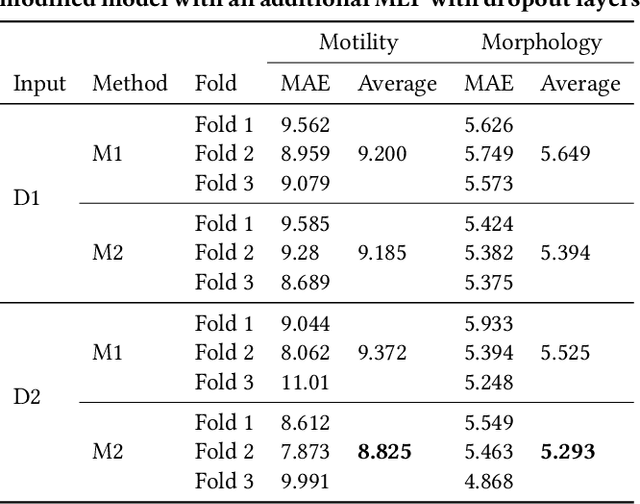
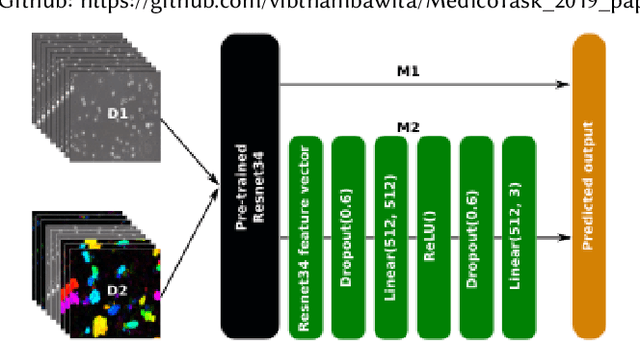
In this paper, we analyse two deep learning methods to predict sperm motility and sperm morphology from sperm videos. We use two different inputs: stacked pure frames of videos and dense optical flows of video frames. To solve this regression task of predicting motility and morphology, stacked dense optical flows and extracted original frames from sperm videos were used with the modified state of the art convolution neural networks. For modifications of the selected models, we have introduced an additional multi-layer perceptron to overcome the problem of over-fitting. The method which had an additional multi-layer perceptron with dropout layers, shows the best results when the inputs consist of both dense optical flows and an original frame of videos.
Multi-Modal Machine Learning for Flood Detection in News, Social Media and Satellite Sequences
Oct 07, 2019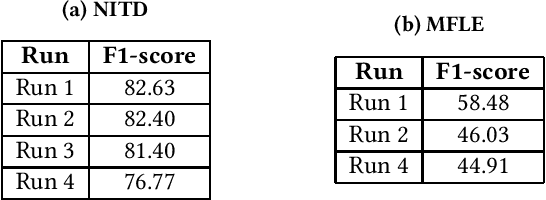
In this paper we present our methods for the MediaEval 2019 Mul-timedia Satellite Task, which is aiming to extract complementaryinformation associated with adverse events from Social Media andsatellites. For the first challenge, we propose a framework jointly uti-lizing colour, object and scene-level information to predict whetherthe topic of an article containing an image is a flood event or not.Visual features are combined using early and late fusion techniquesachieving an average F1-score of82.63,82.40,81.40and76.77. Forthe multi-modal flood level estimation, we rely on both visualand textual information achieving an average F1-score of58.48and46.03, respectively. Finally, for the flooding detection in time-based satellite image sequences we used a combination of classicalcomputer-vision and machine learning approaches achieving anaverage F1-score of58.82%
The Medico-Task 2018: Disease Detection in the Gastrointestinal Tract using Global Features and Deep Learning
Oct 31, 2018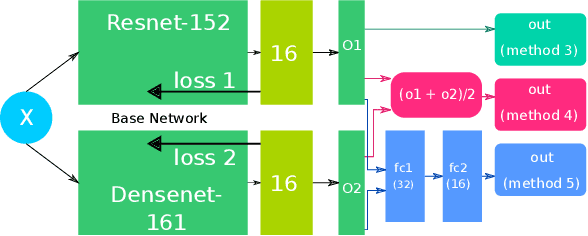


In this paper, we present our approach for the 2018 Medico Task classifying diseases in the gastrointestinal tract. We have proposed a system based on global features and deep neural networks. The best approach combines two neural networks, and the reproducible experimental results signify the efficiency of the proposed model with an accuracy rate of 95.80%, a precision of 95.87%, and an F1-score of 95.80%.
* 2 pages + 1 page for references, 1 figure, Conference paper