 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoSearch: Augmenting Worldwide Geolocalization with Web-Scale Reverse Image Search and Image Matching
Apr 28, 2026Worldwide image geolocalization, which aims to predict the GPS coordinates of any image on Earth, remains challenging due to global visual diversity. Recent generative approaches based on Retrieval-Augmented Generation (RAG) and Large Multimodal Models (LMMs) leverage candidates retrieved from fixed databases for reasoning, but often struggle with scenes that are absent from the reference set. In this work, we propose GeoSearch, an open-world geolocation framework that integrates web-scale reverse image search into the RAG pipeline. GeoSearch augments LMM prompts with database-retrieved coordinates and textual evidence extracted from web pages. To mitigate noise from irrelevant content, we introduce a two-layer filtering mechanism consisting of image matching, followed by confidence-based gating. Experiments on standard benchmarks Im2GPS3k and YFCC4k demonstrate the superiority of GeoSearch under leakage-aware evaluation. Our code and data are publicly available to support reproducibility.
SearchLLM: Detecting LLM Paraphrased Text by Measuring the Similarity with Regeneration of the Candidate Source via Search Engine
Jan 23, 2026With the advent of large language models (LLMs), it has become common practice for users to draft text and utilize LLMs to enhance its quality through paraphrasing. However, this process can sometimes result in the loss or distortion of the original intended meaning. Due to the human-like quality of LLM-generated text, traditional detection methods often fail, particularly when text is paraphrased to closely mimic original content. In response to these challenges, we propose a novel approach named SearchLLM, designed to identify LLM-paraphrased text by leveraging search engine capabilities to locate potential original text sources. By analyzing similarities between the input and regenerated versions of candidate sources, SearchLLM effectively distinguishes LLM-paraphrased content. SearchLLM is designed as a proxy layer, allowing seamless integration with existing detectors to enhance their performance. Experimental results across various LLMs demonstrate that SearchLLM consistently enhances the accuracy of recent detectors in detecting LLM-paraphrased text that closely mimics original content. Furthermore, SearchLLM also helps the detectors prevent paraphrasing attacks.
xMTrans: Temporal Attentive Cross-Modality Fusion Transformer for Long-Term Traffic Prediction
May 08, 2024Traffic predictions play a crucial role in intelligent transportation systems. The rapid development of IoT devices allows us to collect different kinds of data with high correlations to traffic predictions, fostering the development of efficient multi-modal traffic prediction models. Until now, there are few studies focusing on utilizing advantages of multi-modal data for traffic predictions. In this paper, we introduce a novel temporal attentive cross-modality transformer model for long-term traffic predictions, namely xMTrans, with capability of exploring the temporal correlations between the data of two modalities: one target modality (for prediction, e.g., traffic congestion) and one support modality (e.g., people flow). We conducted extensive experiments to evaluate our proposed model on traffic congestion and taxi demand predictions using real-world datasets. The results showed the superiority of xMTrans against recent state-of-the-art methods on long-term traffic predictions. In addition, we also conducted a comprehensive ablation study to further analyze the effectiveness of each module in xMTrans.
Grand Challenge On Detecting Cheapfakes
Apr 03, 2023Cheapfake is a recently coined term that encompasses non-AI ("cheap") manipulations of multimedia content. Cheapfakes are known to be more prevalent than deepfakes. Cheapfake media can be created using editing software for image/video manipulations, or even without using any software, by simply altering the context of an image/video by sharing the media alongside misleading claims. This alteration of context is referred to as out-of-context (OOC) misuse of media. OOC media is much harder to detect than fake media, since the images and videos are not tampered. In this challenge, we focus on detecting OOC images, and more specifically the misuse of real photographs with conflicting image captions in news items. The aim of this challenge is to develop and benchmark models that can be used to detect whether given samples (news image and associated captions) are OOC, based on the recently compiled COSMOS dataset.
Augmenting Ego-Vehicle for Traffic Near-Miss and Accident Classification Dataset using Manipulating Conditional Style Translation
Jan 06, 2023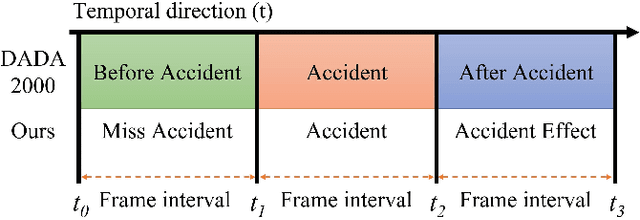
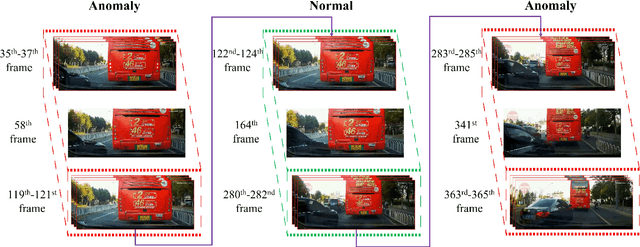

To develop the advanced self-driving systems, many researchers are focusing to alert all possible traffic risk cases from closed-circuit television (CCTV) and dashboard-mounted cameras. Most of these methods focused on identifying frame-by-frame in which an anomaly has occurred, but they are unrealized, which road traffic participant can cause ego-vehicle leading into collision because of available annotation dataset only to detect anomaly on traffic video. Near-miss is one type of accident and can be defined as a narrowly avoided accident. However, there is no difference between accident and near-miss at the time before the accident happened, so our contribution is to redefine the accident definition and re-annotate the accident inconsistency on DADA-2000 dataset together with near-miss. By extending the start and end time of accident duration, our annotation can precisely cover all ego-motions during an incident and consistently classify all possible traffic risk accidents including near-miss to give more critical information for real-world driving assistance systems. The proposed method integrates two different components: conditional style translation (CST) and separable 3-dimensional convolutional neural network (S3D). CST architecture is derived by unsupervised image-to-image translation networks (UNIT) used for augmenting the re-annotation DADA-2000 dataset to increase the number of traffic risk accident videos and to generalize the performance of video classification model on different types of conditions while S3D is useful for video classification to prove dataset re-annotation consistency. In evaluation, the proposed method achieved a significant improvement result by 10.25% positive margin from the baseline model for accuracy on cross-validation analysis.
* 8 pages, conference
An Open Case-based Reasoning Framework for Personalized On-board Driving Assistance in Risk Scenarios
Nov 23, 2022Driver reaction is of vital importance in risk scenarios. Drivers can take correct evasive maneuver at proper cushion time to avoid the potential traffic crashes, but this reaction process is highly experience-dependent and requires various levels of driving skills. To improve driving safety and avoid the traffic accidents, it is necessary to provide all road drivers with on-board driving assistance. This study explores the plausibility of case-based reasoning (CBR) as the inference paradigm underlying the choice of personalized crash evasive maneuvers and the cushion time, by leveraging the wealthy of human driving experience from the steady stream of traffic cases, which have been rarely explored in previous studies. To this end, in this paper, we propose an open evolving framework for generating personalized on-board driving assistance. In particular, we present the FFMTE model with high performance to model the traffic events and build the case database; A tailored CBR-based method is then proposed to retrieve, reuse and revise the existing cases to generate the assistance. We take the 100-Car Naturalistic Driving Study dataset as an example to build and test our framework; the experiments show reasonable results, providing the drivers with valuable evasive information to avoid the potential crashes in different scenarios.
Monitoring and Improving Personalized Sleep Quality from Long-Term Lifelogs
Nov 23, 2022Sleep plays a vital role in our physical, cognitive, and psychological well-being. Despite its importance, long-term monitoring of personalized sleep quality (SQ) in real-world contexts is still challenging. Many sleep researches are still developing clinically and far from accessible to the general public. Fortunately, wearables and IoT devices provide the potential to explore the sleep insights from multimodal data, and have been used in some SQ researches. However, most of these studies analyze the sleep related data and present the results in a delayed manner (i.e., today's SQ obtained from last night's data), it is sill difficult for individuals to know how their sleep will be before they go to bed and how they can proactively improve it. To this end, this paper proposes a computational framework to monitor the individual SQ based on both the objective and subjective data from multiple sources, and moves a step further towards providing the personalized feedback to improve the SQ in a data-driven manner. The feedback is implemented by referring the insights from the PMData dataset based on the discovered patterns between life events and different levels of SQ. The deep learning based personal SQ model (PerSQ), using the long-term heterogeneous data and considering the carry-over effect, achieves higher prediction performance compared with baseline models. A case study also shows reasonable results for an individual to monitor and improve the SQ in the future.
Multimodal and Crossmodal AI for Smart Data Analysis
Sep 03, 2022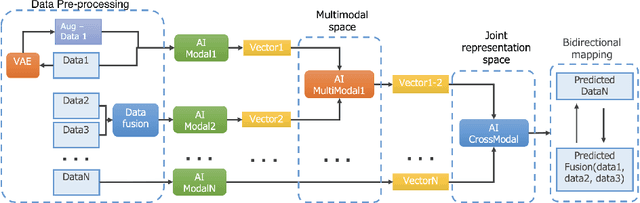

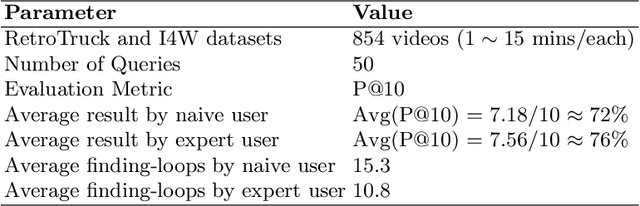
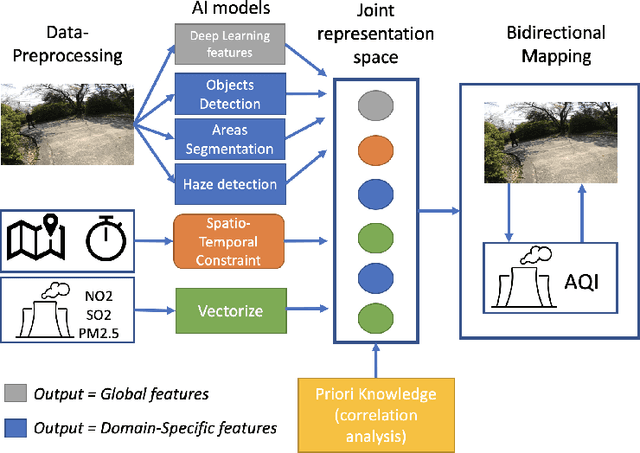
Recently, the multimodal and crossmodal AI techniques have attracted the attention of communities. The former aims to collect disjointed and heterogeneous data to compensate for complementary information to enhance robust prediction. The latter targets to utilize one modality to predict another modality by discovering the common attention sharing between them. Although both approaches share the same target: generate smart data from collected raw data, the former demands more modalities while the latter aims to decrease the variety of modalities. This paper first discusses the role of multimodal and crossmodal AI in smart data analysis in general. Then, we introduce the multimodal and crossmodal AI framework (MMCRAI) to balance the abovementioned approaches and make it easy to scale into different domains. This framework is integrated into xDataPF (the cross-data platform https://www.xdata.nict.jp/). We also introduce and discuss various applications built on this framework and xDataPF.