 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Semantic Correlation-Aware Masked Autoencoder for Unsupervised Audio-Visual Representation Learning
Apr 05, 2026Learning aligned multimodal embeddings from weakly paired, label-free corpora is challenging: pipelines often provide only pre-extracted features, clips contain multiple events, and spurious co-occurrences. We propose HSC-MAE (Hierarchical Semantic Correlation-Aware Masked Autoencoder), a dual-path teacher-student framework that enforces semantic consistency across three complementary levels of representation - from coarse to fine: (i) global-level canonical-geometry correlation via DCCA, which aligns audio and visual embeddings within a shared modality-invariant subspace; (ii) local-level neighborhood-semantics correlation via teacher-mined soft top-k affinities, which preserves multi-positive relational structure among semantically similar instances; and (iii) sample-level conditional-sufficiency correlation via masked autoencoding, which ensures individual embeddings retain discriminative semantic content under partial observation. Concretely, a student MAE path is trained with masked feature reconstruction and affinity-weighted soft top-k InfoNCE; an EMA teacher operating on unmasked inputs via the CCA path supplies stable canonical geometry and soft positives. Learnable multi-task weights reconcile competing objectives, and an optional distillation loss transfers teacher geometry into the student. Experiments on AVE and VEGAS demonstrate substantial mAP improvements over strong unsupervised baselines, validating that HSC-MAE yields robust and well-structured audio-visual representations.
Variance & Greediness: A comparative study of metric-learning losses
Jan 29, 2026Metric learning is central to retrieval, yet its effects on embedding geometry and optimization dynamics are not well understood. We introduce a diagnostic framework, VARIANCE (intra-/inter-class variance) and GREEDINESS (active ratio and gradient norms), to compare seven representative losses, i.e., Contrastive, Triplet, N-pair, InfoNCE, ArcFace, SCL, and CCL, across five image-retrieval datasets. Our analysis reveals that Triplet and SCL preserve higher within-class variance and clearer inter-class margins, leading to stronger top-1 retrieval in fine-grained settings. In contrast, Contrastive and InfoNCE compact embeddings are achieved quickly through many small updates, accelerating convergence but potentially oversimplifying class structures. N-pair achieves a large mean separation but with uneven spacing. These insights reveal a form of efficiency-granularity trade-off and provide practical guidance: prefer Triplet/SCL when diversity preservation and hard-sample discrimination are critical, and Contrastive/InfoNCE when faster embedding compaction is desired.
Learning Audio-Visual Embeddings with Inferred Latent Interaction Graphs
Jan 17, 2026Learning robust audio-visual embeddings requires bringing genuinely related audio and visual signals together while filtering out incidental co-occurrences - background noise, unrelated elements, or unannotated events. Most contrastive and triplet-loss methods use sparse annotated labels per clip and treat any co-occurrence as semantic similarity. For example, a video labeled "train" might also contain motorcycle audio and visual, because "motorcycle" is not the chosen annotation; standard methods treat these co-occurrences as negatives to true motorcycle anchors elsewhere, creating false negatives and missing true cross-modal dependencies. We propose a framework that leverages soft-label predictions and inferred latent interactions to address these issues: (1) Audio-Visual Semantic Alignment Loss (AV-SAL) trains a teacher network to produce aligned soft-label distributions across modalities, assigning nonzero probability to co-occurring but unannotated events and enriching the supervision signal. (2) Inferred Latent Interaction Graph (ILI) applies the GRaSP algorithm to teacher soft labels to infer a sparse, directed dependency graph among classes. This graph highlights directional dependencies (e.g., "Train (visual)" -> "Motorcycle (audio)") that expose likely semantic or conditional relationships between classes; these are interpreted as estimated dependency patterns. (3) Latent Interaction Regularizer (LIR): A student network is trained with both metric loss and a regularizer guided by the ILI graph, pulling together embeddings of dependency-linked but unlabeled pairs in proportion to their soft-label probabilities. Experiments on AVE and VEGAS benchmarks show consistent improvements in mean average precision (mAP), demonstrating that integrating inferred latent interactions into embedding learning enhances robustness and semantic coherence.
GR-Dexter Technical Report
Dec 30, 2025Vision-language-action (VLA) models have enabled language-conditioned, long-horizon robot manipulation, but most existing systems are limited to grippers. Scaling VLA policies to bimanual robots with high degree-of-freedom (DoF) dexterous hands remains challenging due to the expanded action space, frequent hand-object occlusions, and the cost of collecting real-robot data. We present GR-Dexter, a holistic hardware-model-data framework for VLA-based generalist manipulation on a bimanual dexterous-hand robot. Our approach combines the design of a compact 21-DoF robotic hand, an intuitive bimanual teleoperation system for real-robot data collection, and a training recipe that leverages teleoperated robot trajectories together with large-scale vision-language and carefully curated cross-embodiment datasets. Across real-world evaluations spanning long-horizon everyday manipulation and generalizable pick-and-place, GR-Dexter achieves strong in-domain performance and improved robustness to unseen objects and unseen instructions. We hope GR-Dexter serves as a practical step toward generalist dexterous-hand robotic manipulation.
Enhancing Masked Time-Series Modeling via Dropping Patches
Dec 19, 2024



This paper explores how to enhance existing masked time-series modeling by randomly dropping sub-sequence level patches of time series. On this basis, a simple yet effective method named DropPatch is proposed, which has two remarkable advantages: 1) It improves the pre-training efficiency by a square-level advantage; 2) It provides additional advantages for modeling in scenarios such as in-domain, cross-domain, few-shot learning and cold start. This paper conducts comprehensive experiments to verify the effectiveness of the method and analyze its internal mechanism. Empirically, DropPatch strengthens the attention mechanism, reduces information redundancy and serves as an efficient means of data augmentation. Theoretically, it is proved that DropPatch slows down the rate at which the Transformer representations collapse into the rank-1 linear subspace by randomly dropping patches, thus optimizing the quality of the learned representations
xMTrans: Temporal Attentive Cross-Modality Fusion Transformer for Long-Term Traffic Prediction
May 08, 2024Traffic predictions play a crucial role in intelligent transportation systems. The rapid development of IoT devices allows us to collect different kinds of data with high correlations to traffic predictions, fostering the development of efficient multi-modal traffic prediction models. Until now, there are few studies focusing on utilizing advantages of multi-modal data for traffic predictions. In this paper, we introduce a novel temporal attentive cross-modality transformer model for long-term traffic predictions, namely xMTrans, with capability of exploring the temporal correlations between the data of two modalities: one target modality (for prediction, e.g., traffic congestion) and one support modality (e.g., people flow). We conducted extensive experiments to evaluate our proposed model on traffic congestion and taxi demand predictions using real-world datasets. The results showed the superiority of xMTrans against recent state-of-the-art methods on long-term traffic predictions. In addition, we also conducted a comprehensive ablation study to further analyze the effectiveness of each module in xMTrans.
Joint Learning of Local and Global Features for Aspect-based Sentiment Classification
Nov 02, 2023
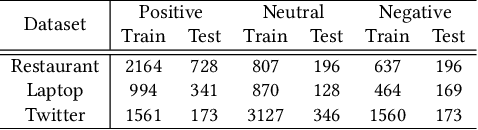


Aspect-based sentiment classification (ASC) aims to judge the sentiment polarity conveyed by the given aspect term in a sentence. The sentiment polarity is not only determined by the local context but also related to the words far away from the given aspect term. Most recent efforts related to the attention-based models can not sufficiently distinguish which words they should pay more attention to in some cases. Meanwhile, graph-based models are coming into ASC to encode syntactic dependency tree information. But these models do not fully leverage syntactic dependency trees as they neglect to incorporate dependency relation tag information into representation learning effectively. In this paper, we address these problems by effectively modeling the local and global features. Firstly, we design a local encoder containing: a Gaussian mask layer and a covariance self-attention layer. The Gaussian mask layer tends to adjust the receptive field around aspect terms adaptively to deemphasize the effects of unrelated words and pay more attention to local information. The covariance self-attention layer can distinguish the attention weights of different words more obviously. Furthermore, we propose a dual-level graph attention network as a global encoder by fully employing dependency tag information to capture long-distance information effectively. Our model achieves state-of-the-art performance on both SemEval 2014 and Twitter datasets.
Estimating Treatment Effects from Irregular Time Series Observations with Hidden Confounders
Mar 04, 2023



Causal analysis for time series data, in particular estimating individualized treatment effect (ITE), is a key task in many real-world applications, such as finance, retail, healthcare, etc. Real-world time series can include large-scale, irregular, and intermittent time series observations, raising significant challenges to existing work attempting to estimate treatment effects. Specifically, the existence of hidden confounders can lead to biased treatment estimates and complicate the causal inference process. In particular, anomaly hidden confounders which exceed the typical range can lead to high variance estimates. Moreover, in continuous time settings with irregular samples, it is challenging to directly handle the dynamics of causality. In this paper, we leverage recent advances in Lipschitz regularization and neural controlled differential equations (CDE) to develop an effective and scalable solution, namely LipCDE, to address the above challenges. LipCDE can directly model the dynamic causal relationships between historical data and outcomes with irregular samples by considering the boundary of hidden confounders given by Lipschitz-constrained neural networks. Furthermore, we conduct extensive experiments on both synthetic and real-world datasets to demonstrate the effectiveness and scalability of LipCDE.