 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Examination of Balancing Strategy for Counterfactual Estimation on Time Series
Aug 16, 2024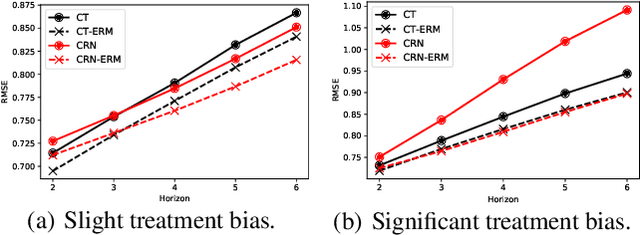
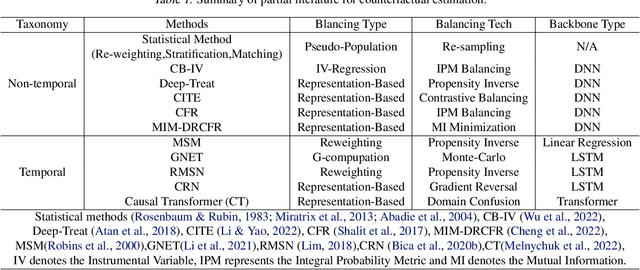
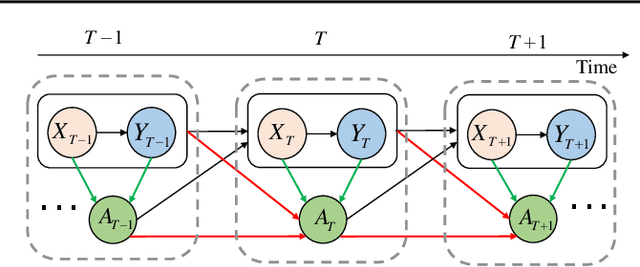
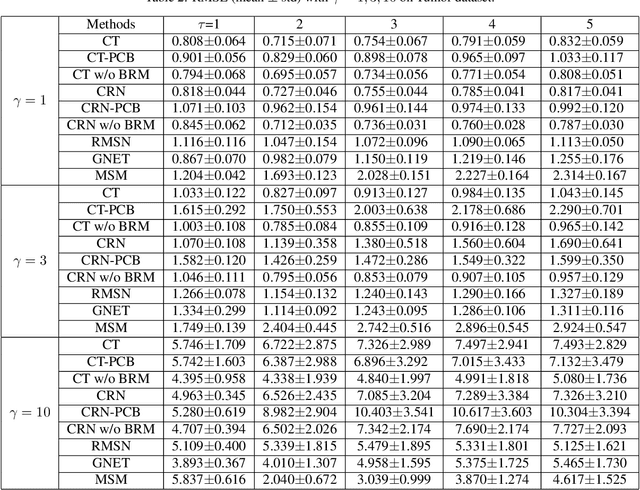
Counterfactual estimation from observations represents a critical endeavor in numerous application fields, such as healthcare and finance, with the primary challenge being the mitigation of treatment bias. The balancing strategy aimed at reducing covariate disparities between different treatment groups serves as a universal solution. However, when it comes to the time series data, the effectiveness of balancing strategies remains an open question, with a thorough analysis of the robustness and applicability of balancing strategies still lacking. This paper revisits counterfactual estimation in the temporal setting and provides a brief overview of recent advancements in balancing strategies. More importantly, we conduct a critical empirical examination for the effectiveness of the balancing strategies within the realm of temporal counterfactual estimation in various settings on multiple datasets. Our findings could be of significant interest to researchers and practitioners and call for a reexamination of the balancing strategy in time series settings.
COSTAR: Improved Temporal Counterfactual Estimation with Self-Supervised Learning
Nov 01, 2023



Estimation of temporal counterfactual outcomes from observed history is crucial for decision-making in many domains such as healthcare and e-commerce, particularly when randomized controlled trials (RCTs) suffer from high cost or impracticality. For real-world datasets, modeling time-dependent confounders is challenging due to complex dynamics, long-range dependencies and both past treatments and covariates affecting the future outcomes. In this paper, we introduce COunterfactual Self-supervised TrAnsformeR (COSTAR), a novel approach that integrates self-supervised learning for improved historical representations. The proposed framework combines temporal and feature-wise attention with a component-wise contrastive loss tailored for temporal treatment outcome observations, yielding superior performance in estimation accuracy and generalization to out-of-distribution data compared to existing models, as validated by empirical results on both synthetic and real-world datasets.
Estimating Treatment Effects from Irregular Time Series Observations with Hidden Confounders
Mar 04, 2023



Causal analysis for time series data, in particular estimating individualized treatment effect (ITE), is a key task in many real-world applications, such as finance, retail, healthcare, etc. Real-world time series can include large-scale, irregular, and intermittent time series observations, raising significant challenges to existing work attempting to estimate treatment effects. Specifically, the existence of hidden confounders can lead to biased treatment estimates and complicate the causal inference process. In particular, anomaly hidden confounders which exceed the typical range can lead to high variance estimates. Moreover, in continuous time settings with irregular samples, it is challenging to directly handle the dynamics of causality. In this paper, we leverage recent advances in Lipschitz regularization and neural controlled differential equations (CDE) to develop an effective and scalable solution, namely LipCDE, to address the above challenges. LipCDE can directly model the dynamic causal relationships between historical data and outcomes with irregular samples by considering the boundary of hidden confounders given by Lipschitz-constrained neural networks. Furthermore, we conduct extensive experiments on both synthetic and real-world datasets to demonstrate the effectiveness and scalability of LipCDE.
When Physics Meets Machine Learning: A Survey of Physics-Informed Machine Learning
Mar 31, 2022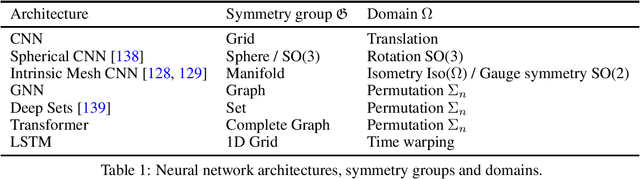
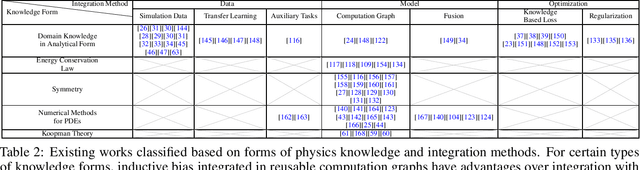
Physics-informed machine learning (PIML), referring to the combination of prior knowledge of physics, which is the high level abstraction of natural phenomenons and human behaviours in the long history, with data-driven machine learning models, has emerged as an effective way to mitigate the shortage of training data, to increase models' generalizability and to ensure the physical plausibility of results. In this paper, we survey an abundant number of recent works in PIML and summarize them from three aspects: (1) motivations of PIML, (2) physics knowledge in PIML, (3) methods of physics knowledge integration in PIML. We also discuss current challenges and corresponding research opportunities in PIML.
Cross-Node Federated Graph Neural Network for Spatio-Temporal Data Modeling
Jun 09, 2021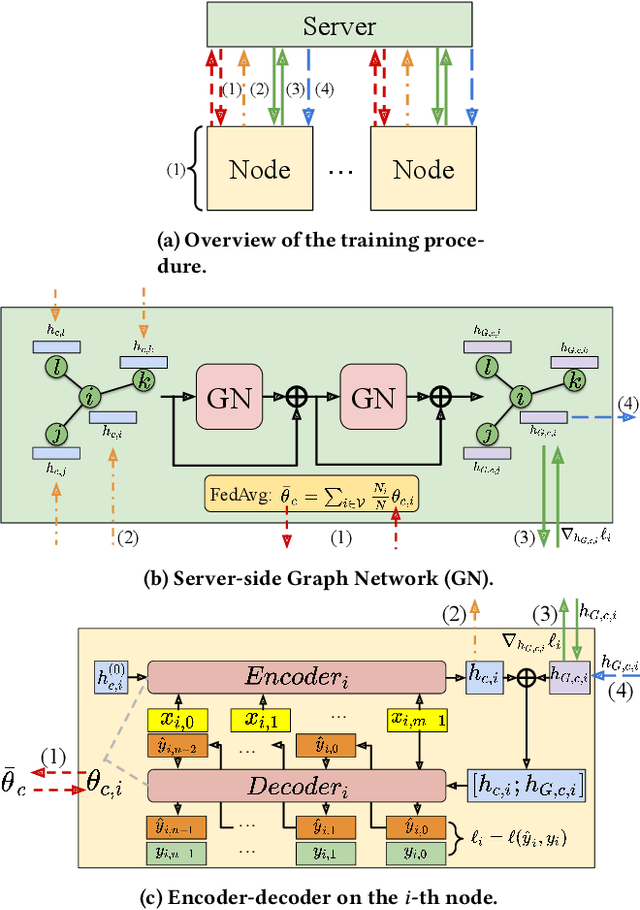

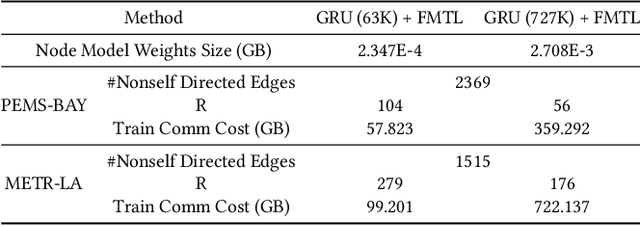
Vast amount of data generated from networks of sensors, wearables, and the Internet of Things (IoT) devices underscores the need for advanced modeling techniques that leverage the spatio-temporal structure of decentralized data due to the need for edge computation and licensing (data access) issues. While federated learning (FL) has emerged as a framework for model training without requiring direct data sharing and exchange, effectively modeling the complex spatio-temporal dependencies to improve forecasting capabilities still remains an open problem. On the other hand, state-of-the-art spatio-temporal forecasting models assume unfettered access to the data, neglecting constraints on data sharing. To bridge this gap, we propose a federated spatio-temporal model -- Cross-Node Federated Graph Neural Network (CNFGNN) -- which explicitly encodes the underlying graph structure using graph neural network (GNN)-based architecture under the constraint of cross-node federated learning, which requires that data in a network of nodes is generated locally on each node and remains decentralized. CNFGNN operates by disentangling the temporal dynamics modeling on devices and spatial dynamics on the server, utilizing alternating optimization to reduce the communication cost, facilitating computations on the edge devices. Experiments on the traffic flow forecasting task show that CNFGNN achieves the best forecasting performance in both transductive and inductive learning settings with no extra computation cost on edge devices, while incurring modest communication cost.
MIMIC-IF: Interpretability and Fairness Evaluation of Deep Learning Models on MIMIC-IV Dataset
Feb 12, 2021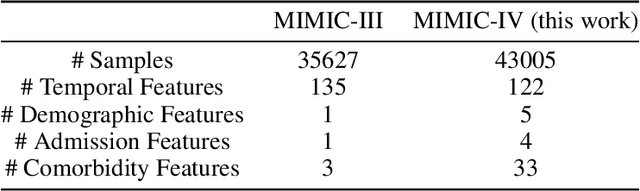
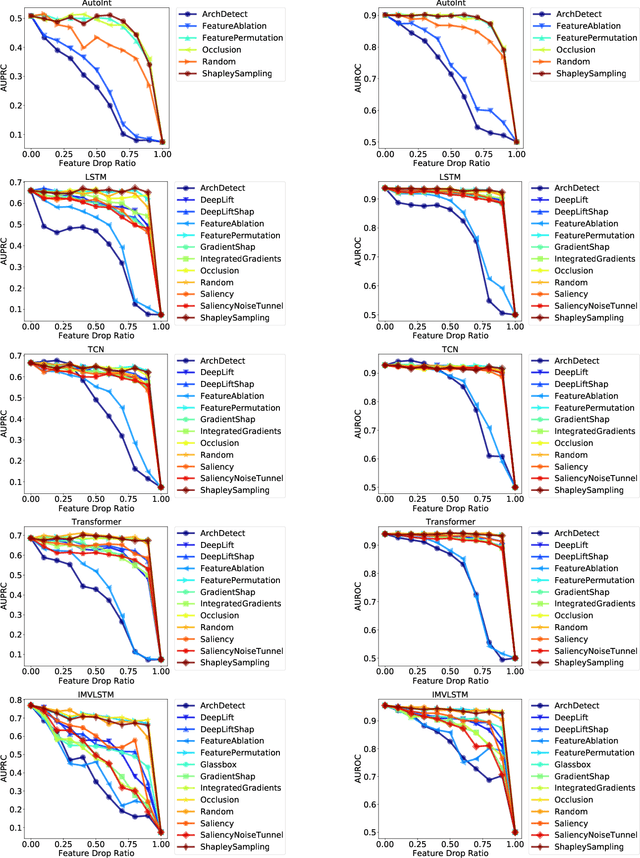

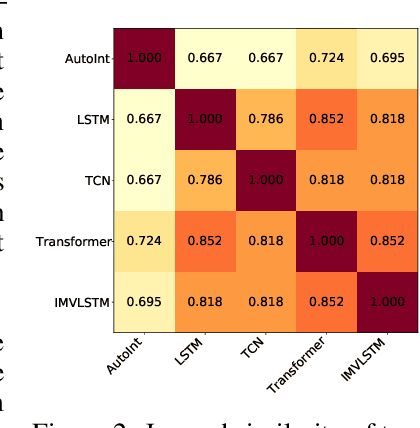
The recent release of large-scale healthcare datasets has greatly propelled the research of data-driven deep learning models for healthcare applications. However, due to the nature of such deep black-boxed models, concerns about interpretability, fairness, and biases in healthcare scenarios where human lives are at stake call for a careful and thorough examinations of both datasets and models. In this work, we focus on MIMIC-IV (Medical Information Mart for Intensive Care, version IV), the largest publicly available healthcare dataset, and conduct comprehensive analyses of dataset representation bias as well as interpretability and prediction fairness of deep learning models for in-hospital mortality prediction. In terms of interpretabilty, we observe that (1) the best performing interpretability method successfully identifies critical features for mortality prediction on various prediction models; (2) demographic features are important for prediction. In terms of fairness, we observe that (1) there exists disparate treatment in prescribing mechanical ventilation among patient groups across ethnicity, gender and age; (2) all of the studied mortality predictors are generally fair while the IMV-LSTM (Interpretable Multi-Variable Long Short-Term Memory) model provides the most accurate and unbiased predictions across all protected groups. We further draw concrete connections between interpretability methods and fairness metrics by showing how feature importance from interpretability methods can be beneficial in quantifying potential disparities in mortality predictors.
Physics-aware Spatiotemporal Modules with Auxiliary Tasks for Meta-Learning
Jun 15, 2020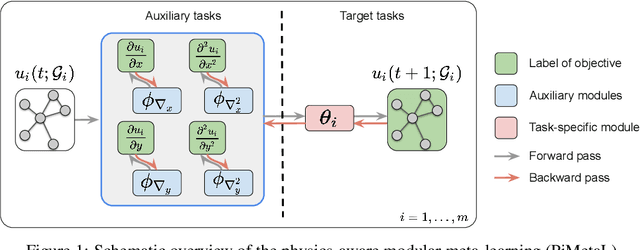

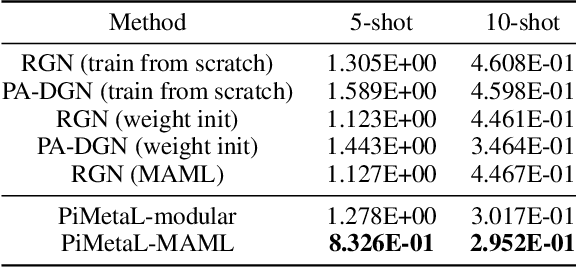
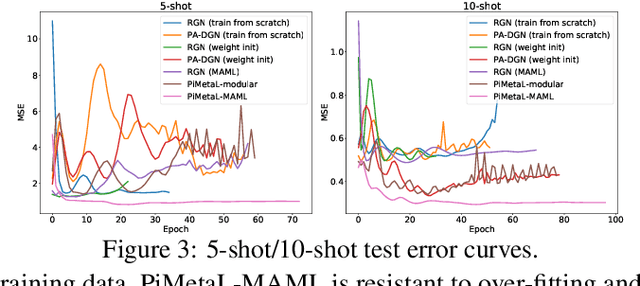
Modeling the dynamics of real-world physical systems is critical for spatiotemporal prediction tasks, but challenging when data is limited. The scarcity of real-world data and the difficulty in reproducing the data distribution hinder directly applying meta-learning techniques. Although the knowledge of governing partial differential equations (PDEs) of the data can be helpful for the fast adaptation to few observations, it is difficult to generalize to different or unknown dynamics. In this paper, we propose a framework, physics-aware modular meta-learning with auxiliary tasks (PiMetaL) whose spatial modules incorporate PDE-independent knowledge and temporal modules are rapidly adaptable to the limited data, respectively. The framework does not require the exact form of governing equations to model the observed spatiotemporal data. Furthermore, it mitigates the need for a large number of real-world tasks for meta-learning by leveraging simulated data. We apply the proposed framework to both synthetic and real-world spatiotemporal prediction tasks and demonstrate its superior performance with limited observations.
Coronavirus on Social Media: Analyzing Misinformation in Twitter Conversations
Apr 21, 2020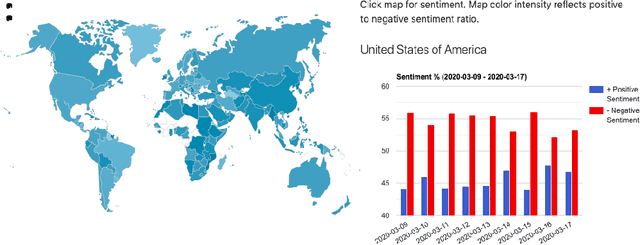
The ongoing Coronavirus Disease (COVID-19) pandemic highlights the interconnected-ness of our present-day globalized world. With social distancing policies in place, virtual communication has become an important source of (mis)information. As increasing number of people rely on social media platforms for news, identifying misinformation has emerged as a critical task in these unprecedented times. In addition to being malicious, the spread of such information poses a serious public health risk. To this end, we design a dashboard to track misinformation on popular social media news sharing platform - Twitter. The dashboard allows visibility into the social media discussions around Coronavirus and the quality of information shared on the platform, updated over time. We collect streaming data using the Twitter API from March 1, 2020 to date and identify false, misleading and clickbait contents from collected Tweets. We provide analysis of user accounts and misinformation spread across countries. In addition, we provide analysis of public sentiments on intervention policies such as "#socialdistancing" and "#workfromhome", and we track topics, and emerging hashtags and sentiments over countries. The dashboard maintains an evolving list of misinformation cascades, sentiments and emerging trends over time, accessible online at \url{https://usc-melady.github.io/COVID-19-Tweet-Analysis}.
Benchmark of Deep Learning Models on Large Healthcare MIMIC Datasets
Oct 23, 2017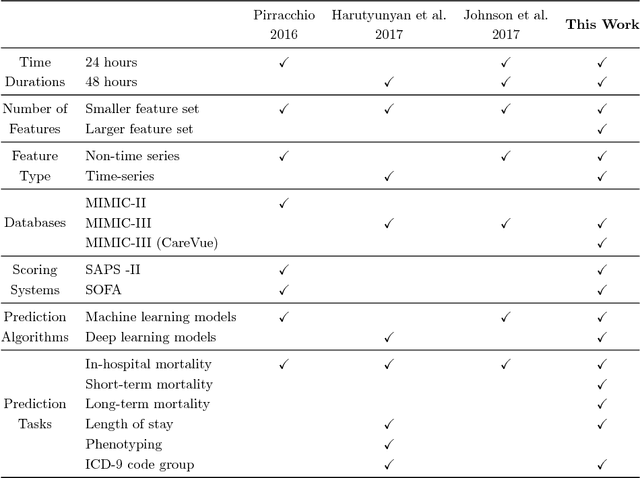
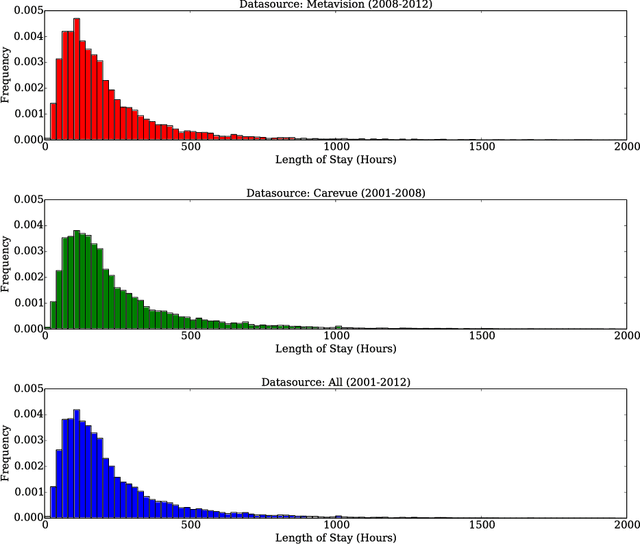
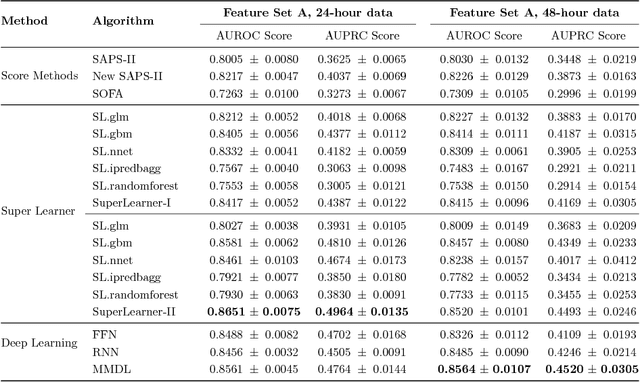
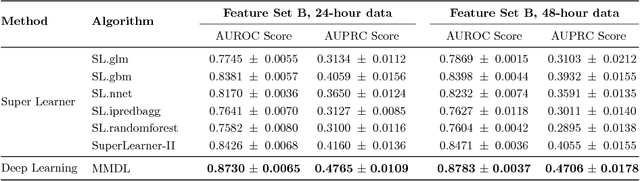
Deep learning models (aka Deep Neural Networks) have revolutionized many fields including computer vision, natural language processing, speech recognition, and is being increasingly used in clinical healthcare applications. However, few works exist which have benchmarked the performance of the deep learning models with respect to the state-of-the-art machine learning models and prognostic scoring systems on publicly available healthcare datasets. In this paper, we present the benchmarking results for several clinical prediction tasks such as mortality prediction, length of stay prediction, and ICD-9 code group prediction using Deep Learning models, ensemble of machine learning models (Super Learner algorithm), SAPS II and SOFA scores. We used the Medical Information Mart for Intensive Care III (MIMIC-III) (v1.4) publicly available dataset, which includes all patients admitted to an ICU at the Beth Israel Deaconess Medical Center from 2001 to 2012, for the benchmarking tasks. Our results show that deep learning models consistently outperform all the other approaches especially when the `raw' clinical time series data is used as input features to the models.