 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetadata Conditioning Accelerates Language Model Pre-training
Jan 03, 2025



The vast diversity of styles, domains, and quality levels present in language model pre-training corpora is essential in developing general model capabilities, but efficiently learning and deploying the correct behaviors exemplified in each of these heterogeneous data sources is challenging. To address this, we propose a new method, termed Metadata Conditioning then Cooldown (MeCo), to incorporate additional learning cues during pre-training. MeCo first provides metadata (e.g., URLs like en.wikipedia.org) alongside the text during training and later uses a cooldown phase with only the standard text, thereby enabling the model to function normally even without metadata. MeCo significantly accelerates pre-training across different model scales (600M to 8B parameters) and training sources (C4, RefinedWeb, and DCLM). For instance, a 1.6B language model trained with MeCo matches the downstream task performance of standard pre-training while using 33% less data. Additionally, MeCo enables us to steer language models by conditioning the inference prompt on either real or fabricated metadata that encodes the desired properties of the output: for example, prepending wikipedia.org to reduce harmful generations or factquizmaster.com (fabricated) to improve common knowledge task performance. We also demonstrate that MeCo is compatible with different types of metadata, such as model-generated topics. MeCo is remarkably simple, adds no computational overhead, and demonstrates promise in producing more capable and steerable language models.
AdaRank: Disagreement Based Module Rank Prediction for Low-rank Adaptation
Aug 16, 2024



With the rise of language and multimodal models of ever-increasing size, pretraining a general-purpose foundational model and adapting it to downstream tasks has become common practice. To this end, adaptation efficiency can be a critical bottleneck given the large model sizes, hence efficient finetuning methods such as LoRA have become prevalent. However, LoRA is typically applied with the same rank across all model layers, despite mounting evidence from transfer learning literature that during finetuning, later layers diverge more from pretrained weights. Inspired by the theory and observations around feature learning and module criticality, we develop a simple model disagreement based technique to predict the rank of a given module relative to the other modules. Empirically, AdaRank generalizes notably better on unseen data than using uniform ranks with the same number of parameters. Compared to prior work, AdaRank has the unique advantage of leaving the pretraining and adaptation stages completely intact: no need for any additional objectives or regularizers, which can hinder adaptation accuracy and performance. Our code is publicly available at https://github.com/google-research/google-research/tree/master/adaptive_low_rank.
Learned Feature Importance Scores for Automated Feature Engineering
Jun 06, 2024Feature engineering has demonstrated substantial utility for many machine learning workflows, such as in the small data regime or when distribution shifts are severe. Thus automating this capability can relieve much manual effort and improve model performance. Towards this, we propose AutoMAN, or Automated Mask-based Feature Engineering, an automated feature engineering framework that achieves high accuracy, low latency, and can be extended to heterogeneous and time-varying data. AutoMAN is based on effectively exploring the candidate transforms space, without explicitly manifesting transformed features. This is achieved by learning feature importance masks, which can be extended to support other modalities such as time series. AutoMAN learns feature transform importance end-to-end, incorporating a dataset's task target directly into feature engineering, resulting in state-of-the-art performance with significantly lower latency compared to alternatives.
COSTAR: Improved Temporal Counterfactual Estimation with Self-Supervised Learning
Nov 01, 2023



Estimation of temporal counterfactual outcomes from observed history is crucial for decision-making in many domains such as healthcare and e-commerce, particularly when randomized controlled trials (RCTs) suffer from high cost or impracticality. For real-world datasets, modeling time-dependent confounders is challenging due to complex dynamics, long-range dependencies and both past treatments and covariates affecting the future outcomes. In this paper, we introduce COunterfactual Self-supervised TrAnsformeR (COSTAR), a novel approach that integrates self-supervised learning for improved historical representations. The proposed framework combines temporal and feature-wise attention with a component-wise contrastive loss tailored for temporal treatment outcome observations, yielding superior performance in estimation accuracy and generalization to out-of-distribution data compared to existing models, as validated by empirical results on both synthetic and real-world datasets.
LANISTR: Multimodal Learning from Structured and Unstructured Data
May 26, 2023



Multimodal large-scale pretraining has shown impressive performance gains for unstructured data including language, image, audio, and video. Yet, the scenario most prominent in real-world applications is the existence of combination of structured (including tabular and time-series) and unstructured data, and this has so far been understudied. Towards this end, we propose LANISTR, a novel attention-based framework to learn from LANguage, Image, and STRuctured data. We introduce a new multimodal fusion module with a similarity-based multimodal masking loss that enables LANISTR to learn cross-modal relations from large-scale multimodal data with missing modalities during training and test time. On two publicly available challenging datasets, MIMIC-IV and Amazon Product Review, LANISTR achieves absolute improvements of 6.47% (AUROC) and up to 17.69% (accuracy), respectively, compared to the state-of-the-art multimodal models while showing superior generalization capabilities.
SLM: End-to-end Feature Selection via Sparse Learnable Masks
Apr 06, 2023



Feature selection has been widely used to alleviate compute requirements during training, elucidate model interpretability, and improve model generalizability. We propose SLM -- Sparse Learnable Masks -- a canonical approach for end-to-end feature selection that scales well with respect to both the feature dimension and the number of samples. At the heart of SLM lies a simple but effective learnable sparse mask, which learns which features to select, and gives rise to a novel objective that provably maximizes the mutual information (MI) between the selected features and the labels, which can be derived from a quadratic relaxation of mutual information from first principles. In addition, we derive a scaling mechanism that allows SLM to precisely control the number of features selected, through a novel use of sparsemax. This allows for more effective learning as demonstrated in ablation studies. Empirically, SLM achieves state-of-the-art results against a variety of competitive baselines on eight benchmark datasets, often by a significant margin, especially on those with real-world challenges such as class imbalance.
Koopman Neural Forecaster for Time Series with Temporal Distribution Shifts
Oct 10, 2022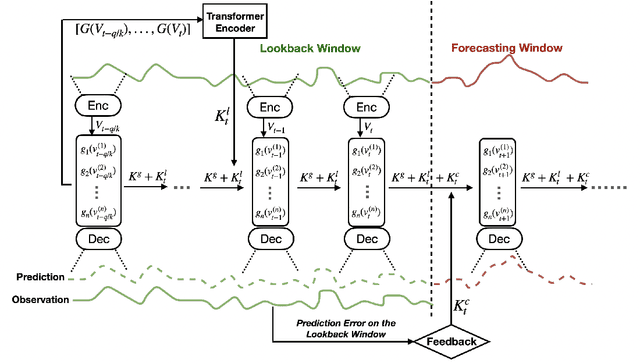

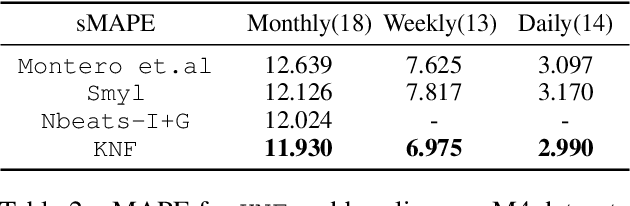
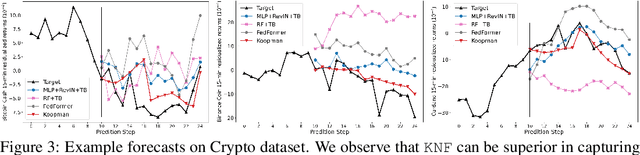
Temporal distributional shifts, with underlying dynamics changing over time, frequently occur in real-world time series, and pose a fundamental challenge for deep neural networks (DNNs). In this paper, we propose a novel deep sequence model based on the Koopman theory for time series forecasting: Koopman Neural Forecaster (KNF) that leverages DNNs to learn the linear Koopman space and the coefficients of chosen measurement functions. KNF imposes appropriate inductive biases for improved robustness against distributional shifts, employing both a global operator to learn shared characteristics, and a local operator to capture changing dynamics, as well as a specially-designed feedback loop to continuously update the learnt operators over time for rapidly varying behaviors. To the best of our knowledge, this is the first time that Koopman theory is applied to real-world chaotic time series without known governing laws. We demonstrate that KNF achieves the superior performance compared to the alternatives, on multiple time series datasets that are shown to suffer from distribution shifts.
Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth
Mar 05, 2021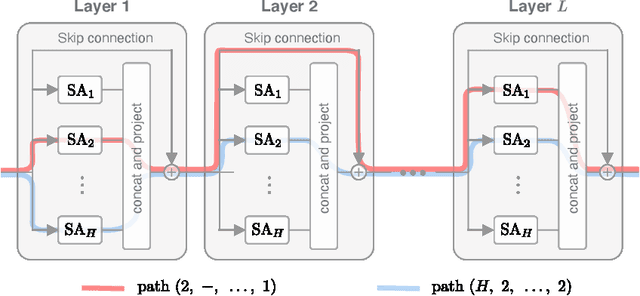
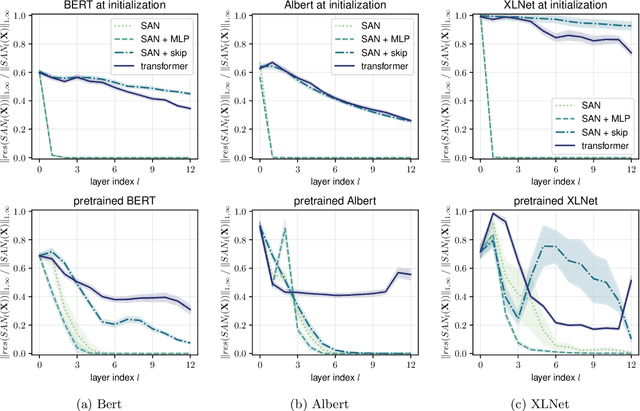
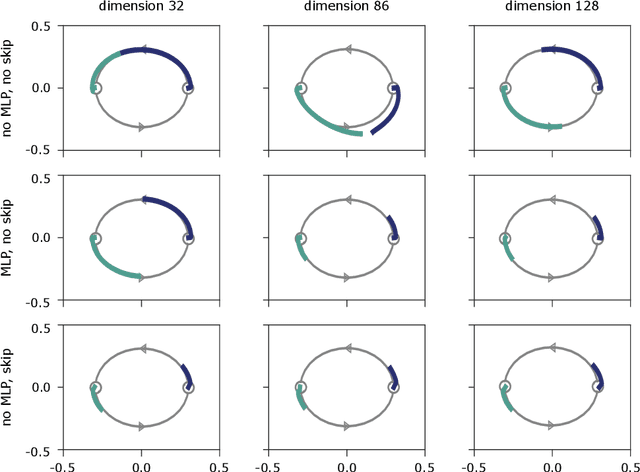
Attention-based architectures have become ubiquitous in machine learning, yet our understanding of the reasons for their effectiveness remains limited. This work proposes a new way to understand self-attention networks: we show that their output can be decomposed into a sum of smaller terms, each involving the operation of a sequence of attention heads across layers. Using this decomposition, we prove that self-attention possesses a strong inductive bias towards "token uniformity". Specifically, without skip connections or multi-layer perceptrons (MLPs), the output converges doubly exponentially to a rank-1 matrix. On the other hand, skip connections and MLPs stop the output from degeneration. Our experiments verify the identified convergence phenomena on different variants of standard transformer architectures.
HNHN: Hypergraph Networks with Hyperedge Neurons
Jun 22, 2020

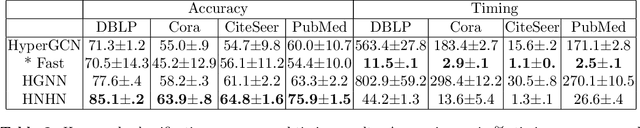

Hypergraphs provide a natural representation for many real world datasets. We propose a novel framework, HNHN, for hypergraph representation learning. HNHN is a hypergraph convolution network with nonlinear activation functions applied to both hypernodes and hyperedges, combined with a normalization scheme that can flexibly adjust the importance of high-cardinality hyperedges and high-degree vertices depending on the dataset. We demonstrate improved performance of HNHN in both classification accuracy and speed on real world datasets when compared to state of the art methods.
CoinPress: Practical Private Mean and Covariance Estimation
Jun 11, 2020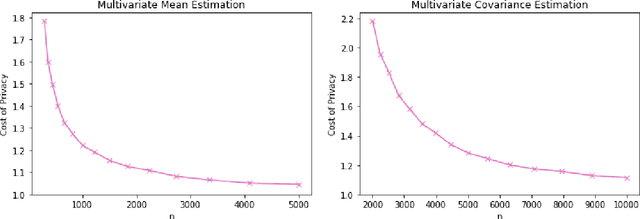
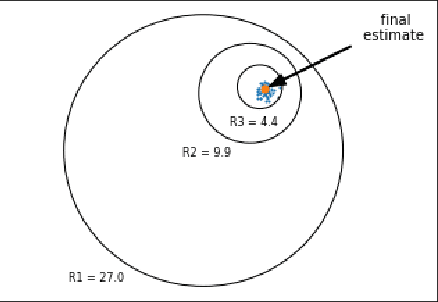
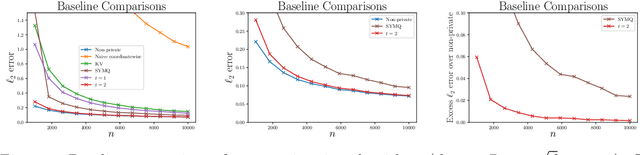
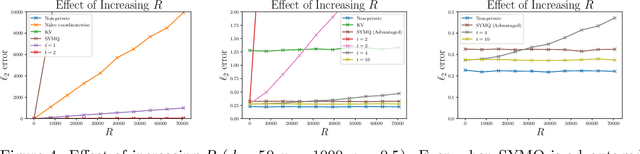
We present simple differentially private estimators for the mean and covariance of multivariate sub-Gaussian data that are accurate at small sample sizes. We demonstrate the effectiveness of our algorithms both theoretically and empirically using synthetic and real-world datasets---showing that their asymptotic error rates match the state-of-the-art theoretical bounds, and that they concretely outperform all previous methods. Specifically, previous estimators either have weak empirical accuracy at small sample sizes, perform poorly for multivariate data, or require the user to provide strong a priori estimates for the parameters.