 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Patch Selection for Image Recognition
Apr 07, 2021
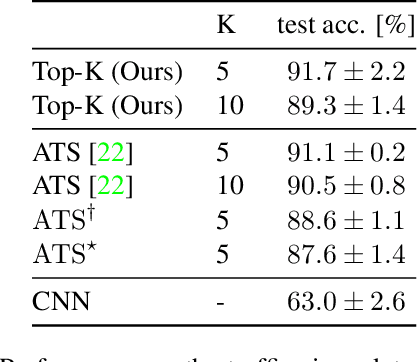
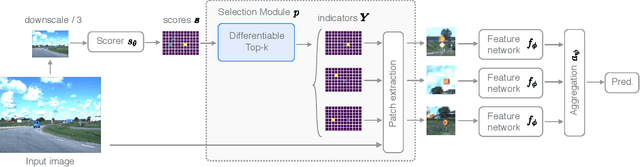
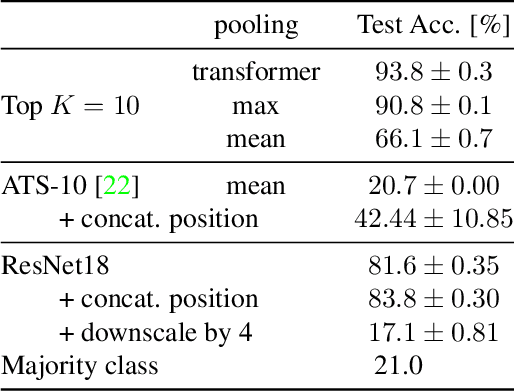
Neural Networks require large amounts of memory and compute to process high resolution images, even when only a small part of the image is actually informative for the task at hand. We propose a method based on a differentiable Top-K operator to select the most relevant parts of the input to efficiently process high resolution images. Our method may be interfaced with any downstream neural network, is able to aggregate information from different patches in a flexible way, and allows the whole model to be trained end-to-end using backpropagation. We show results for traffic sign recognition, inter-patch relationship reasoning, and fine-grained recognition without using object/part bounding box annotations during training.
Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth
Mar 05, 2021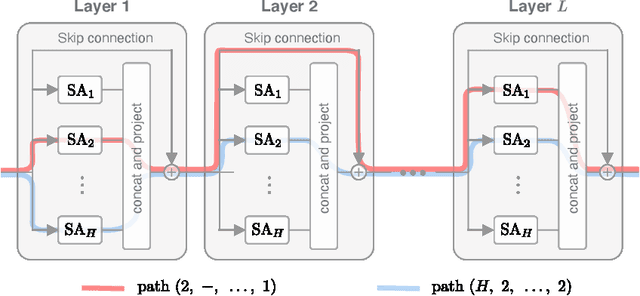
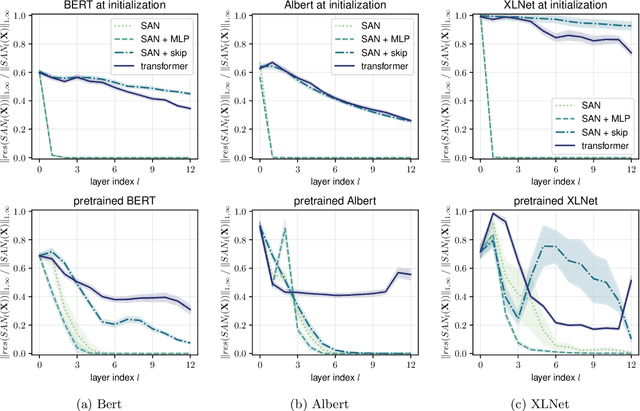
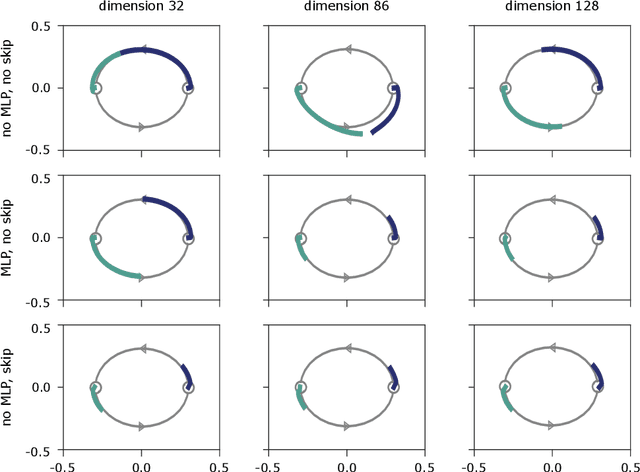
Attention-based architectures have become ubiquitous in machine learning, yet our understanding of the reasons for their effectiveness remains limited. This work proposes a new way to understand self-attention networks: we show that their output can be decomposed into a sum of smaller terms, each involving the operation of a sequence of attention heads across layers. Using this decomposition, we prove that self-attention possesses a strong inductive bias towards "token uniformity". Specifically, without skip connections or multi-layer perceptrons (MLPs), the output converges doubly exponentially to a rank-1 matrix. On the other hand, skip connections and MLPs stop the output from degeneration. Our experiments verify the identified convergence phenomena on different variants of standard transformer architectures.
Group Equivariant Stand-Alone Self-Attention For Vision
Oct 02, 2020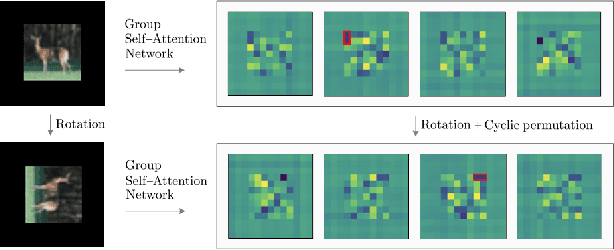
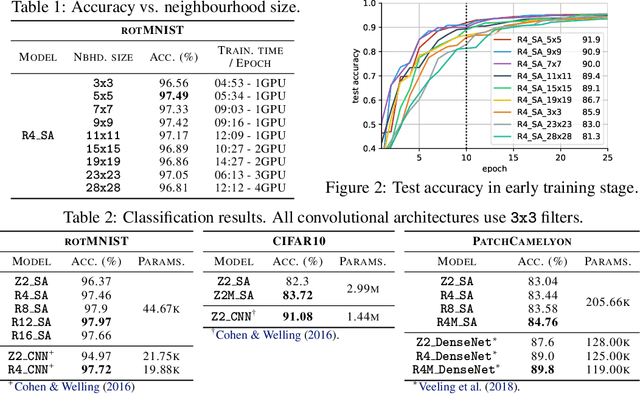
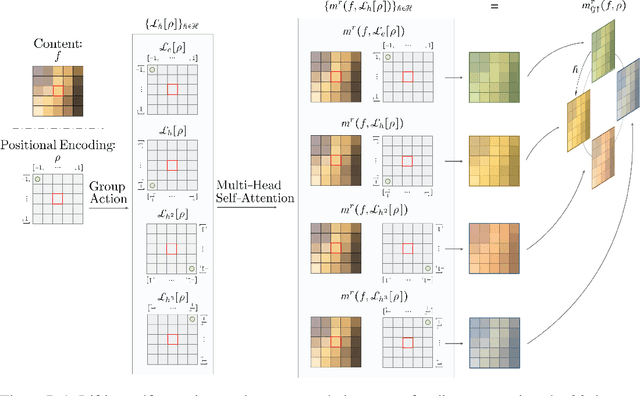
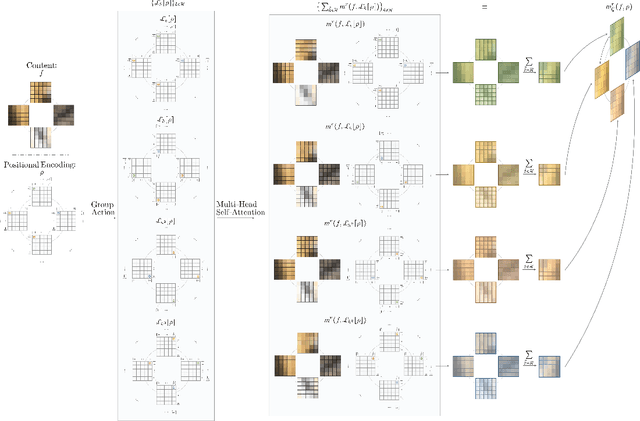
We provide a general self-attention formulation to impose group equivariance to arbitrary symmetry groups. This is achieved by defining positional encodings that are invariant to the action of the group considered. Since the group acts on the positional encoding directly, group equivariant self-attention networks (GSA-Nets) are steerable by nature. Our experiments on vision benchmarks demonstrate consistent improvements of GSA-Nets over non-equivariant self-attention networks.
Multi-Head Attention: Collaborate Instead of Concatenate
Jun 29, 2020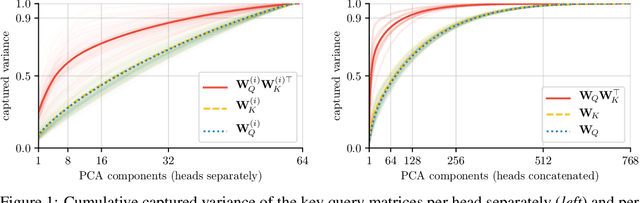
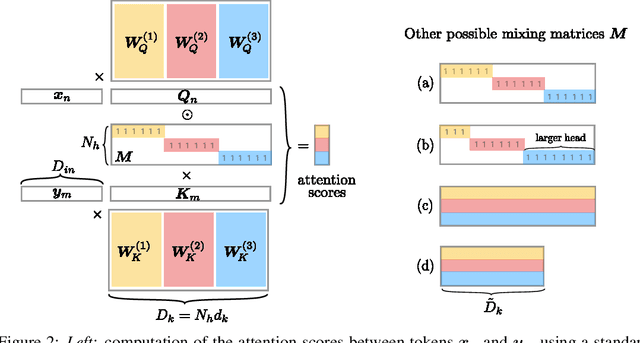

Attention layers are widely used in natural language processing (NLP) and are beginning to influence computer vision architectures. However, they suffer from over-parameterization. For instance, it was shown that the majority of attention heads could be pruned without impacting accuracy. This work aims to enhance current understanding on how multiple heads interact. Motivated by the observation that trained attention heads share common key/query projections, we propose a collaborative multi-head attention layer that enables heads to learn shared projections. Our scheme improves the computational cost and number of parameters in an attention layer and can be used as a drop-in replacement in any transformer architecture. For instance, by allowing heads to collaborate on a neural machine translation task, we can reduce the key dimension by a factor of eight without any loss in performance. We also show that it is possible to re-parametrize a pre-trained multi-head attention layer into our collaborative attention layer. Even without retraining, collaborative multi-head attention manages to reduce the size of the key and query projections by half without sacrificing accuracy. Our code is public.
Robust Cross-lingual Embeddings from Parallel Sentences
Dec 28, 2019
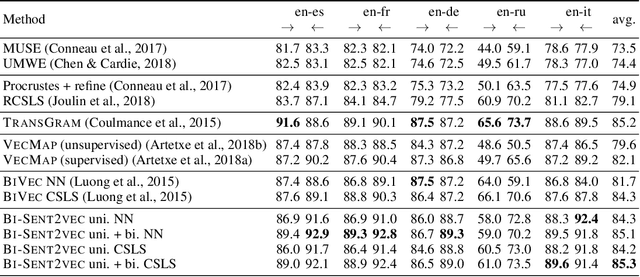
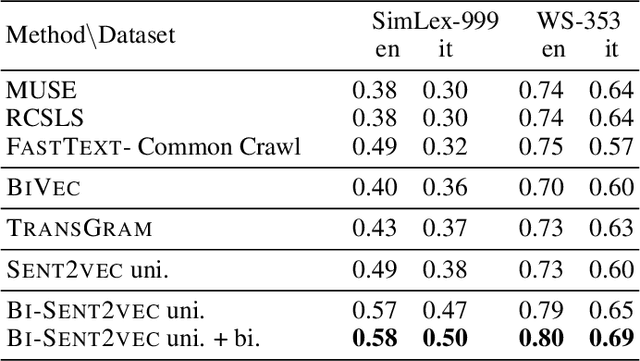

Recent advances in cross-lingual word embeddings have primarily relied on mapping-based methods, which project pretrained word embeddings from different languages into a shared space through a linear transformation. However, these approaches assume word embedding spaces are isomorphic between different languages, which has been shown not to hold in practice (S{\o}gaard et al., 2018), and fundamentally limits their performance. This motivates investigating joint learning methods which can overcome this impediment, by simultaneously learning embeddings across languages via a cross-lingual term in the training objective. Given the abundance of parallel data available (Tiedemann, 2012), we propose a bilingual extension of the CBOW method which leverages sentence-aligned corpora to obtain robust cross-lingual word and sentence representations. Our approach significantly improves cross-lingual sentence retrieval performance over all other approaches, as well as convincingly outscores mapping methods while maintaining parity with jointly trained methods on word-translation. It also achieves parity with a deep RNN method on a zero-shot cross-lingual document classification task, requiring far fewer computational resources for training and inference. As an additional advantage, our bilingual method also improves the quality of monolingual word vectors despite training on much smaller datasets. We make our code and models publicly available.
On the Relationship between Self-Attention and Convolutional Layers
Nov 08, 2019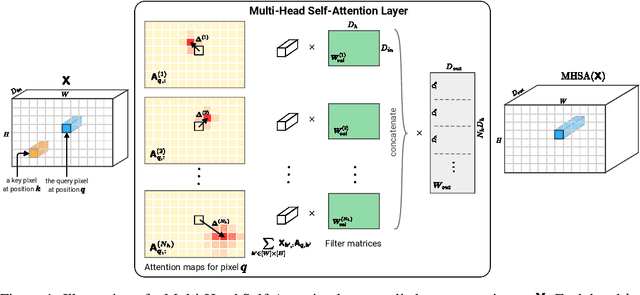
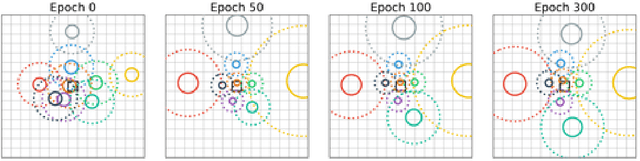

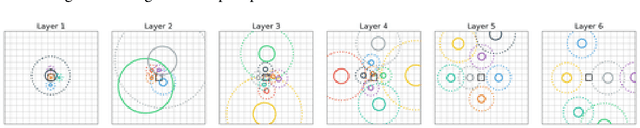
Recent trends of incorporating attention mechanisms in vision have led researchers to reconsider the supremacy of convolutional layers as a primary building block. Beyond helping CNNs to handle long-range dependencies, Ramachandran et al. (2019) showed that attention can completely replace convolution and achieve state-of-the-art performance on vision tasks. This raises the question: do learned attention layers operate similarly to convolutional layers? This work provides evidence that attention layers can perform convolution and, indeed, they often learn to do so in practice. Specifically, we prove that a multi-head self-attention layer with sufficient number of heads is at least as powerful as any convolutional layer. Our numerical experiments then show that the phenomenon also occurs in practice, corroborating our analysis. Our code is publicly available.
Extrapolating paths with graph neural networks
Mar 18, 2019

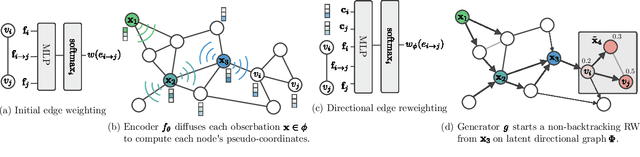
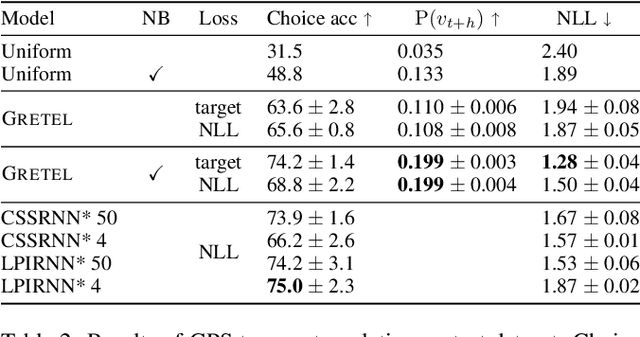
We consider the problem of path inference: given a path prefix, i.e., a partially observed sequence of nodes in a graph, we want to predict which nodes are in the missing suffix. In particular, we focus on natural paths occurring as a by-product of the interaction of an agent with a network---a driver on the transportation network, an information seeker in Wikipedia, or a client in an online shop. Our interest is sparked by the realization that, in contrast to shortest-path problems, natural paths are usually not optimal in any graph-theoretic sense, but might still follow predictable patterns. Our main contribution is a graph neural network called Gretel. Conditioned on a path prefix, this network can efficiently extrapolate path suffixes, evaluate path likelihood, and sample from the future path distribution. Our experiments with GPS traces on a road network and user-navigation paths in Wikipedia confirm that Gretel is able to adapt to graphs with very different properties, while also comparing favorably to previous solutions.
Sparsified SGD with Memory
Sep 20, 2018

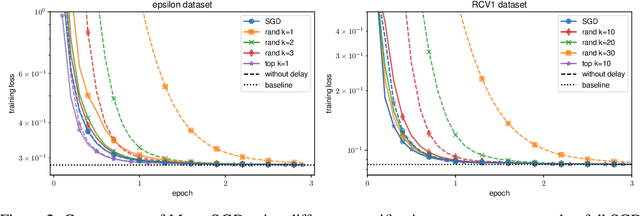

Huge scale machine learning problems are nowadays tackled by distributed optimization algorithms, i.e. algorithms that leverage the compute power of many devices for training. The communication overhead is a key bottleneck that hinders perfect scalability. Various recent works proposed to use quantization or sparsification techniques to reduce the amount of data that needs to be communicated, for instance by only sending the most significant entries of the stochastic gradient (top-k sparsification). Whilst such schemes showed very promising performance in practice, they have eluded theoretical analysis so far. In this work we analyze Stochastic Gradient Descent (SGD) with k-sparsification or compression (for instance top-k or random-k) and show that this scheme converges at the same rate as vanilla SGD when equipped with error compensation (keeping track of accumulated errors in memory). That is, communication can be reduced by a factor of the dimension of the problem (sometimes even more) whilst still converging at the same rate. We present numerical experiments to illustrate the theoretical findings and the better scalability for distributed applications.