 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Open-Vocabulary Object Detection with Vision Transformers
May 12, 2022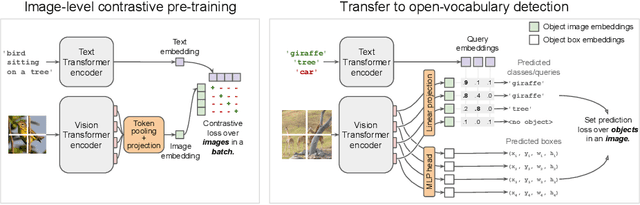
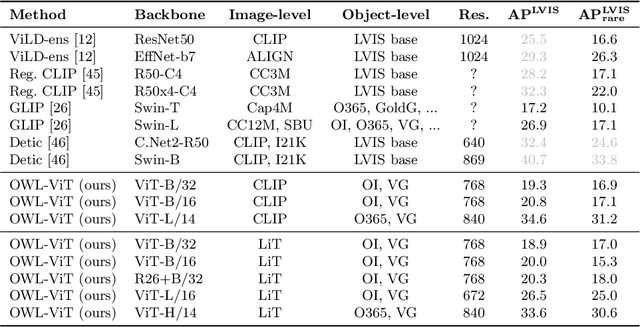
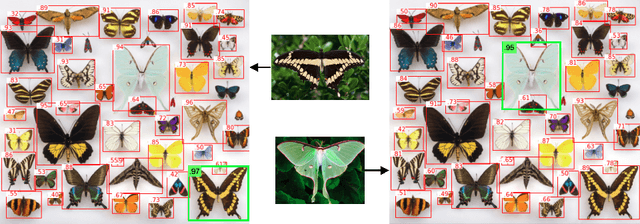
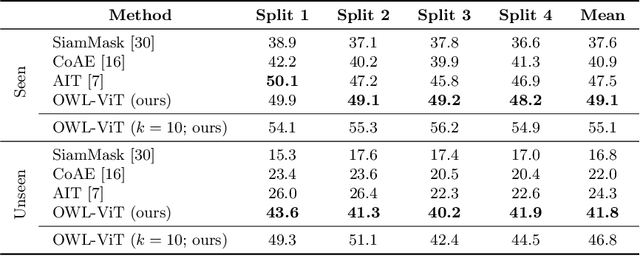
Combining simple architectures with large-scale pre-training has led to massive improvements in image classification. For object detection, pre-training and scaling approaches are less well established, especially in the long-tailed and open-vocabulary setting, where training data is relatively scarce. In this paper, we propose a strong recipe for transferring image-text models to open-vocabulary object detection. We use a standard Vision Transformer architecture with minimal modifications, contrastive image-text pre-training, and end-to-end detection fine-tuning. Our analysis of the scaling properties of this setup shows that increasing image-level pre-training and model size yield consistent improvements on the downstream detection task. We provide the adaptation strategies and regularizations needed to attain very strong performance on zero-shot text-conditioned and one-shot image-conditioned object detection. Code and models are available on GitHub.
Differentiable Patch Selection for Image Recognition
Apr 07, 2021
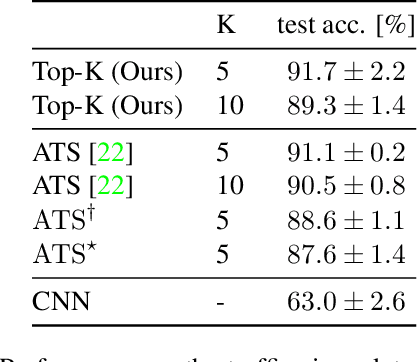
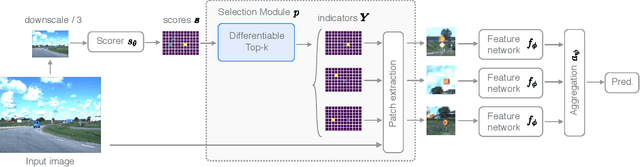
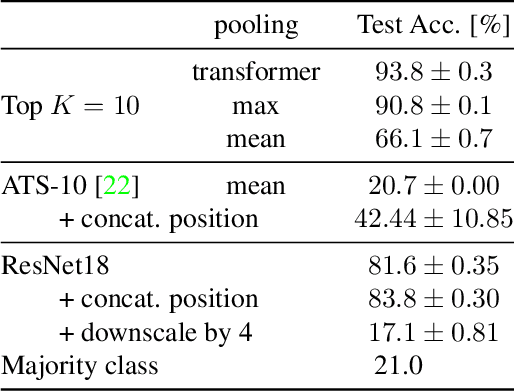
Neural Networks require large amounts of memory and compute to process high resolution images, even when only a small part of the image is actually informative for the task at hand. We propose a method based on a differentiable Top-K operator to select the most relevant parts of the input to efficiently process high resolution images. Our method may be interfaced with any downstream neural network, is able to aggregate information from different patches in a flexible way, and allows the whole model to be trained end-to-end using backpropagation. We show results for traffic sign recognition, inter-patch relationship reasoning, and fine-grained recognition without using object/part bounding box annotations during training.
Colorization Transformer
Mar 07, 2021

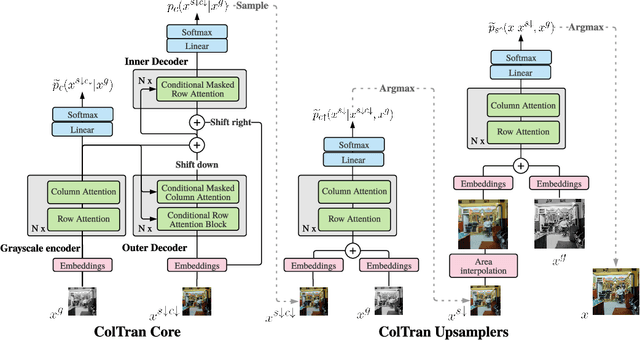
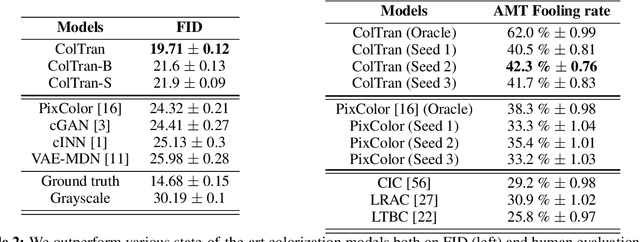
We present the Colorization Transformer, a novel approach for diverse high fidelity image colorization based on self-attention. Given a grayscale image, the colorization proceeds in three steps. We first use a conditional autoregressive transformer to produce a low resolution coarse coloring of the grayscale image. Our architecture adopts conditional transformer layers to effectively condition grayscale input. Two subsequent fully parallel networks upsample the coarse colored low resolution image into a finely colored high resolution image. Sampling from the Colorization Transformer produces diverse colorings whose fidelity outperforms the previous state-of-the-art on colorising ImageNet based on FID results and based on a human evaluation in a Mechanical Turk test. Remarkably, in more than 60% of cases human evaluators prefer the highest rated among three generated colorings over the ground truth. The code and pre-trained checkpoints for Colorization Transformer are publicly available at https://github.com/google-research/google-research/tree/master/coltran
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Oct 22, 2020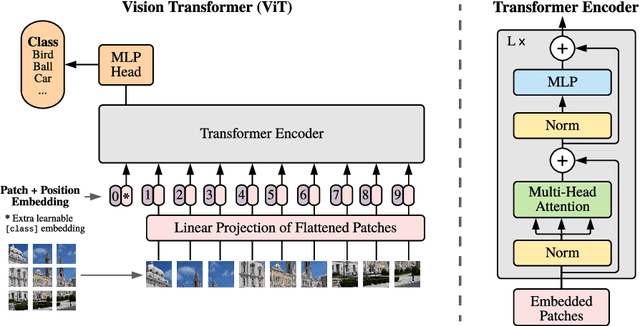

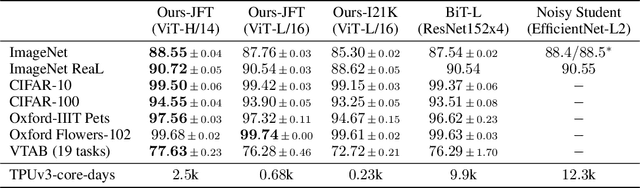
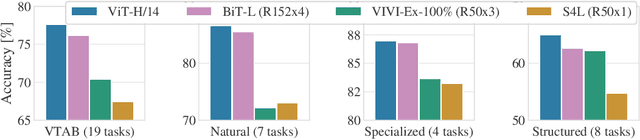
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
Object-Centric Learning with Slot Attention
Jun 26, 2020Learning object-centric representations of complex scenes is a promising step towards enabling efficient abstract reasoning from low-level perceptual features. Yet, most deep learning approaches learn distributed representations that do not capture the compositional properties of natural scenes. In this paper, we present the Slot Attention module, an architectural component that interfaces with perceptual representations such as the output of a convolutional neural network and produces a set of task-dependent abstract representations which we call slots. These slots are exchangeable and can bind to any object in the input by specializing through a competitive procedure over multiple rounds of attention. We empirically demonstrate that Slot Attention can extract object-centric representations that enable generalization to unseen compositions when trained on unsupervised object discovery and supervised property prediction tasks.
Axial Attention in Multidimensional Transformers
Dec 20, 2019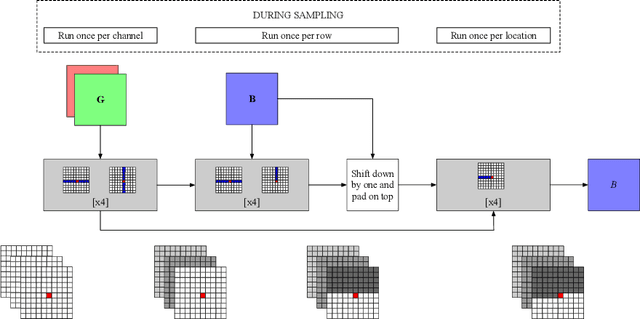

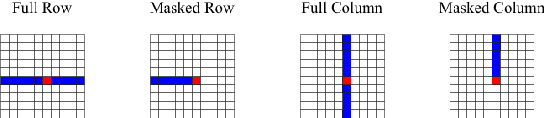
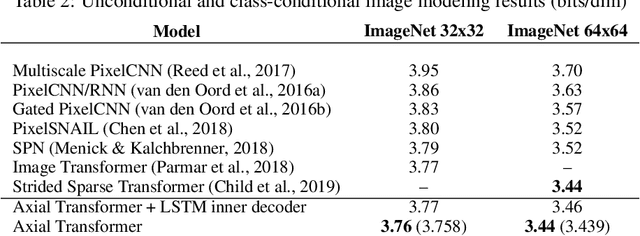
We propose Axial Transformers, a self-attention-based autoregressive model for images and other data organized as high dimensional tensors. Existing autoregressive models either suffer from excessively large computational resource requirements for high dimensional data, or make compromises in terms of distribution expressiveness or ease of implementation in order to decrease resource requirements. Our architecture, by contrast, maintains both full expressiveness over joint distributions over data and ease of implementation with standard deep learning frameworks, while requiring reasonable memory and computation and achieving state-of-the-art results on standard generative modeling benchmarks. Our models are based on axial attention, a simple generalization of self-attention that naturally aligns with the multiple dimensions of the tensors in both the encoding and the decoding settings. Notably the proposed structure of the layers allows for the vast majority of the context to be computed in parallel during decoding without introducing any independence assumptions. This semi-parallel structure goes a long way to making decoding from even a very large Axial Transformer broadly applicable. We demonstrate state-of-the-art results for the Axial Transformer on the ImageNet-32 and ImageNet-64 image benchmarks as well as on the BAIR Robotic Pushing video benchmark. We open source the implementation of Axial Transformers.
Scaling Autoregressive Video Models
Jun 06, 2019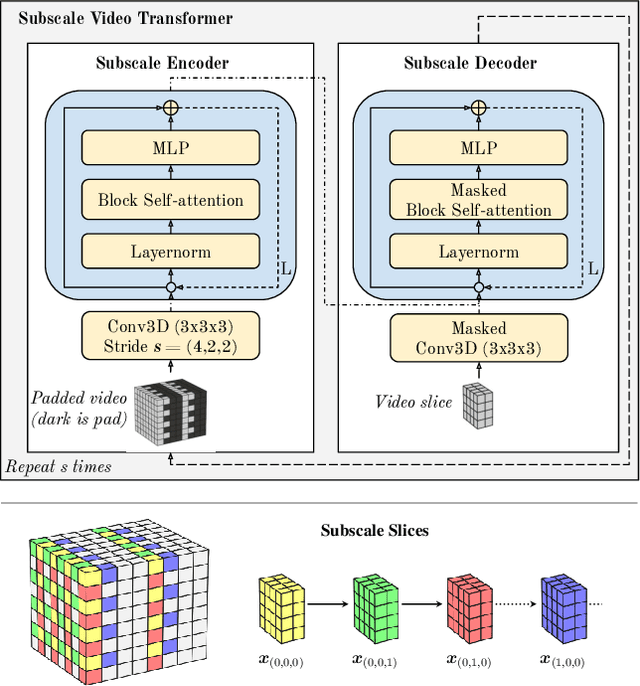

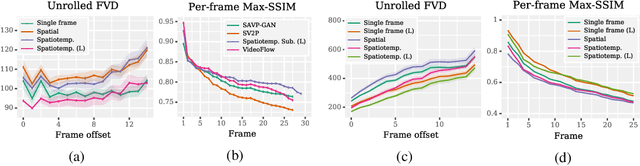

Due to the statistical complexity of video, the high degree of inherent stochasticity, and the sheer amount of data, generating natural video remains a challenging task. State-of-the-art video generation models attempt to address these issues by combining sometimes complex, often video-specific neural network architectures, latent variable models, adversarial training and a range of other methods. Despite their often high complexity, these approaches still fall short of generating high quality video continuations outside of narrow domains and often struggle with fidelity. In contrast, we show that conceptually simple, autoregressive video generation models based on a three-dimensional self-attention mechanism achieve highly competitive results across multiple metrics on popular benchmark datasets for which they produce continuations of high fidelity and realism. Furthermore, we find that our models are capable of producing diverse and surprisingly realistic continuations on a subset of videos from Kinetics, a large scale action recognition dataset comprised of YouTube videos exhibiting phenomena such as camera movement, complex object interactions and diverse human movement. To our knowledge, this is the first promising application of video-generation models to videos of this complexity.
Dynamic Integration of Background Knowledge in Neural NLU Systems
Aug 21, 2018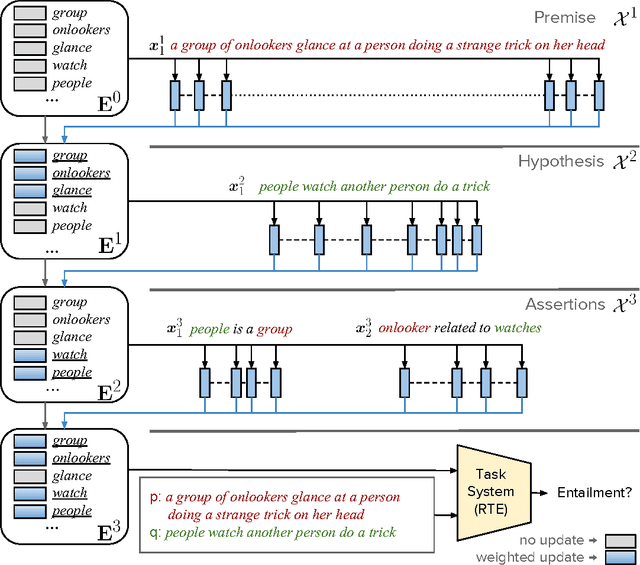
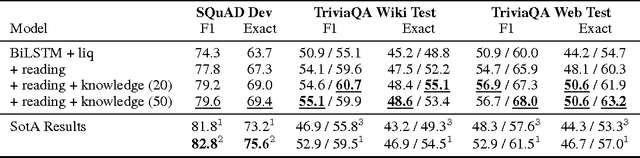
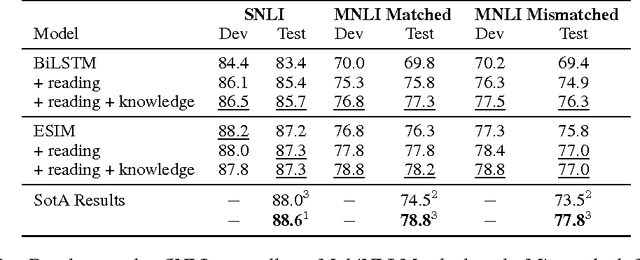
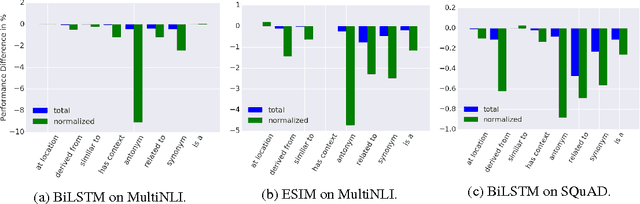
Common-sense and background knowledge is required to understand natural language, but in most neural natural language understanding (NLU) systems, this knowledge must be acquired from training corpora during learning, and then it is static at test time. We introduce a new architecture for the dynamic integration of explicit background knowledge in NLU models. A general-purpose reading module reads background knowledge in the form of free-text statements (together with task-specific text inputs) and yields refined word representations to a task-specific NLU architecture that reprocesses the task inputs with these representations. Experiments on document question answering (DQA) and recognizing textual entailment (RTE) demonstrate the effectiveness and flexibility of the approach. Analysis shows that our model learns to exploit knowledge in a semantically appropriate way.
Jack the Reader - A Machine Reading Framework
Jun 20, 2018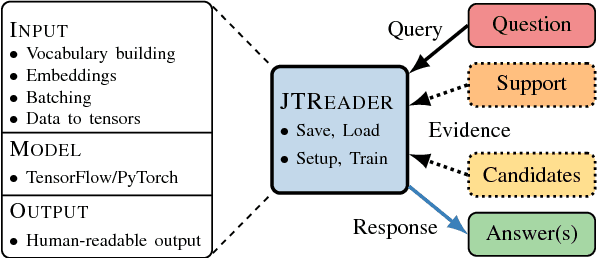
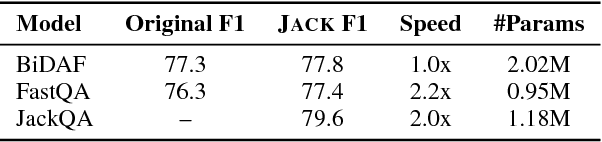

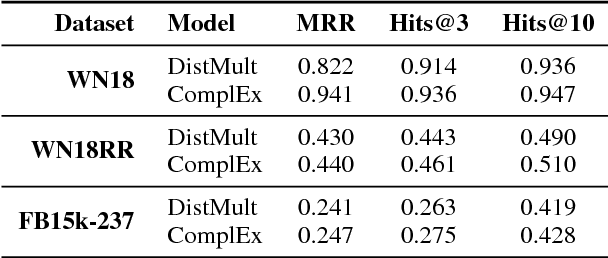
Many Machine Reading and Natural Language Understanding tasks require reading supporting text in order to answer questions. For example, in Question Answering, the supporting text can be newswire or Wikipedia articles; in Natural Language Inference, premises can be seen as the supporting text and hypotheses as questions. Providing a set of useful primitives operating in a single framework of related tasks would allow for expressive modelling, and easier model comparison and replication. To that end, we present Jack the Reader (Jack), a framework for Machine Reading that allows for quick model prototyping by component reuse, evaluation of new models on existing datasets as well as integrating new datasets and applying them on a growing set of implemented baseline models. Jack is currently supporting (but not limited to) three tasks: Question Answering, Natural Language Inference, and Link Prediction. It is developed with the aim of increasing research efficiency and code reuse.
Cross-lingual Candidate Search for Biomedical Concept Normalization
May 04, 2018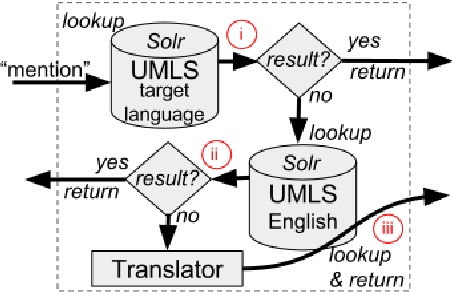
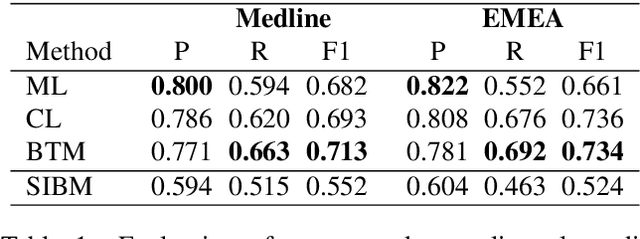
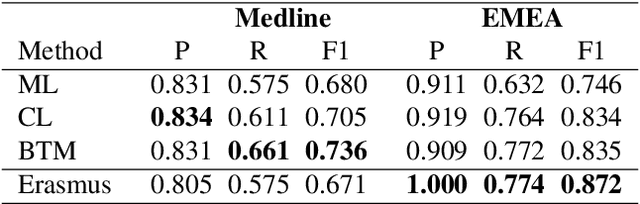

Biomedical concept normalization links concept mentions in texts to a semantically equivalent concept in a biomedical knowledge base. This task is challenging as concepts can have different expressions in natural languages, e.g. paraphrases, which are not necessarily all present in the knowledge base. Concept normalization of non-English biomedical text is even more challenging as non-English resources tend to be much smaller and contain less synonyms. To overcome the limitations of non-English terminologies we propose a cross-lingual candidate search for concept normalization using a character-based neural translation model trained on a multilingual biomedical terminology. Our model is trained with Spanish, French, Dutch and German versions of UMLS. The evaluation of our model is carried out on the French Quaero corpus, showing that it outperforms most teams of CLEF eHealth 2015 and 2016. Additionally, we compare performance to commercial translators on Spanish, French, Dutch and German versions of Mantra. Our model performs similarly well, but is free of charge and can be run locally. This is particularly important for clinical NLP applications as medical documents underlay strict privacy restrictions.