 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo OWL-ViT: Temporally-consistent open-world localization in video
Aug 22, 2023We present an architecture and a training recipe that adapts pre-trained open-world image models to localization in videos. Understanding the open visual world (without being constrained by fixed label spaces) is crucial for many real-world vision tasks. Contrastive pre-training on large image-text datasets has recently led to significant improvements for image-level tasks. For more structured tasks involving object localization applying pre-trained models is more challenging. This is particularly true for video tasks, where task-specific data is limited. We show successful transfer of open-world models by building on the OWL-ViT open-vocabulary detection model and adapting it to video by adding a transformer decoder. The decoder propagates object representations recurrently through time by using the output tokens for one frame as the object queries for the next. Our model is end-to-end trainable on video data and enjoys improved temporal consistency compared to tracking-by-detection baselines, while retaining the open-world capabilities of the backbone detector. We evaluate our model on the challenging TAO-OW benchmark and demonstrate that open-world capabilities, learned from large-scale image-text pre-training, can be transferred successfully to open-world localization across diverse videos.
Conditional Object-Centric Learning from Video
Nov 24, 2021

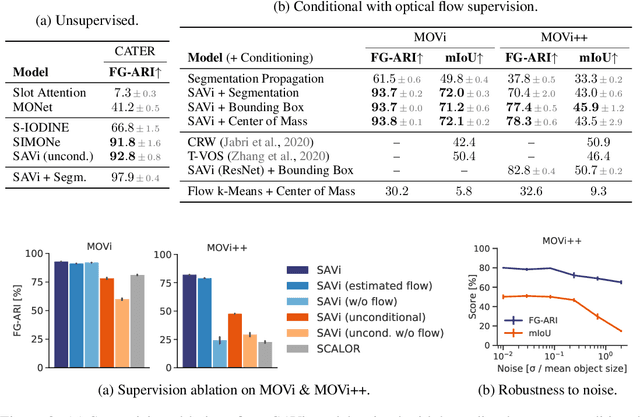

Object-centric representations are a promising path toward more systematic generalization by providing flexible abstractions upon which compositional world models can be built. Recent work on simple 2D and 3D datasets has shown that models with object-centric inductive biases can learn to segment and represent meaningful objects from the statistical structure of the data alone without the need for any supervision. However, such fully-unsupervised methods still fail to scale to diverse realistic data, despite the use of increasingly complex inductive biases such as priors for the size of objects or the 3D geometry of the scene. In this paper, we instead take a weakly-supervised approach and focus on how 1) using the temporal dynamics of video data in the form of optical flow and 2) conditioning the model on simple object location cues can be used to enable segmenting and tracking objects in significantly more realistic synthetic data. We introduce a sequential extension to Slot Attention which we train to predict optical flow for realistic looking synthetic scenes and show that conditioning the initial state of this model on a small set of hints, such as center of mass of objects in the first frame, is sufficient to significantly improve instance segmentation. These benefits generalize beyond the training distribution to novel objects, novel backgrounds, and to longer video sequences. We also find that such initial-state-conditioning can be used during inference as a flexible interface to query the model for specific objects or parts of objects, which could pave the way for a range of weakly-supervised approaches and allow more effective interaction with trained models.
ViViT: A Video Vision Transformer
Mar 29, 2021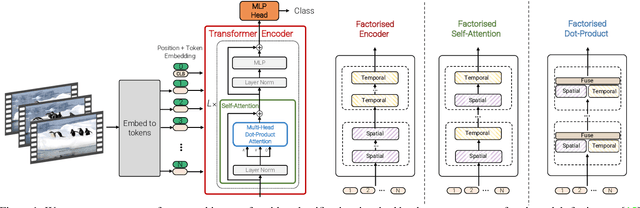

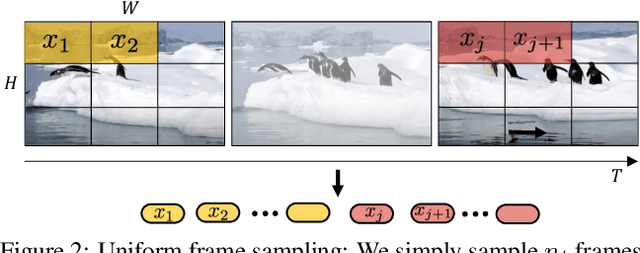

We present pure-transformer based models for video classification, drawing upon the recent success of such models in image classification. Our model extracts spatio-temporal tokens from the input video, which are then encoded by a series of transformer layers. In order to handle the long sequences of tokens encountered in video, we propose several, efficient variants of our model which factorise the spatial- and temporal-dimensions of the input. Although transformer-based models are known to only be effective when large training datasets are available, we show how we can effectively regularise the model during training and leverage pretrained image models to be able to train on comparatively small datasets. We conduct thorough ablation studies, and achieve state-of-the-art results on multiple video classification benchmarks including Kinetics 400 and 600, Epic Kitchens, Something-Something v2 and Moments in Time, outperforming prior methods based on deep 3D convolutional networks. To facilitate further research, we will release code and models.
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Oct 22, 2020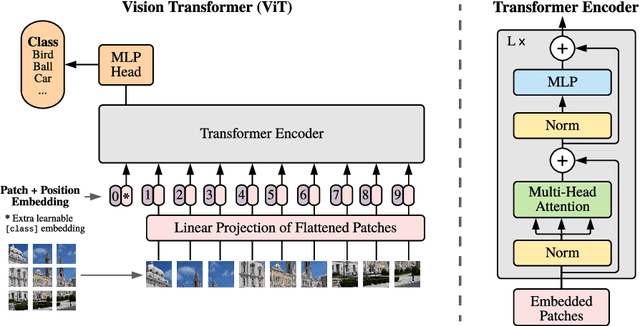

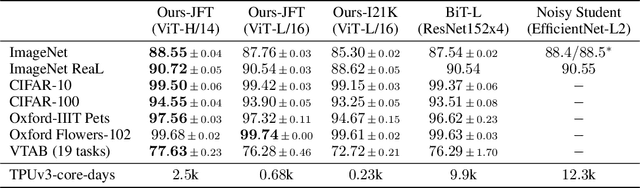
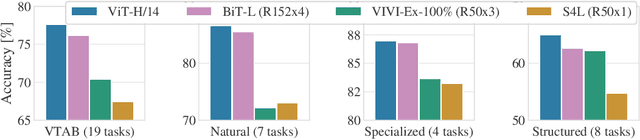
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
Object-Centric Learning with Slot Attention
Jun 26, 2020Learning object-centric representations of complex scenes is a promising step towards enabling efficient abstract reasoning from low-level perceptual features. Yet, most deep learning approaches learn distributed representations that do not capture the compositional properties of natural scenes. In this paper, we present the Slot Attention module, an architectural component that interfaces with perceptual representations such as the output of a convolutional neural network and produces a set of task-dependent abstract representations which we call slots. These slots are exchangeable and can bind to any object in the input by specializing through a competitive procedure over multiple rounds of attention. We empirically demonstrate that Slot Attention can extract object-centric representations that enable generalization to unseen compositions when trained on unsupervised object discovery and supervised property prediction tasks.
Cross-lingual, Character-Level Neural Morphological Tagging
Aug 30, 2017

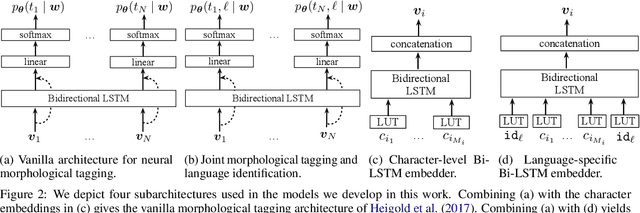
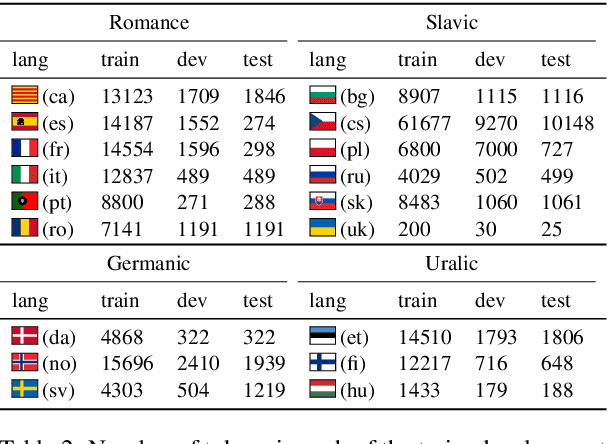
Even for common NLP tasks, sufficient supervision is not available in many languages -- morphological tagging is no exception. In the work presented here, we explore a transfer learning scheme, whereby we train character-level recurrent neural taggers to predict morphological taggings for high-resource languages and low-resource languages together. Learning joint character representations among multiple related languages successfully enables knowledge transfer from the high-resource languages to the low-resource ones, improving accuracy by up to 30%
Neural Morphological Tagging from Characters for Morphologically Rich Languages
Jun 21, 2016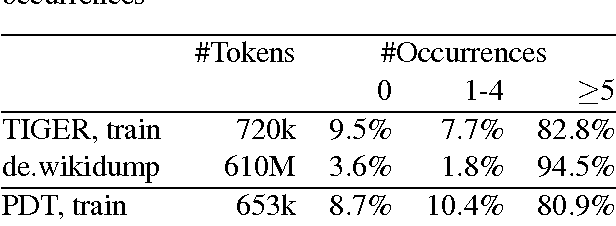

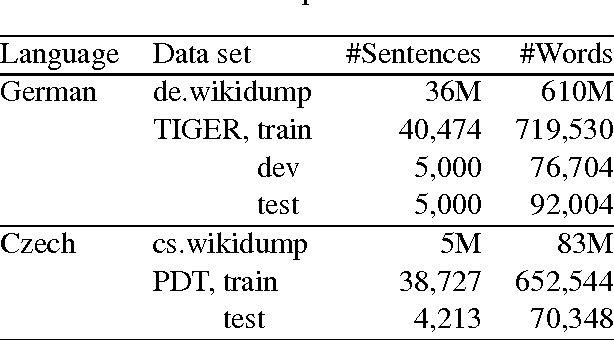
This paper investigates neural character-based morphological tagging for languages with complex morphology and large tag sets. We systematically explore a variety of neural architectures (DNN, CNN, CNNHighway, LSTM, BLSTM) to obtain character-based word vectors combined with bidirectional LSTMs to model across-word context in an end-to-end setting. We explore supplementary use of word-based vectors trained on large amounts of unlabeled data. Our experiments for morphological tagging suggest that for "simple" model configurations, the choice of the network architecture (CNN vs. CNNHighway vs. LSTM vs. BLSTM) or the augmentation with pre-trained word embeddings can be important and clearly impact the accuracy. Increasing the model capacity by adding depth, for example, and carefully optimizing the neural networks can lead to substantial improvements, and the differences in accuracy (but not training time) become much smaller or even negligible. Overall, our best morphological taggers for German and Czech outperform the best results reported in the literature by a large margin.
End-to-End Text-Dependent Speaker Verification
Sep 27, 2015
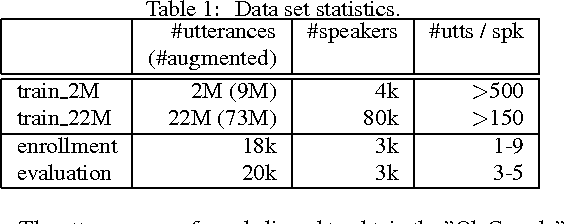
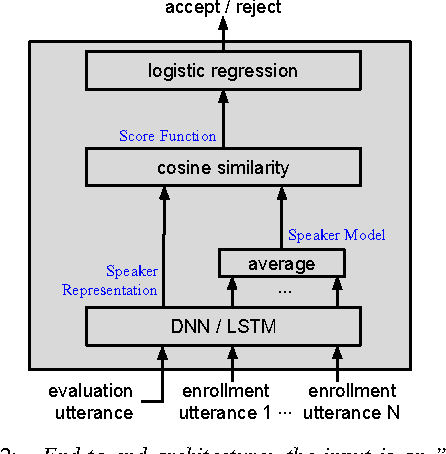

In this paper we present a data-driven, integrated approach to speaker verification, which maps a test utterance and a few reference utterances directly to a single score for verification and jointly optimizes the system's components using the same evaluation protocol and metric as at test time. Such an approach will result in simple and efficient systems, requiring little domain-specific knowledge and making few model assumptions. We implement the idea by formulating the problem as a single neural network architecture, including the estimation of a speaker model on only a few utterances, and evaluate it on our internal "Ok Google" benchmark for text-dependent speaker verification. The proposed approach appears to be very effective for big data applications like ours that require highly accurate, easy-to-maintain systems with a small footprint.