 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSI-Score: An image dataset for fine-grained analysis of robustness to object location, rotation and size
Apr 09, 2021

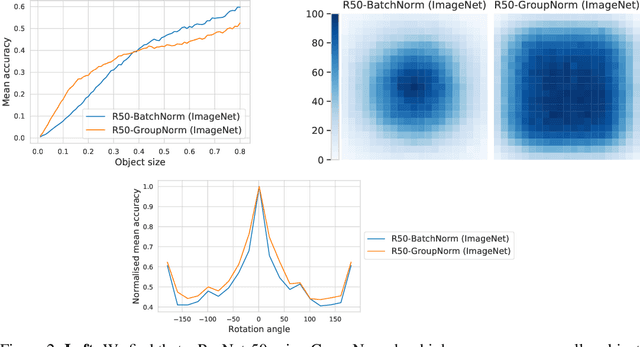

Before deploying machine learning models it is critical to assess their robustness. In the context of deep neural networks for image understanding, changing the object location, rotation and size may affect the predictions in non-trivial ways. In this work we perform a fine-grained analysis of robustness with respect to these factors of variation using SI-Score, a synthetic dataset. In particular, we investigate ResNets, Vision Transformers and CLIP, and identify interesting qualitative differences between these.
Comparing Transfer and Meta Learning Approaches on a Unified Few-Shot Classification Benchmark
Apr 06, 2021
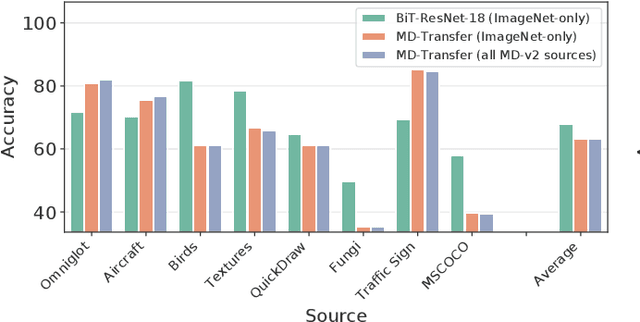

Meta and transfer learning are two successful families of approaches to few-shot learning. Despite highly related goals, state-of-the-art advances in each family are measured largely in isolation of each other. As a result of diverging evaluation norms, a direct or thorough comparison of different approaches is challenging. To bridge this gap, we perform a cross-family study of the best transfer and meta learners on both a large-scale meta-learning benchmark (Meta-Dataset, MD), and a transfer learning benchmark (Visual Task Adaptation Benchmark, VTAB). We find that, on average, large-scale transfer methods (Big Transfer, BiT) outperform competing approaches on MD, even when trained only on ImageNet. In contrast, meta-learning approaches struggle to compete on VTAB when trained and validated on MD. However, BiT is not without limitations, and pushing for scale does not improve performance on highly out-of-distribution MD tasks. In performing this study, we reveal a number of discrepancies in evaluation norms and study some of these in light of the performance gap. We hope that this work facilitates sharing of insights from each community, and accelerates progress on few-shot learning.
A Sober Look at the Unsupervised Learning of Disentangled Representations and their Evaluation
Oct 27, 2020



The idea behind the \emph{unsupervised} learning of \emph{disentangled} representations is that real-world data is generated by a few explanatory factors of variation which can be recovered by unsupervised learning algorithms. In this paper, we provide a sober look at recent progress in the field and challenge some common assumptions. We first theoretically show that the unsupervised learning of disentangled representations is fundamentally impossible without inductive biases on both the models and the data. Then, we train over $14000$ models covering most prominent methods and evaluation metrics in a reproducible large-scale experimental study on eight data sets. We observe that while the different methods successfully enforce properties "encouraged" by the corresponding losses, well-disentangled models seemingly cannot be identified without supervision. Furthermore, different evaluation metrics do not always agree on what should be considered "disentangled" and exhibit systematic differences in the estimation. Finally, increased disentanglement does not seem to necessarily lead to a decreased sample complexity of learning for downstream tasks. Our results suggest that future work on disentanglement learning should be explicit about the role of inductive biases and (implicit) supervision, investigate concrete benefits of enforcing disentanglement of the learned representations, and consider a reproducible experimental setup covering several data sets.
* arXiv admin note: substantial text overlap with arXiv:1811.12359
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Oct 22, 2020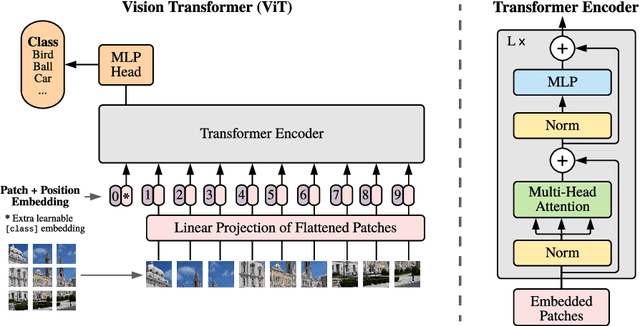

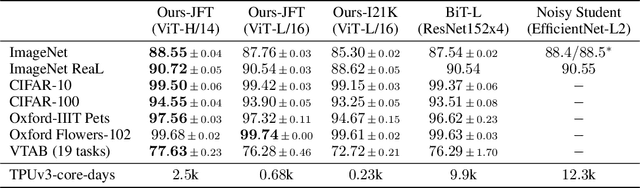
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
Scalable Transfer Learning with Expert Models
Sep 28, 2020
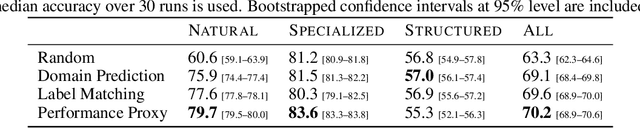
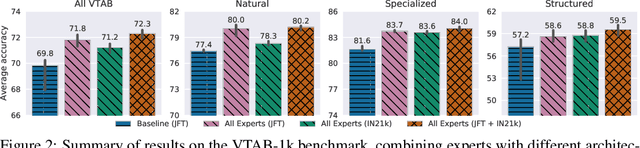

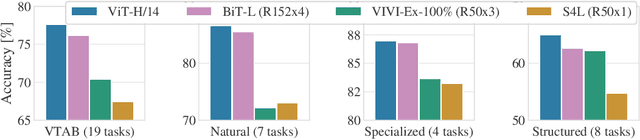
Transfer of pre-trained representations can improve sample efficiency and reduce computational requirements for new tasks. However, representations used for transfer are usually generic, and are not tailored to a particular distribution of downstream tasks. We explore the use of expert representations for transfer with a simple, yet effective, strategy. We train a diverse set of experts by exploiting existing label structures, and use cheap-to-compute performance proxies to select the relevant expert for each target task. This strategy scales the process of transferring to new tasks, since it does not revisit the pre-training data during transfer. Accordingly, it requires little extra compute per target task, and results in a speed-up of 2-3 orders of magnitude compared to competing approaches. Further, we provide an adapter-based architecture able to compress many experts into a single model. We evaluate our approach on two different data sources and demonstrate that it outperforms baselines on over 20 diverse vision tasks in both cases.
A Commentary on the Unsupervised Learning of Disentangled Representations
Jul 28, 2020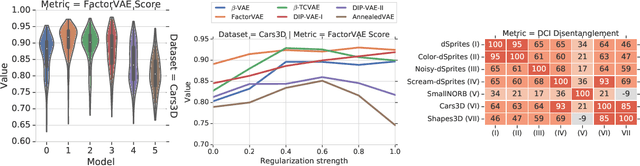
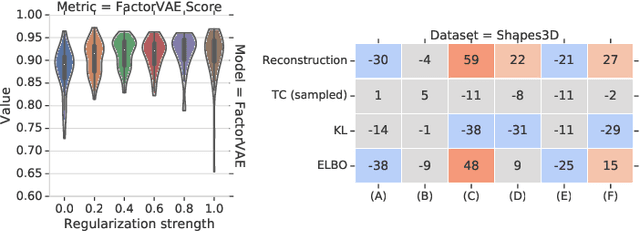
The goal of the unsupervised learning of disentangled representations is to separate the independent explanatory factors of variation in the data without access to supervision. In this paper, we summarize the results of Locatello et al., 2019, and focus on their implications for practitioners. We discuss the theoretical result showing that the unsupervised learning of disentangled representations is fundamentally impossible without inductive biases and the practical challenges it entails. Finally, we comment on our experimental findings, highlighting the limitations of state-of-the-art approaches and directions for future research.
What Do Neural Networks Learn When Trained With Random Labels?
Jun 18, 2020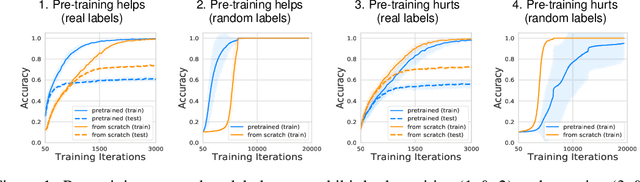
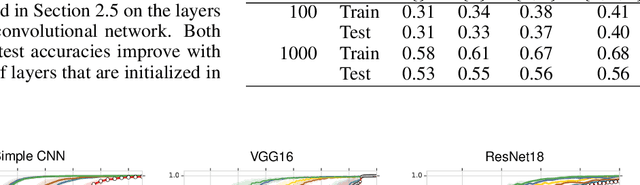
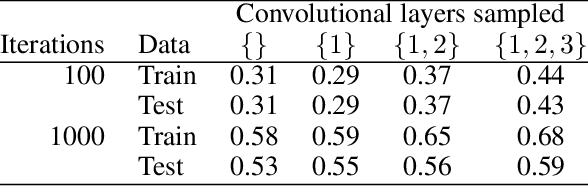
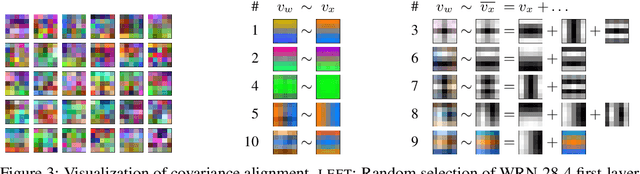
We study deep neural networks (DNNs) trained on natural image data with entirely random labels. Despite its popularity in the literature, where it is often used to study memorization, generalization, and other phenomena, little is known about what DNNs learn in this setting. In this paper, we show analytically for convolutional and fully connected networks that an alignment between the principal components of network parameters and data takes place when training with random labels. We study this alignment effect by investigating neural networks pre-trained on randomly labelled image data and subsequently fine-tuned on disjoint datasets with random or real labels. We show how this alignment produces a positive transfer: networks pre-trained with random labels train faster downstream compared to training from scratch even after accounting for simple effects, such as weight scaling. We analyze how competing effects, such as specialization at later layers, may hide the positive transfer. These effects are studied in several network architectures, including VGG16 and ResNet18, on CIFAR10 and ImageNet.
What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study
Jun 10, 2020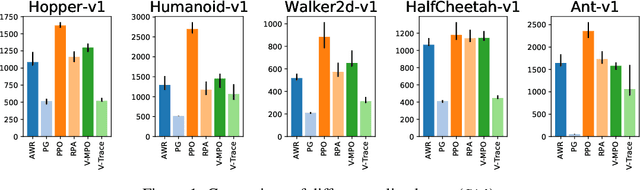

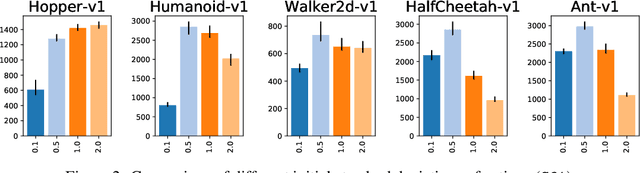

In recent years, on-policy reinforcement learning (RL) has been successfully applied to many different continuous control tasks. While RL algorithms are often conceptually simple, their state-of-the-art implementations take numerous low- and high-level design decisions that strongly affect the performance of the resulting agents. Those choices are usually not extensively discussed in the literature, leading to discrepancy between published descriptions of algorithms and their implementations. This makes it hard to attribute progress in RL and slows down overall progress [Engstrom'20]. As a step towards filling that gap, we implement >50 such ``choices'' in a unified on-policy RL framework, allowing us to investigate their impact in a large-scale empirical study. We train over 250'000 agents in five continuous control environments of different complexity and provide insights and practical recommendations for on-policy training of RL agents.
Predicting Neural Network Accuracy from Weights
Feb 26, 2020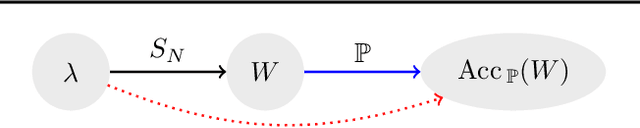

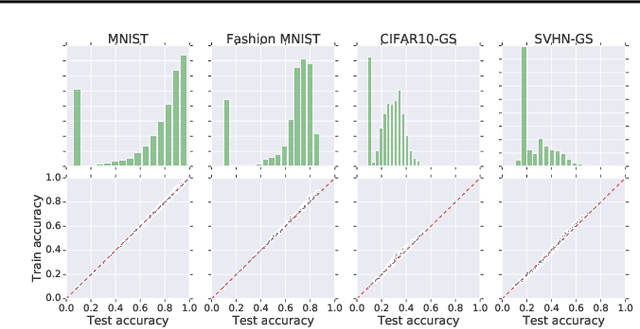
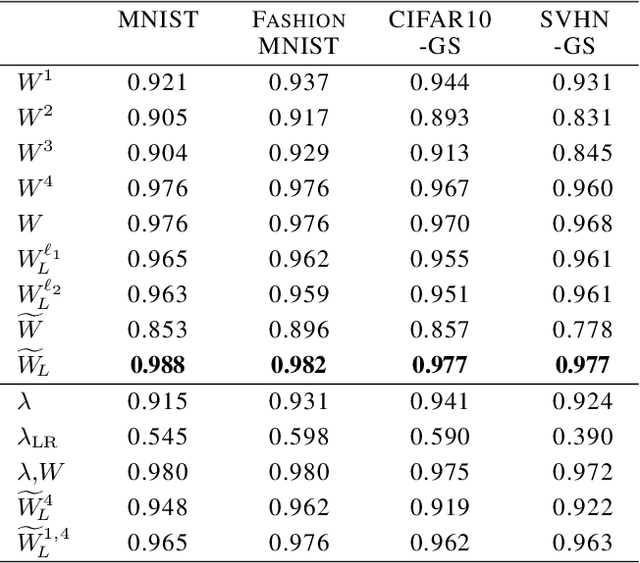
We study the prediction of the accuracy of a neural network given only its weights with the goal of better understanding network training and performance. To do so, we propose a formal setting which frames this task and connects to previous work in this area. We collect (and release) a large dataset of almost 80k convolutional neural networks trained on four image datasets. We demonstrate that strong predictors of accuracy exist. Moreover, they can achieve good predictions while only using simple statistics of the weights. Surprisingly, these predictors are able to rank networks trained on unobserved datasets or using different architectures.
On Last-Layer Algorithms for Classification: Decoupling Representation from Uncertainty Estimation
Jan 22, 2020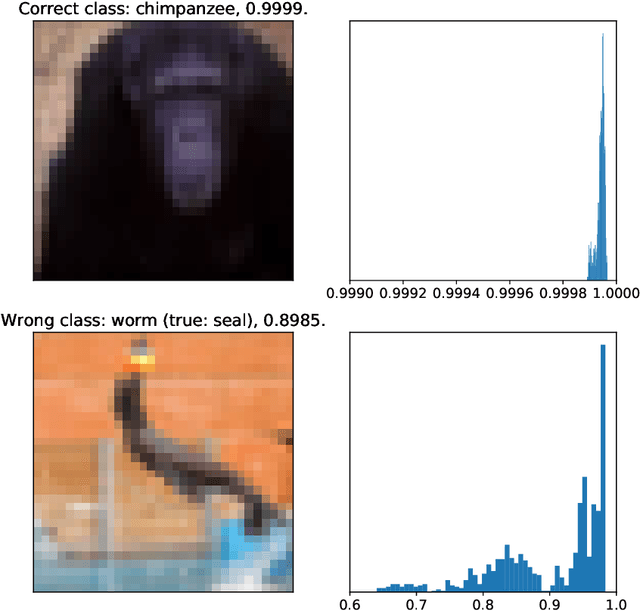
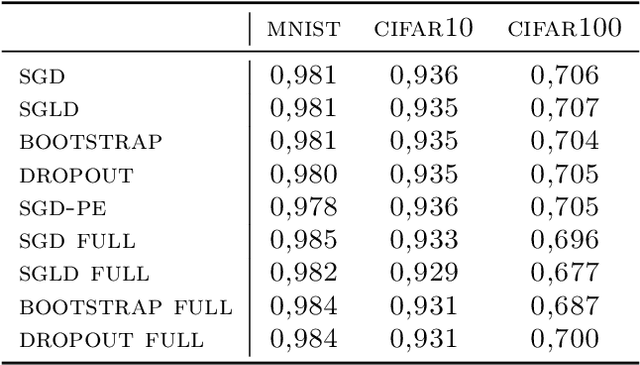
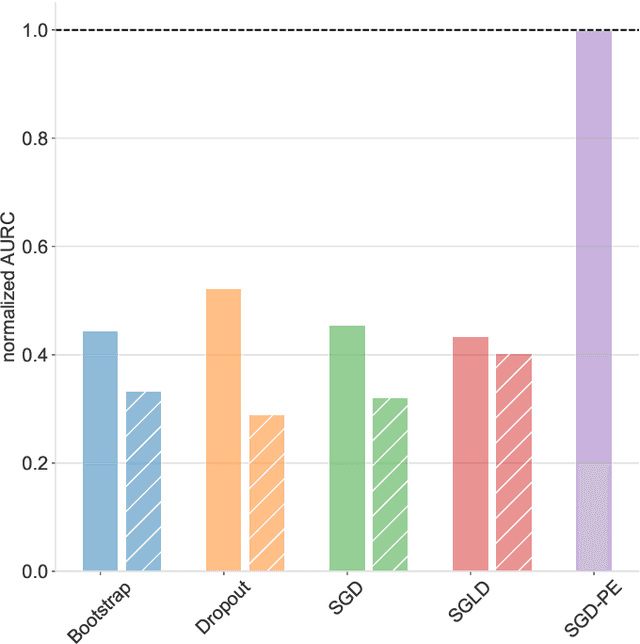
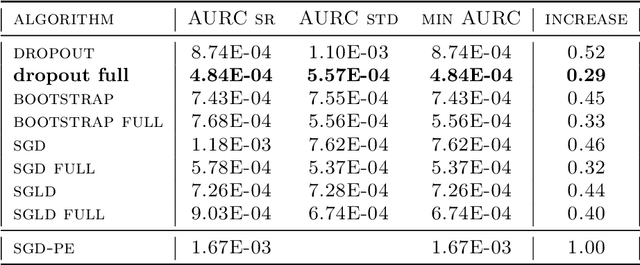
Uncertainty quantification for deep learning is a challenging open problem. Bayesian statistics offer a mathematically grounded framework to reason about uncertainties; however, approximate posteriors for modern neural networks still require prohibitive computational costs. We propose a family of algorithms which split the classification task into two stages: representation learning and uncertainty estimation. We compare four specific instances, where uncertainty estimation is performed via either an ensemble of Stochastic Gradient Descent or Stochastic Gradient Langevin Dynamics snapshots, an ensemble of bootstrapped logistic regressions, or via a number of Monte Carlo Dropout passes. We evaluate their performance in terms of \emph{selective} classification (risk-coverage), and their ability to detect out-of-distribution samples. Our experiments suggest there is limited value in adding multiple uncertainty layers to deep classifiers, and we observe that these simple methods strongly outperform a vanilla point-estimate SGD in some complex benchmarks like ImageNet.