 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting the User-Item Graph with Textual Similarity Models
Sep 20, 2021

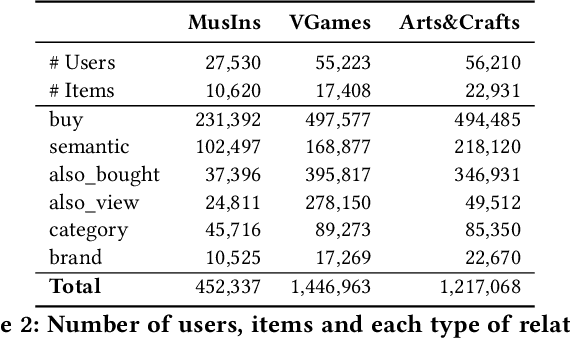
This paper introduces a simple and effective form of data augmentation for recommender systems. A paraphrase similarity model is applied to widely available textual data, such as reviews and product descriptions, yielding new semantic relations that are added to the user-item graph. This increases the density of the graph without needing further labeled data. The data augmentation is evaluated on a variety of recommendation algorithms, using Euclidean, hyperbolic, and complex spaces, and over three categories of Amazon product reviews with differing characteristics. Results show that the data augmentation technique provides significant improvements to all types of models, with the most pronounced gains for knowledge graph-based recommenders, particularly in cold-start settings, leading to state-of-the-art performance.
MLP-Mixer: An all-MLP Architecture for Vision
May 17, 2021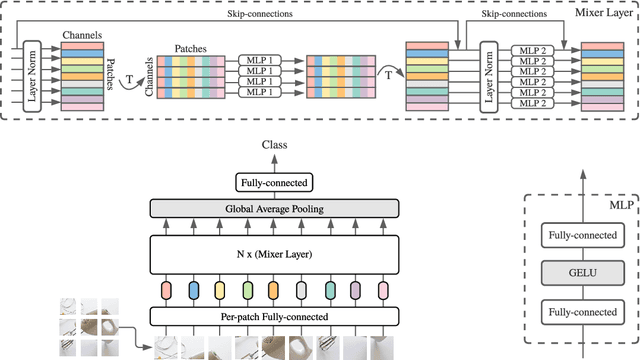
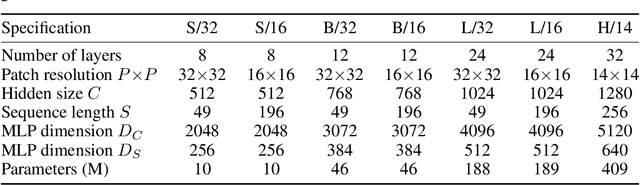
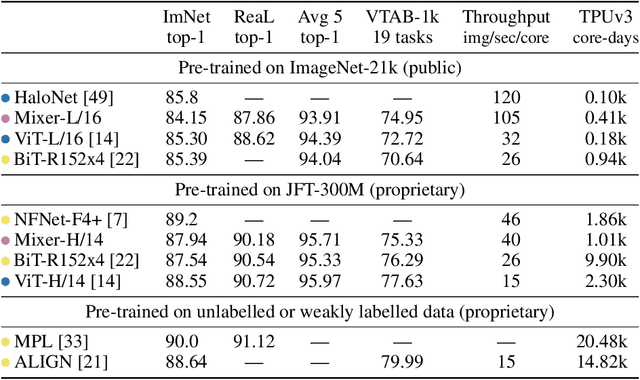
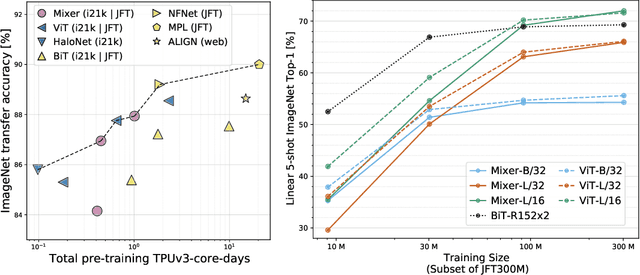
Convolutional Neural Networks (CNNs) are the go-to model for computer vision. Recently, attention-based networks, such as the Vision Transformer, have also become popular. In this paper we show that while convolutions and attention are both sufficient for good performance, neither of them are necessary. We present MLP-Mixer, an architecture based exclusively on multi-layer perceptrons (MLPs). MLP-Mixer contains two types of layers: one with MLPs applied independently to image patches (i.e. "mixing" the per-location features), and one with MLPs applied across patches (i.e. "mixing" spatial information). When trained on large datasets, or with modern regularization schemes, MLP-Mixer attains competitive scores on image classification benchmarks, with pre-training and inference cost comparable to state-of-the-art models. We hope that these results spark further research beyond the realms of well established CNNs and Transformers.
SI-Score: An image dataset for fine-grained analysis of robustness to object location, rotation and size
Apr 09, 2021

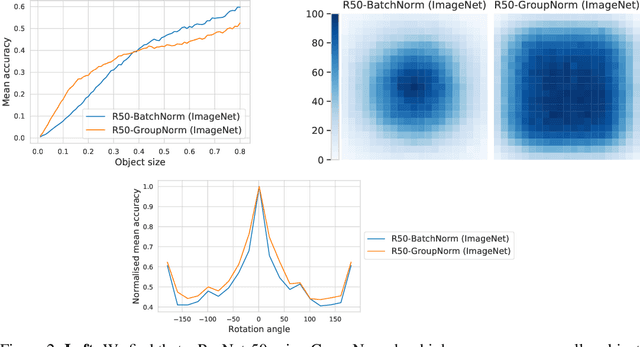

Before deploying machine learning models it is critical to assess their robustness. In the context of deep neural networks for image understanding, changing the object location, rotation and size may affect the predictions in non-trivial ways. In this work we perform a fine-grained analysis of robustness with respect to these factors of variation using SI-Score, a synthetic dataset. In particular, we investigate ResNets, Vision Transformers and CLIP, and identify interesting qualitative differences between these.
On Robustness and Transferability of Convolutional Neural Networks
Jul 16, 2020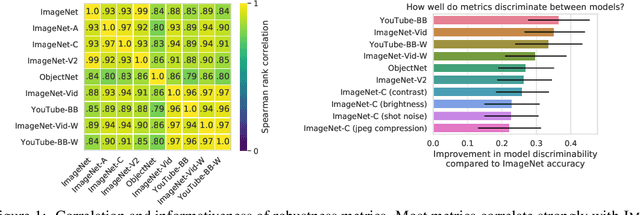

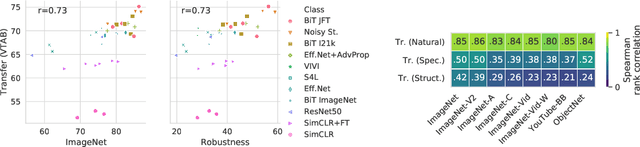
Modern deep convolutional networks (CNNs) are often criticized for not generalizing under distributional shifts. However, several recent breakthroughs in transfer learning suggest that these networks can cope with severe distribution shifts and successfully adapt to new tasks from a few training examples. In this work we revisit the out-of-distribution and transfer performance of modern image classification CNNs and investigate the impact of the pre-training data size, the model scale, and the data preprocessing pipeline. We find that increasing both the training set and model sizes significantly improve the distributional shift robustness. Furthermore, we show that, perhaps surprisingly, simple changes in the preprocessing such as modifying the image resolution can significantly mitigate robustness issues in some cases. Finally, we outline the shortcomings of existing robustness evaluation datasets and introduce a synthetic dataset we use for a systematic analysis across common factors of variation. \end{abstract}
Large Scale Learning of General Visual Representations for Transfer
Dec 24, 2019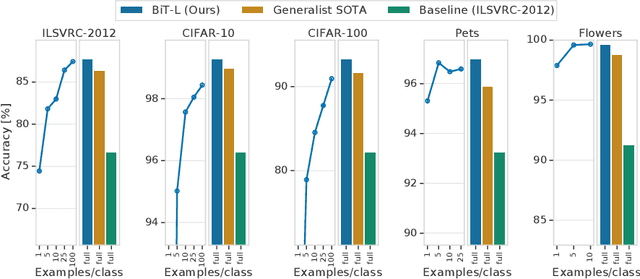

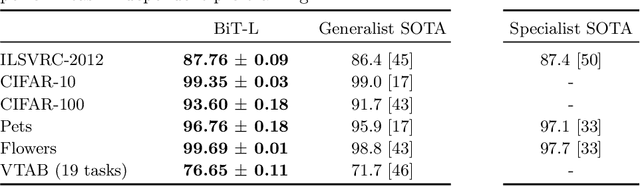
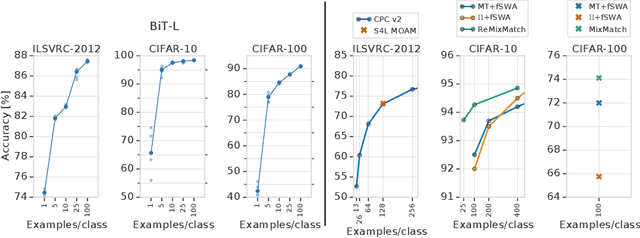
Transfer of pre-trained representations improves sample efficiency and simplifies hyperparameter tuning when training deep neural networks for vision. We revisit the paradigm of pre-training on large supervised datasets and fine-tuning the weights on the target task. We scale up pre-training, and create a simple recipe that we call Big Transfer (BiT). By combining a few carefully selected components, and transferring using a simple heuristic, we achieve strong performance on over 20 datasets. BiT performs well across a surprisingly wide range of data regimes - from 10 to 1M labeled examples. BiT achieves 87.8% top-1 accuracy on ILSVRC-2012, 99.3% on CIFAR-10, and 76.7% on the Visual Task Adaptation Benchmark (which includes 19 tasks). On small datasets, BiT attains 86.4% on ILSVRC-2012 with 25 examples per class, and 97.6% on CIFAR-10 with 10 examples per class. We conduct detailed analysis of the main components that lead to high transfer performance.