 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Scale Learning of General Visual Representations for Transfer
Paper and Code
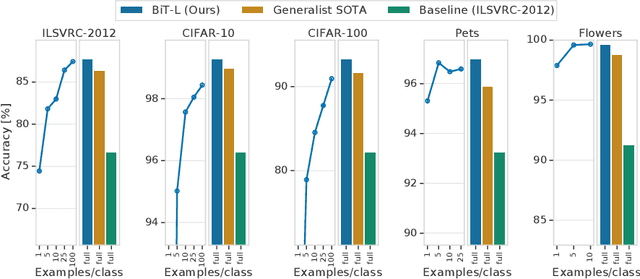

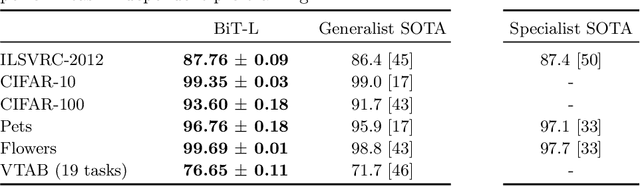
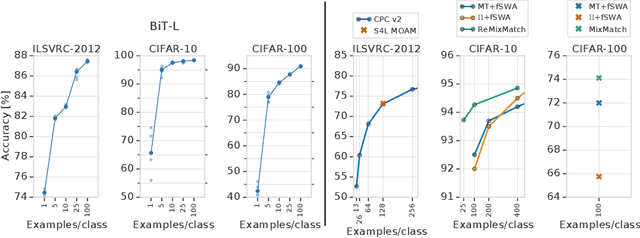
Transfer of pre-trained representations improves sample efficiency and simplifies hyperparameter tuning when training deep neural networks for vision. We revisit the paradigm of pre-training on large supervised datasets and fine-tuning the weights on the target task. We scale up pre-training, and create a simple recipe that we call Big Transfer (BiT). By combining a few carefully selected components, and transferring using a simple heuristic, we achieve strong performance on over 20 datasets. BiT performs well across a surprisingly wide range of data regimes - from 10 to 1M labeled examples. BiT achieves 87.8% top-1 accuracy on ILSVRC-2012, 99.3% on CIFAR-10, and 76.7% on the Visual Task Adaptation Benchmark (which includes 19 tasks). On small datasets, BiT attains 86.4% on ILSVRC-2012 with 25 examples per class, and 97.6% on CIFAR-10 with 10 examples per class. We conduct detailed analysis of the main components that lead to high transfer performance.