 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Mask or to Mirror: Human-AI Alignment in Collective Reasoning
Oct 02, 2025As large language models (LLMs) are increasingly used to model and augment collective decision-making, it is critical to examine their alignment with human social reasoning. We present an empirical framework for assessing collective alignment, in contrast to prior work on the individual level. Using the Lost at Sea social psychology task, we conduct a large-scale online experiment (N=748), randomly assigning groups to leader elections with either visible demographic attributes (e.g. name, gender) or pseudonymous aliases. We then simulate matched LLM groups conditioned on the human data, benchmarking Gemini 2.5, GPT 4.1, Claude Haiku 3.5, and Gemma 3. LLM behaviors diverge: some mirror human biases; others mask these biases and attempt to compensate for them. We empirically demonstrate that human-AI alignment in collective reasoning depends on context, cues, and model-specific inductive biases. Understanding how LLMs align with collective human behavior is critical to advancing socially-aligned AI, and demands dynamic benchmarks that capture the complexities of collective reasoning.
Improving Neutral Point of View Text Generation through Parameter-Efficient Reinforcement Learning and a Small-Scale High-Quality Dataset
Mar 05, 2025This paper describes the construction of a dataset and the evaluation of training methods to improve generative large language models' (LLMs) ability to answer queries on sensitive topics with a Neutral Point of View (NPOV), i.e., to provide significantly more informative, diverse and impartial answers. The dataset, the SHQ-NPOV dataset, comprises 300 high-quality, human-written quadruplets: a query on a sensitive topic, an answer, an NPOV rating, and a set of links to source texts elaborating the various points of view. The first key contribution of this paper is a new methodology to create such datasets through iterative rounds of human peer-critique and annotator training, which we release alongside the dataset. The second key contribution is the identification of a highly effective training regime for parameter-efficient reinforcement learning (PE-RL) to improve NPOV generation. We compare and extensively evaluate PE-RL and multiple baselines-including LoRA finetuning (a strong baseline), SFT and RLHF. PE-RL not only improves on overall NPOV quality compared to the strongest baseline ($97.06\%\rightarrow 99.08\%$), but also scores much higher on features linguists identify as key to separating good answers from the best answers ($60.25\%\rightarrow 85.21\%$ for presence of supportive details, $68.74\%\rightarrow 91.43\%$ for absence of oversimplification). A qualitative analysis corroborates this. Finally, our evaluation finds no statistical differences between results on topics that appear in the training dataset and those on separated evaluation topics, which provides strong evidence that our approach to training PE-RL exhibits very effective out of topic generalization.
Scalable Influence and Fact Tracing for Large Language Model Pretraining
Oct 22, 2024Training data attribution (TDA) methods aim to attribute model outputs back to specific training examples, and the application of these methods to large language model (LLM) outputs could significantly advance model transparency and data curation. However, it has been challenging to date to apply these methods to the full scale of LLM pretraining. In this paper, we refine existing gradient-based methods to work effectively at scale, allowing us to retrieve influential examples for an 8B-parameter language model from a pretraining corpus of over 160B tokens with no need for subsampling or pre-filtering. Our method combines several techniques, including optimizer state correction, a task-specific Hessian approximation, and normalized encodings, which we find to be critical for performance at scale. In quantitative evaluations on a fact tracing task, our method performs best at identifying examples that influence model predictions, but classical, model-agnostic retrieval methods such as BM25 still perform better at finding passages which explicitly contain relevant facts. These results demonstrate a misalignment between factual attribution and causal influence. With increasing model size and training tokens, we find that influence more closely aligns with attribution. Finally, we examine different types of examples identified as influential by our method, finding that while many directly entail a particular fact, others support the same output by reinforcing priors on relation types, common entities, and names.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Who's asking? User personas and the mechanics of latent misalignment
Jun 17, 2024



Despite investments in improving model safety, studies show that misaligned capabilities remain latent in safety-tuned models. In this work, we shed light on the mechanics of this phenomenon. First, we show that even when model generations are safe, harmful content can persist in hidden representations and can be extracted by decoding from earlier layers. Then, we show that whether the model divulges such content depends significantly on its perception of who it is talking to, which we refer to as user persona. In fact, we find manipulating user persona to be even more effective for eliciting harmful content than direct attempts to control model refusal. We study both natural language prompting and activation steering as control methods and show that activation steering is significantly more effective at bypassing safety filters. We investigate why certain personas break model safeguards and find that they enable the model to form more charitable interpretations of otherwise dangerous queries. Finally, we show we can predict a persona's effect on refusal given only the geometry of its steering vector.
Interactive Prompt Debugging with Sequence Salience
Apr 11, 2024We present Sequence Salience, a visual tool for interactive prompt debugging with input salience methods. Sequence Salience builds on widely used salience methods for text classification and single-token prediction, and extends this to a system tailored for debugging complex LLM prompts. Our system is well-suited for long texts, and expands on previous work by 1) providing controllable aggregation of token-level salience to the word, sentence, or paragraph level, making salience over long inputs tractable; and 2) supporting rapid iteration where practitioners can act on salience results, refine prompts, and run salience on the new output. We include case studies showing how Sequence Salience can help practitioners work with several complex prompting strategies, including few-shot, chain-of-thought, and constitutional principles. Sequence Salience is built on the Learning Interpretability Tool, an open-source platform for ML model visualizations, and code, notebooks, and tutorials are available at http://goo.gle/sequence-salience.
PERL: Parameter Efficient Reinforcement Learning from Human Feedback
Mar 15, 2024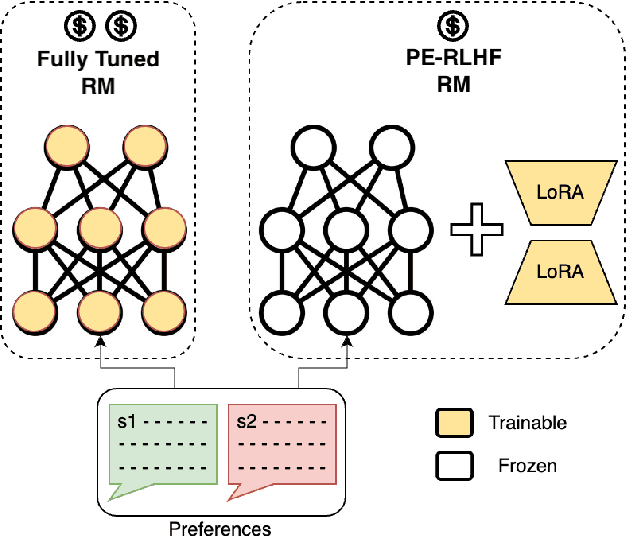
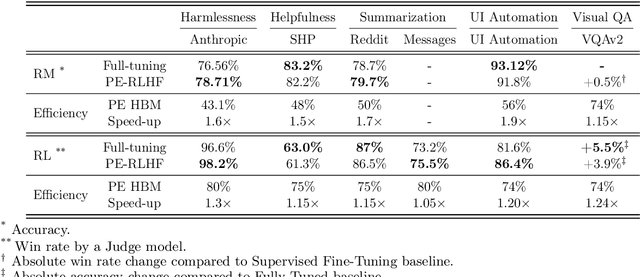
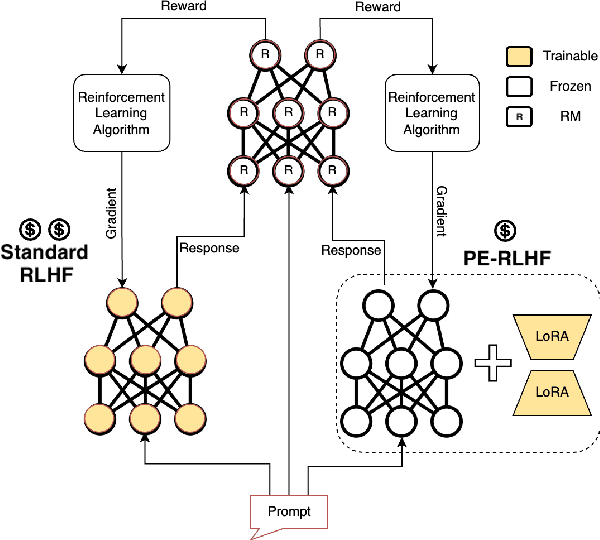
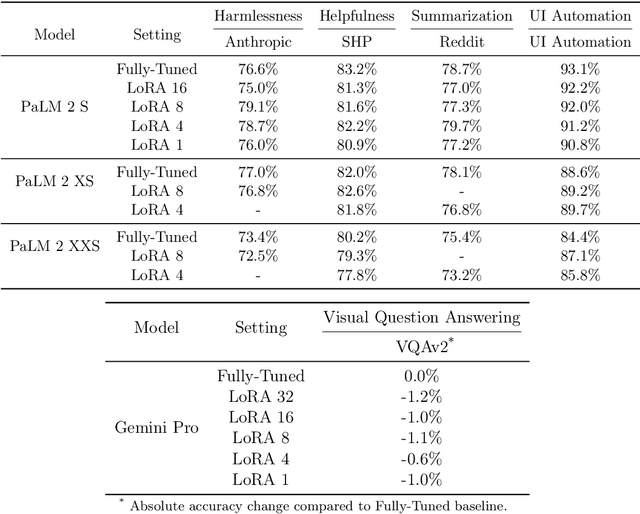
Reinforcement Learning from Human Feedback (RLHF) has proven to be a strong method to align Pretrained Large Language Models (LLMs) with human preferences. But training models with RLHF is computationally expensive, and an overall complex process. In this work, we study RLHF where the underlying models are trained using the parameter efficient method of Low-Rank Adaptation (LoRA) introduced by Hu et al. [2021]. We investigate the setup of "Parameter Efficient Reinforcement Learning" (PERL), in which we perform reward model training and reinforcement learning using LoRA. We compare PERL to conventional fine-tuning (full-tuning) across various configurations for 7 benchmarks, including 2 novel datasets, of reward modeling and reinforcement learning. We find that PERL performs on par with the conventional RLHF setting, while training faster, and with less memory. This enables the high performance of RLHF, while reducing the computational burden that limits its adoption as an alignment technique for Large Language Models. We also release 2 novel thumbs up/down preference datasets: "Taskmaster Coffee", and "Taskmaster Ticketing" to promote research around RLHF.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Detecting Hallucination and Coverage Errors in Retrieval Augmented Generation for Controversial Topics
Mar 13, 2024We explore a strategy to handle controversial topics in LLM-based chatbots based on Wikipedia's Neutral Point of View (NPOV) principle: acknowledge the absence of a single true answer and surface multiple perspectives. We frame this as retrieval augmented generation, where perspectives are retrieved from a knowledge base and the LLM is tasked with generating a fluent and faithful response from the given perspectives. As a starting point, we use a deterministic retrieval system and then focus on common LLM failure modes that arise during this approach to text generation, namely hallucination and coverage errors. We propose and evaluate three methods to detect such errors based on (1) word-overlap, (2) salience, and (3) LLM-based classifiers. Our results demonstrate that LLM-based classifiers, even when trained only on synthetic errors, achieve high error detection performance, with ROC AUC scores of 95.3% for hallucination and 90.5% for coverage error detection on unambiguous error cases. We show that when no training data is available, our other methods still yield good results on hallucination (84.0%) and coverage error (85.2%) detection.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.