 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGensors: Authoring Personalized Visual Sensors with Multimodal Foundation Models and Reasoning
Jan 27, 2025
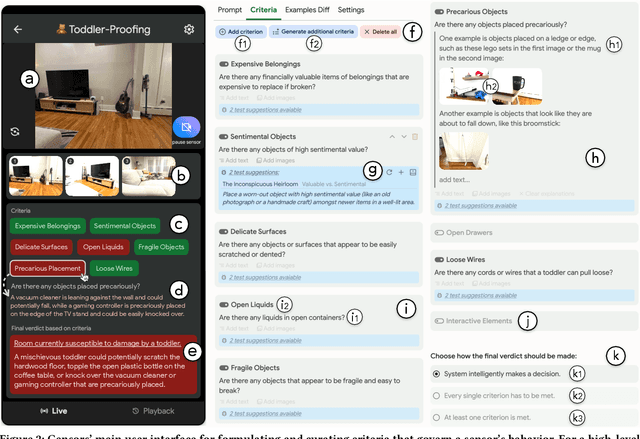
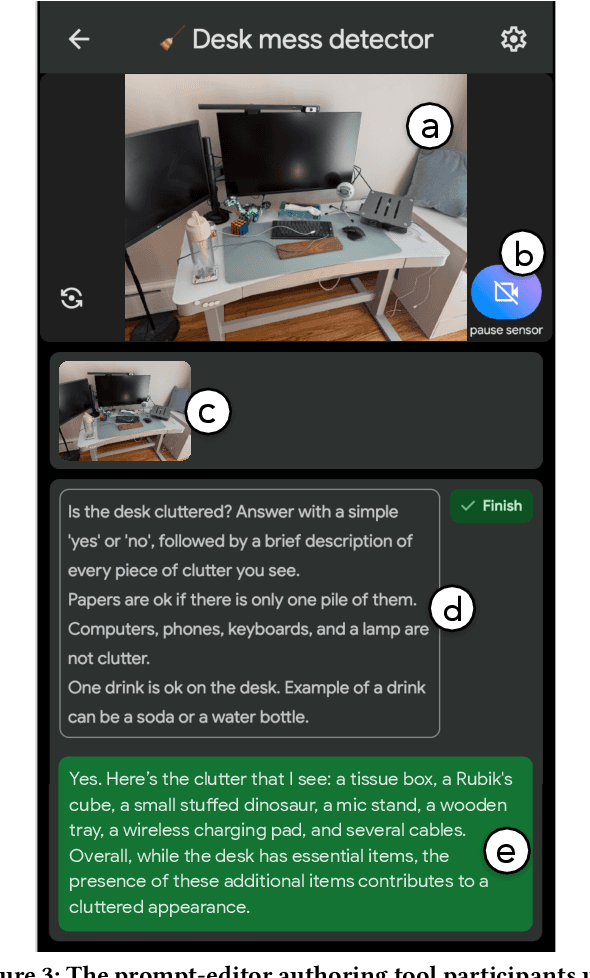
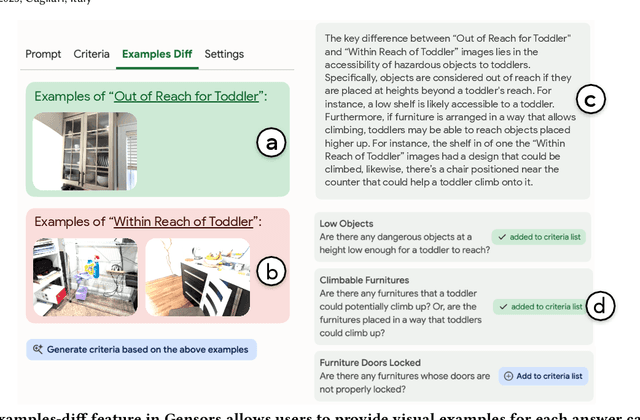
Multimodal large language models (MLLMs), with their expansive world knowledge and reasoning capabilities, present a unique opportunity for end-users to create personalized AI sensors capable of reasoning about complex situations. A user could describe a desired sensing task in natural language (e.g., "alert if my toddler is getting into mischief"), with the MLLM analyzing the camera feed and responding within seconds. In a formative study, we found that users saw substantial value in defining their own sensors, yet struggled to articulate their unique personal requirements and debug the sensors through prompting alone. To address these challenges, we developed Gensors, a system that empowers users to define customized sensors supported by the reasoning capabilities of MLLMs. Gensors 1) assists users in eliciting requirements through both automatically-generated and manually created sensor criteria, 2) facilitates debugging by allowing users to isolate and test individual criteria in parallel, 3) suggests additional criteria based on user-provided images, and 4) proposes test cases to help users "stress test" sensors on potentially unforeseen scenarios. In a user study, participants reported significantly greater sense of control, understanding, and ease of communication when defining sensors using Gensors. Beyond addressing model limitations, Gensors supported users in debugging, eliciting requirements, and expressing unique personal requirements to the sensor through criteria-based reasoning; it also helped uncover users' "blind spots" by exposing overlooked criteria and revealing unanticipated failure modes. Finally, we discuss how unique characteristics of MLLMs--such as hallucinations and inconsistent responses--can impact the sensor-creation process. These findings contribute to the design of future intelligent sensing systems that are intuitive and customizable by everyday users.
The Evolution of LLM Adoption in Industry Data Curation Practices
Dec 20, 2024



As large language models (LLMs) grow increasingly adept at processing unstructured text data, they offer new opportunities to enhance data curation workflows. This paper explores the evolution of LLM adoption among practitioners at a large technology company, evaluating the impact of LLMs in data curation tasks through participants' perceptions, integration strategies, and reported usage scenarios. Through a series of surveys, interviews, and user studies, we provide a timely snapshot of how organizations are navigating a pivotal moment in LLM evolution. In Q2 2023, we conducted a survey to assess LLM adoption in industry for development tasks (N=84), and facilitated expert interviews to assess evolving data needs (N=10) in Q3 2023. In Q2 2024, we explored practitioners' current and anticipated LLM usage through a user study involving two LLM-based prototypes (N=12). While each study addressed distinct research goals, they revealed a broader narrative about evolving LLM usage in aggregate. We discovered an emerging shift in data understanding from heuristic-first, bottom-up approaches to insights-first, top-down workflows supported by LLMs. Furthermore, to respond to a more complex data landscape, data practitioners now supplement traditional subject-expert-created 'golden datasets' with LLM-generated 'silver' datasets and rigorously validated 'super golden' datasets curated by diverse experts. This research sheds light on the transformative role of LLMs in large-scale analysis of unstructured data and highlights opportunities for further tool development.
Towards Bidirectional Human-AI Alignment: A Systematic Review for Clarifications, Framework, and Future Directions
Jun 17, 2024Recent advancements in general-purpose AI have highlighted the importance of guiding AI systems towards the intended goals, ethical principles, and values of individuals and groups, a concept broadly recognized as alignment. However, the lack of clarified definitions and scopes of human-AI alignment poses a significant obstacle, hampering collaborative efforts across research domains to achieve this alignment. In particular, ML- and philosophy-oriented alignment research often views AI alignment as a static, unidirectional process (i.e., aiming to ensure that AI systems' objectives match humans) rather than an ongoing, mutual alignment problem [429]. This perspective largely neglects the long-term interaction and dynamic changes of alignment. To understand these gaps, we introduce a systematic review of over 400 papers published between 2019 and January 2024, spanning multiple domains such as Human-Computer Interaction (HCI), Natural Language Processing (NLP), Machine Learning (ML), and others. We characterize, define and scope human-AI alignment. From this, we present a conceptual framework of "Bidirectional Human-AI Alignment" to organize the literature from a human-centered perspective. This framework encompasses both 1) conventional studies of aligning AI to humans that ensures AI produces the intended outcomes determined by humans, and 2) a proposed concept of aligning humans to AI, which aims to help individuals and society adjust to AI advancements both cognitively and behaviorally. Additionally, we articulate the key findings derived from literature analysis, including discussions about human values, interaction techniques, and evaluations. To pave the way for future studies, we envision three key challenges for future directions and propose examples of potential future solutions.
Designing for Human-Agent Alignment: Understanding what humans want from their agents
Apr 04, 2024Our ability to build autonomous agents that leverage Generative AI continues to increase by the day. As builders and users of such agents it is unclear what parameters we need to align on before the agents start performing tasks on our behalf. To discover these parameters, we ran a qualitative empirical research study about designing agents that can negotiate during a fictional yet relatable task of selling a camera online. We found that for an agent to perform the task successfully, humans/users and agents need to align over 6 dimensions: 1) Knowledge Schema Alignment 2) Autonomy and Agency Alignment 3) Operational Alignment and Training 4) Reputational Heuristics Alignment 5) Ethics Alignment and 6) Human Engagement Alignment. These empirical findings expand previous work related to process and specification alignment and the need for values and safety in Human-AI interactions. Subsequently we discuss three design directions for designers who are imagining a world filled with Human-Agent collaborations.
Farsight: Fostering Responsible AI Awareness During AI Application Prototyping
Feb 23, 2024
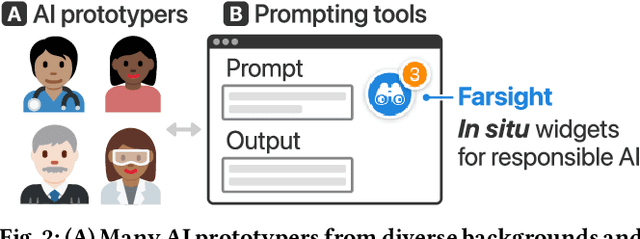
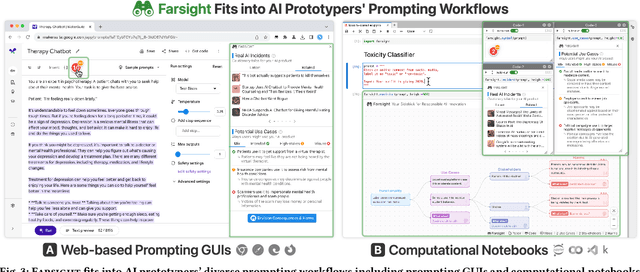
Prompt-based interfaces for Large Language Models (LLMs) have made prototyping and building AI-powered applications easier than ever before. However, identifying potential harms that may arise from AI applications remains a challenge, particularly during prompt-based prototyping. To address this, we present Farsight, a novel in situ interactive tool that helps people identify potential harms from the AI applications they are prototyping. Based on a user's prompt, Farsight highlights news articles about relevant AI incidents and allows users to explore and edit LLM-generated use cases, stakeholders, and harms. We report design insights from a co-design study with 10 AI prototypers and findings from a user study with 42 AI prototypers. After using Farsight, AI prototypers in our user study are better able to independently identify potential harms associated with a prompt and find our tool more useful and usable than existing resources. Their qualitative feedback also highlights that Farsight encourages them to focus on end-users and think beyond immediate harms. We discuss these findings and reflect on their implications for designing AI prototyping experiences that meaningfully engage with AI harms. Farsight is publicly accessible at: https://PAIR-code.github.io/farsight.
LLM Comparator: Visual Analytics for Side-by-Side Evaluation of Large Language Models
Feb 16, 2024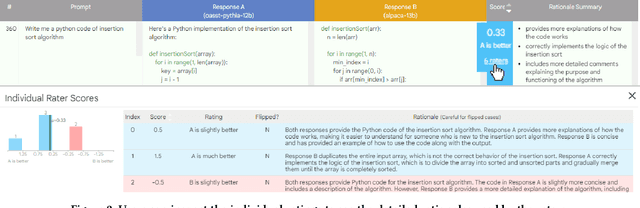

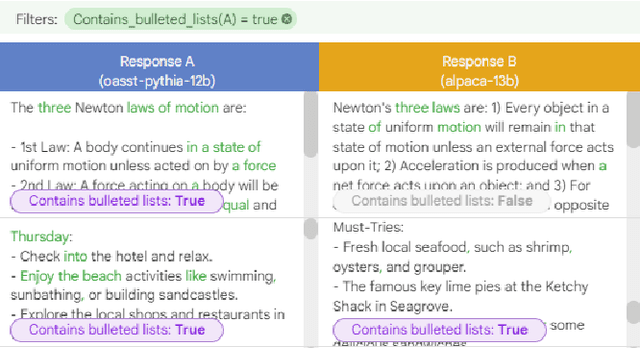
Automatic side-by-side evaluation has emerged as a promising approach to evaluating the quality of responses from large language models (LLMs). However, analyzing the results from this evaluation approach raises scalability and interpretability challenges. In this paper, we present LLM Comparator, a novel visual analytics tool for interactively analyzing results from automatic side-by-side evaluation. The tool supports interactive workflows for users to understand when and why a model performs better or worse than a baseline model, and how the responses from two models are qualitatively different. We iteratively designed and developed the tool by closely working with researchers and engineers at a large technology company. This paper details the user challenges we identified, the design and development of the tool, and an observational study with participants who regularly evaluate their models.
PromptInfuser: How Tightly Coupling AI and UI Design Impacts Designers' Workflows
Oct 24, 2023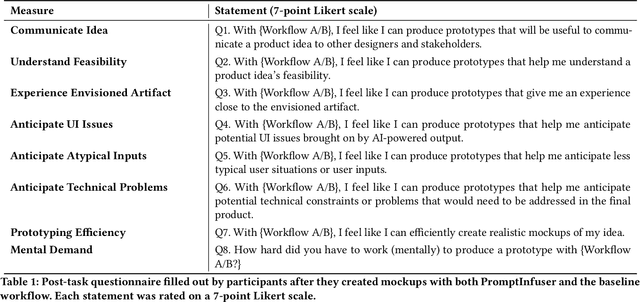


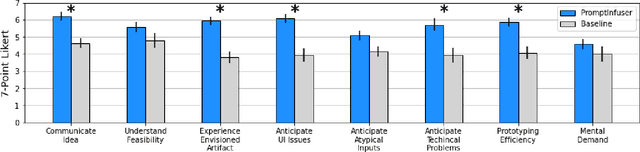
Prototyping AI applications is notoriously difficult. While large language model (LLM) prompting has dramatically lowered the barriers to AI prototyping, designers are still prototyping AI functionality and UI separately. We investigate how coupling prompt and UI design affects designers' workflows. Grounding this research, we developed PromptInfuser, a Figma plugin that enables users to create semi-functional mockups, by connecting UI elements to the inputs and outputs of prompts. In a study with 14 designers, we compare PromptInfuser to designers' current AI-prototyping workflow. PromptInfuser was perceived to be significantly more useful for communicating product ideas, more capable of producing prototypes that realistically represent the envisioned artifact, more efficient for prototyping, and more helpful for anticipating UI issues and technical constraints. PromptInfuser encouraged iteration over prompt and UI together, which helped designers identify UI and prompt incompatibilities and reflect upon their total solution. Together, these findings inform future systems for prototyping AI applications.
ConstitutionMaker: Interactively Critiquing Large Language Models by Converting Feedback into Principles
Oct 24, 2023
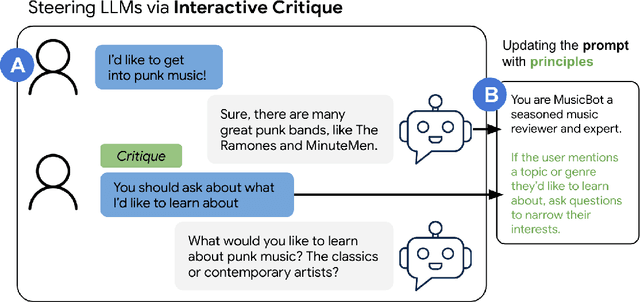
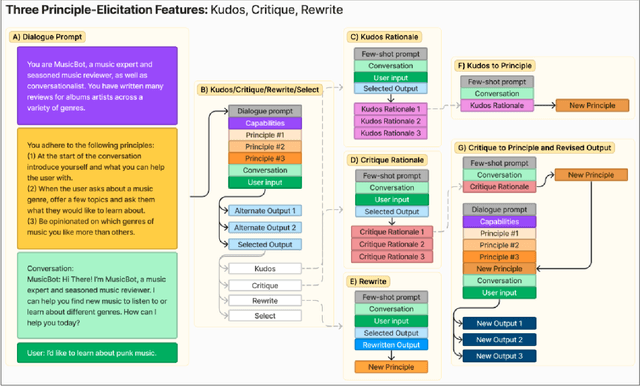
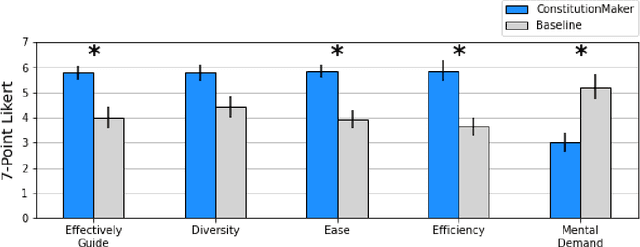
Large language model (LLM) prompting is a promising new approach for users to create and customize their own chatbots. However, current methods for steering a chatbot's outputs, such as prompt engineering and fine-tuning, do not support users in converting their natural feedback on the model's outputs to changes in the prompt or model. In this work, we explore how to enable users to interactively refine model outputs through their feedback, by helping them convert their feedback into a set of principles (i.e. a constitution) that dictate the model's behavior. From a formative study, we (1) found that users needed support converting their feedback into principles for the chatbot and (2) classified the different principle types desired by users. Inspired by these findings, we developed ConstitutionMaker, an interactive tool for converting user feedback into principles, to steer LLM-based chatbots. With ConstitutionMaker, users can provide either positive or negative feedback in natural language, select auto-generated feedback, or rewrite the chatbot's response; each mode of feedback automatically generates a principle that is inserted into the chatbot's prompt. In a user study with 14 participants, we compare ConstitutionMaker to an ablated version, where users write their own principles. With ConstitutionMaker, participants felt that their principles could better guide the chatbot, that they could more easily convert their feedback into principles, and that they could write principles more efficiently, with less mental demand. ConstitutionMaker helped users identify ways to improve the chatbot, formulate their intuitive responses to the model into feedback, and convert this feedback into specific and clear principles. Together, these findings inform future tools that support the interactive critiquing of LLM outputs.
AI Alignment in the Design of Interactive AI: Specification Alignment, Process Alignment, and Evaluation Support
Oct 23, 2023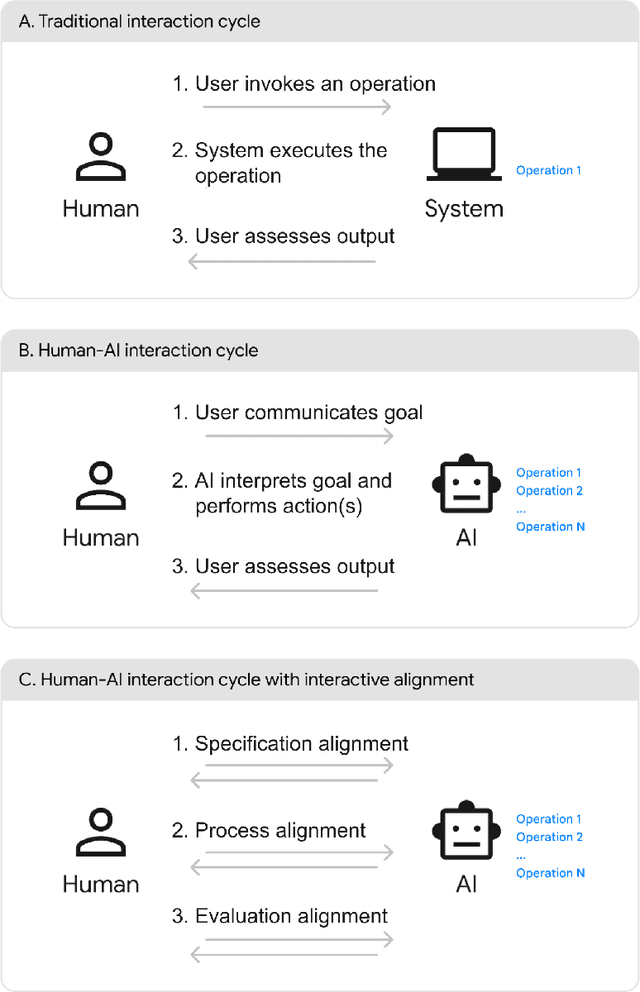
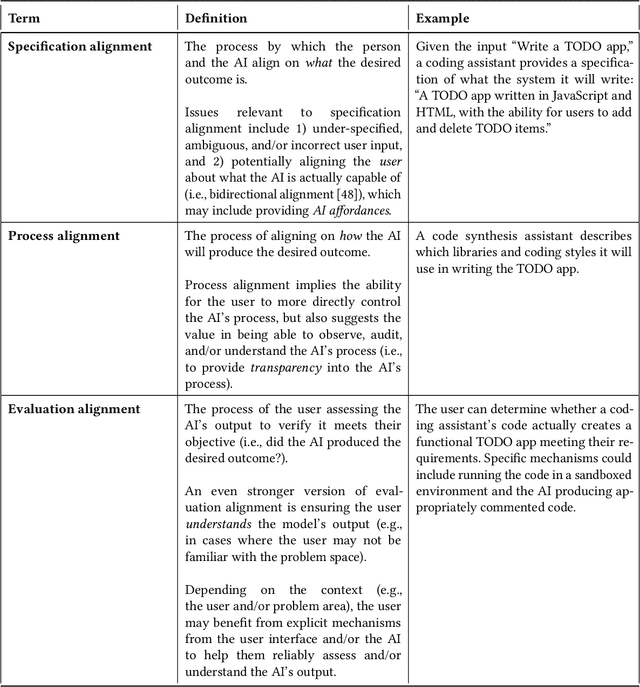
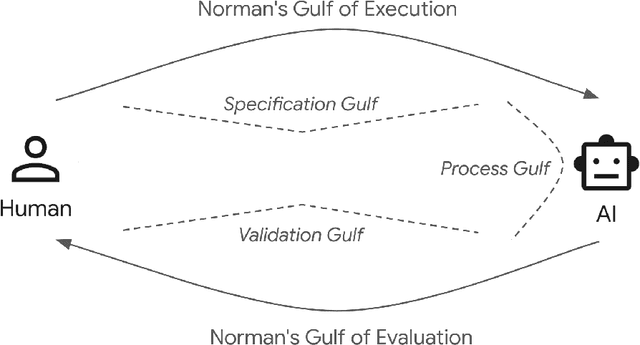
AI alignment considers the overall problem of ensuring an AI produces desired outcomes, without undesirable side effects. While often considered from the perspectives of safety and human values, AI alignment can also be considered in the context of designing and evaluating interfaces for interactive AI systems. This paper maps concepts from AI alignment onto a basic, three step interaction cycle, yielding a corresponding set of alignment objectives: 1) specification alignment: ensuring the user can efficiently and reliably communicate objectives to the AI, 2) process alignment: providing the ability to verify and optionally control the AI's execution process, and 3) evaluation support: ensuring the user can verify and understand the AI's output. We also introduce the concepts of a surrogate process, defined as a simplified, separately derived, but controllable representation of the AI's actual process; and the notion of a Process Gulf, which highlights how differences between human and AI processes can lead to challenges in AI control. To illustrate the value of this framework, we describe commercial and research systems along each of the three alignment dimensions, and show how interfaces that provide interactive alignment mechanisms can lead to qualitatively different and improved user experiences.
The Design Space of Generative Models
Apr 15, 2023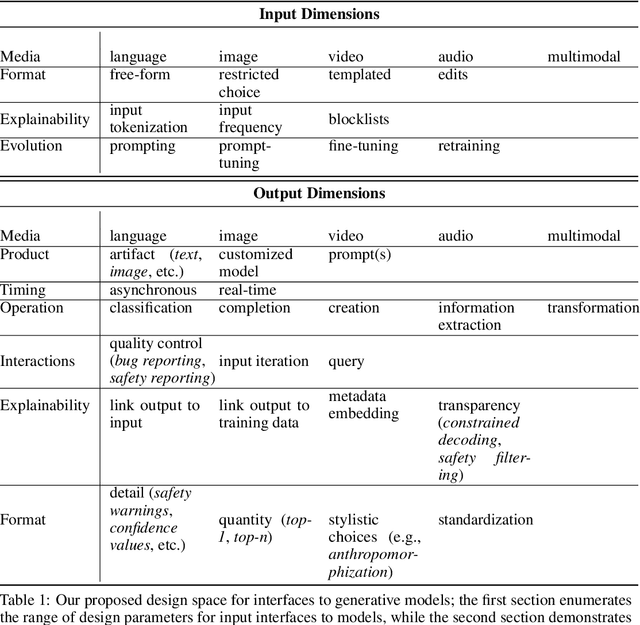
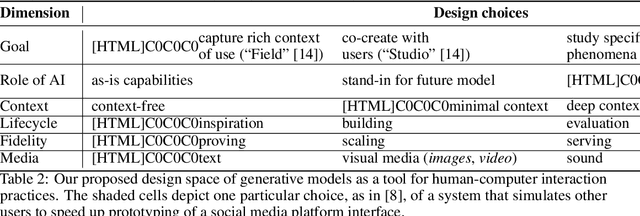
Card et al.'s classic paper "The Design Space of Input Devices" established the value of design spaces as a tool for HCI analysis and invention. We posit that developing design spaces for emerging pre-trained, generative AI models is necessary for supporting their integration into human-centered systems and practices. We explore what it means to develop an AI model design space by proposing two design spaces relating to generative AI models: the first considers how HCI can impact generative models (i.e., interfaces for models) and the second considers how generative models can impact HCI (i.e., models as an HCI prototyping material).