 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Evolution of LLM Adoption in Industry Data Curation Practices
Dec 20, 2024



As large language models (LLMs) grow increasingly adept at processing unstructured text data, they offer new opportunities to enhance data curation workflows. This paper explores the evolution of LLM adoption among practitioners at a large technology company, evaluating the impact of LLMs in data curation tasks through participants' perceptions, integration strategies, and reported usage scenarios. Through a series of surveys, interviews, and user studies, we provide a timely snapshot of how organizations are navigating a pivotal moment in LLM evolution. In Q2 2023, we conducted a survey to assess LLM adoption in industry for development tasks (N=84), and facilitated expert interviews to assess evolving data needs (N=10) in Q3 2023. In Q2 2024, we explored practitioners' current and anticipated LLM usage through a user study involving two LLM-based prototypes (N=12). While each study addressed distinct research goals, they revealed a broader narrative about evolving LLM usage in aggregate. We discovered an emerging shift in data understanding from heuristic-first, bottom-up approaches to insights-first, top-down workflows supported by LLMs. Furthermore, to respond to a more complex data landscape, data practitioners now supplement traditional subject-expert-created 'golden datasets' with LLM-generated 'silver' datasets and rigorously validated 'super golden' datasets curated by diverse experts. This research sheds light on the transformative role of LLMs in large-scale analysis of unstructured data and highlights opportunities for further tool development.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Synthetic Data and Hierarchical Object Detection in Overhead Imagery
Jan 29, 2021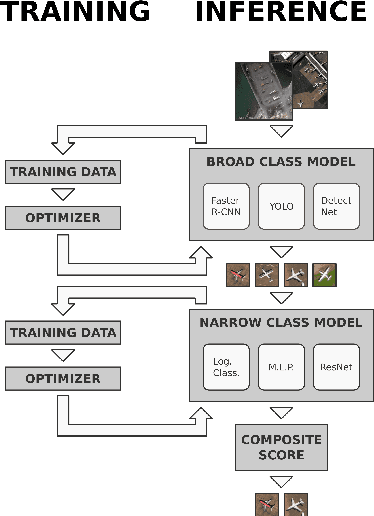
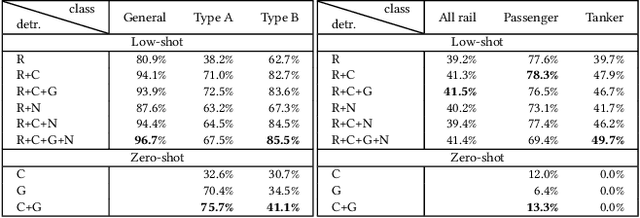

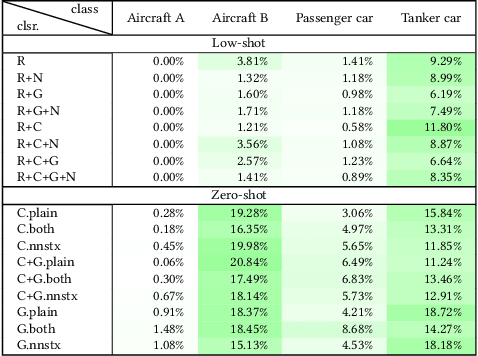
The performance of neural network models is often limited by the availability of big data sets. To treat this problem, we survey and develop novel synthetic data generation and augmentation techniques for enhancing low/zero-sample learning in satellite imagery. In addition to extending synthetic data generation approaches, we propose a hierarchical detection approach to improve the utility of synthetic training samples. We consider existing techniques for producing synthetic imagery--3D models and neural style transfer--as well as introducing our own adversarially trained reskinning network, the GAN-Reskinner, to blend 3D models. Additionally, we test the value of synthetic data in a two-stage, hierarchical detection/classification model of our own construction. To test the effectiveness of synthetic imagery, we employ it in the training of detection models and our two stage model, and evaluate the resulting models on real satellite images. All modalities of synthetic data are tested extensively on practical, geospatial analysis problems. Our experiments show that synthetic data developed using our approach can often enhance detection performance, particularly when combined with some real training images. When the only source of data is synthetic, our GAN-Reskinner often boosts performance over conventionally rendered 3D models and in all cases the hierarchical model outperforms the baseline end-to-end detection architecture.