 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Evolution of LLM Adoption in Industry Data Curation Practices
Dec 20, 2024



As large language models (LLMs) grow increasingly adept at processing unstructured text data, they offer new opportunities to enhance data curation workflows. This paper explores the evolution of LLM adoption among practitioners at a large technology company, evaluating the impact of LLMs in data curation tasks through participants' perceptions, integration strategies, and reported usage scenarios. Through a series of surveys, interviews, and user studies, we provide a timely snapshot of how organizations are navigating a pivotal moment in LLM evolution. In Q2 2023, we conducted a survey to assess LLM adoption in industry for development tasks (N=84), and facilitated expert interviews to assess evolving data needs (N=10) in Q3 2023. In Q2 2024, we explored practitioners' current and anticipated LLM usage through a user study involving two LLM-based prototypes (N=12). While each study addressed distinct research goals, they revealed a broader narrative about evolving LLM usage in aggregate. We discovered an emerging shift in data understanding from heuristic-first, bottom-up approaches to insights-first, top-down workflows supported by LLMs. Furthermore, to respond to a more complex data landscape, data practitioners now supplement traditional subject-expert-created 'golden datasets' with LLM-generated 'silver' datasets and rigorously validated 'super golden' datasets curated by diverse experts. This research sheds light on the transformative role of LLMs in large-scale analysis of unstructured data and highlights opportunities for further tool development.
Who's asking? User personas and the mechanics of latent misalignment
Jun 17, 2024



Despite investments in improving model safety, studies show that misaligned capabilities remain latent in safety-tuned models. In this work, we shed light on the mechanics of this phenomenon. First, we show that even when model generations are safe, harmful content can persist in hidden representations and can be extracted by decoding from earlier layers. Then, we show that whether the model divulges such content depends significantly on its perception of who it is talking to, which we refer to as user persona. In fact, we find manipulating user persona to be even more effective for eliciting harmful content than direct attempts to control model refusal. We study both natural language prompting and activation steering as control methods and show that activation steering is significantly more effective at bypassing safety filters. We investigate why certain personas break model safeguards and find that they enable the model to form more charitable interpretations of otherwise dangerous queries. Finally, we show we can predict a persona's effect on refusal given only the geometry of its steering vector.
Automatic Histograms: Leveraging Language Models for Text Dataset Exploration
Feb 21, 2024Making sense of unstructured text datasets is perennially difficult, yet increasingly relevant with Large Language Models. Data workers often rely on dataset summaries, especially distributions of various derived features. Some features, like toxicity or topics, are relevant to many datasets, but many interesting features are domain specific: instruments and genres for a music dataset, or diseases and symptoms for a medical dataset. Accordingly, data workers often run custom analyses for each dataset, which is cumbersome and difficult. We present AutoHistograms, a visualization tool leveragingLLMs. AutoHistograms automatically identifies relevant features, visualizes them with histograms, and allows the user to interactively query the dataset for categories of entities and create new histograms. In a user study with 10 data workers (n=10), we observe that participants can quickly identify insights and explore the data using AutoHistograms, and conceptualize a broad range of applicable use cases. Together, this tool and user study contributeto the growing field of LLM-assisted sensemaking tools.
Understanding the Dataset Practitioners Behind Large Language Model Development
Feb 21, 2024

As large language models (LLMs) become more advanced and impactful, it is increasingly important to scrutinize the data that they rely upon and produce. What is it to be a dataset practitioner doing this work? We approach this in two parts: first, we define the role of "dataset practitioner" by performing a retrospective analysis on the responsibilities of teams contributing to LLM development at Google. Then, we conduct semi-structured interviews with a cross-section of these practitioners (N=10). We find that data quality is the top priority. To evaluate data quality, practitioners either rely on their own intuition or write custom evaluation logic. There is a lack of consensus across practitioners on what quality is and how to evaluate it. We discuss potential reasons for this phenomenon and opportunities for alignment.
LLM Comparator: Visual Analytics for Side-by-Side Evaluation of Large Language Models
Feb 16, 2024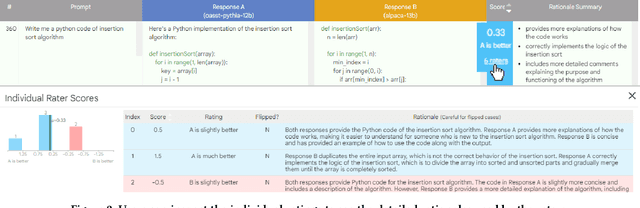

Automatic side-by-side evaluation has emerged as a promising approach to evaluating the quality of responses from large language models (LLMs). However, analyzing the results from this evaluation approach raises scalability and interpretability challenges. In this paper, we present LLM Comparator, a novel visual analytics tool for interactively analyzing results from automatic side-by-side evaluation. The tool supports interactive workflows for users to understand when and why a model performs better or worse than a baseline model, and how the responses from two models are qualitatively different. We iteratively designed and developed the tool by closely working with researchers and engineers at a large technology company. This paper details the user challenges we identified, the design and development of the tool, and an observational study with participants who regularly evaluate their models.
SoUnD Framework: Analyzing (So)cial Representation in (Un)structured (D)ata
Dec 01, 2023The unstructured nature of data used in foundation model development is a challenge to systematic analyses for making data use and documentation decisions. From a Responsible AI perspective, these decisions often rely upon understanding how people are represented in data. We propose a framework designed to guide analysis of human representation in unstructured data and identify downstream risks. We apply the framework in two toy examples using the Common Crawl web text corpus (C4) and LAION-400M. We also propose a set of hypothetical action steps in service of dataset use, development, and documentation.
Data Similarity is Not Enough to Explain Language Model Performance
Nov 15, 2023Large language models achieve high performance on many but not all downstream tasks. The interaction between pretraining data and task data is commonly assumed to determine this variance: a task with data that is more similar to a model's pretraining data is assumed to be easier for that model. We test whether distributional and example-specific similarity measures (embedding-, token- and model-based) correlate with language model performance through a large-scale comparison of the Pile and C4 pretraining datasets with downstream benchmarks. Similarity correlates with performance for multilingual datasets, but in other benchmarks, we surprisingly find that similarity metrics are not correlated with accuracy or even each other. This suggests that the relationship between pretraining data and downstream tasks is more complex than often assumed.
A Pretrainer's Guide to Training Data: Measuring the Effects of Data Age, Domain Coverage, Quality, & Toxicity
May 22, 2023



Pretraining is the preliminary and fundamental step in developing capable language models (LM). Despite this, pretraining data design is critically under-documented and often guided by empirically unsupported intuitions. To address this, we pretrain 28 1.5B parameter decoder-only models, training on data curated (1) at different times, (2) with varying toxicity and quality filters, and (3) with different domain compositions. First, we quantify the effect of pretraining data age. A temporal shift between evaluation data and pretraining data leads to performance degradation, which is not overcome by finetuning. Second, we explore the effect of quality and toxicity filters, showing a trade-off between performance on standard benchmarks and risk of toxic generations. Our findings indicate there does not exist a one-size-fits-all solution to filtering training data. We also find that the effects of different types of filtering are not predictable from text domain characteristics. Lastly, we empirically validate that the inclusion of heterogeneous data sources, like books and web, is broadly beneficial and warrants greater prioritization. These findings constitute the largest set of experiments to validate, quantify, and expose many undocumented intuitions about text pretraining, which we hope will help support more informed data-centric decisions in LM development.
Visualizing Linguistic Diversity of Text Datasets Synthesized by Large Language Models
May 19, 2023Large language models (LLMs) can be used to generate smaller, more refined datasets via few-shot prompting for benchmarking, fine-tuning or other use cases. However, understanding and evaluating these datasets is difficult, and the failure modes of LLM-generated data are still not well understood. Specifically, the data can be repetitive in surprising ways, not only semantically but also syntactically and lexically. We present LinguisticLens, a novel inter-active visualization tool for making sense of and analyzing syntactic diversity of LLM-generated datasets. LinguisticLens clusters text along syntactic, lexical, and semantic axes. It supports hierarchical visualization of a text dataset, allowing users to quickly scan for an overview and inspect individual examples. The live demo is available at shorturl.at/zHOUV.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.