 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanlike AI Design Increases Anthropomorphism but Yields Divergent Outcomes on Engagement and Trust Globally
Dec 19, 2025Over a billion users across the globe interact with AI systems engineered with increasing sophistication to mimic human traits. This shift has triggered urgent debate regarding Anthropomorphism, the attribution of human characteristics to synthetic agents, and its potential to induce misplaced trust or emotional dependency. However, the causal link between more humanlike AI design and subsequent effects on engagement and trust has not been tested in realistic human-AI interactions with a global user pool. Prevailing safety frameworks continue to rely on theoretical assumptions derived from Western populations, overlooking the global diversity of AI users. Here, we address these gaps through two large-scale cross-national experiments (N=3,500) across 10 diverse nations, involving real-time and open-ended interactions with an AI system. We find that when evaluating an AI's human-likeness, users focus less on the kind of theoretical aspects often cited in policy (e.g., sentience or consciousness), but rather applied, interactional cues like conversation flow or understanding the user's perspective. We also experimentally demonstrate that humanlike design levers can causally increase anthropomorphism among users; however, we do not find that humanlike design universally increases behavioral measures for user engagement and trust, as previous theoretical work suggests. Instead, part of the connection between human-likeness and behavioral outcomes is fractured by culture: specific design choices that foster self-reported trust in AI-systems in some populations (e.g., Brazil) may trigger the opposite result in others (e.g., Japan). Our findings challenge prevailing narratives of inherent risk in humanlike AI design. Instead, we identify a nuanced, culturally mediated landscape of human-AI interaction, which demands that we move beyond a one-size-fits-all approach in AI governance.
What Makes An Expert? Reviewing How ML Researchers Define "Expert"
Oct 31, 2024



Human experts are often engaged in the development of machine learning systems to collect and validate data, consult on algorithm development, and evaluate system performance. At the same time, who counts as an 'expert' and what constitutes 'expertise' is not always explicitly defined. In this work, we review 112 academic publications that explicitly reference 'expert' and 'expertise' and that describe the development of machine learning (ML) systems to survey how expertise is characterized and the role experts play. We find that expertise is often undefined and forms of knowledge outside of formal education and professional certification are rarely sought, which has implications for the kinds of knowledge that are recognized and legitimized in ML development. Moreover, we find that expert knowledge tends to be utilized in ways focused on mining textbook knowledge, such as through data annotation. We discuss the ways experts are engaged in ML development in relation to deskilling, the social construction of expertise, and implications for responsible AI development. We point to a need for reflection and specificity in justifications of domain expert engagement, both as a matter of documentation and reproducibility, as well as a matter of broadening the range of recognized expertise.
D3CODE: Disentangling Disagreements in Data across Cultures on Offensiveness Detection and Evaluation
Apr 16, 2024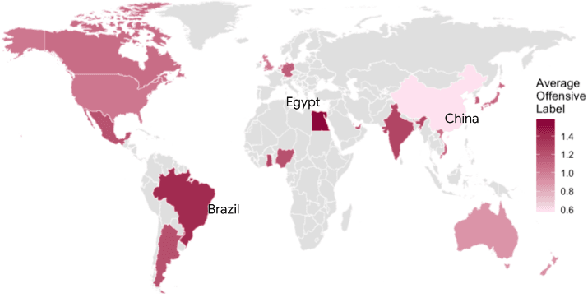
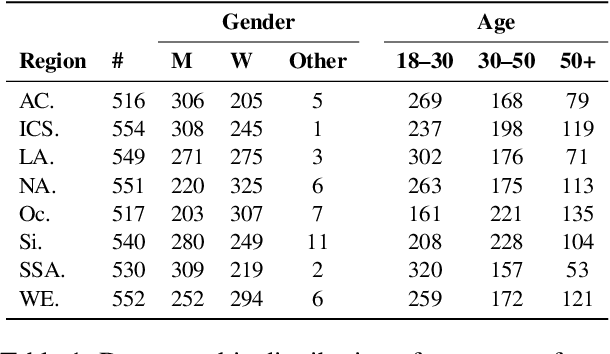
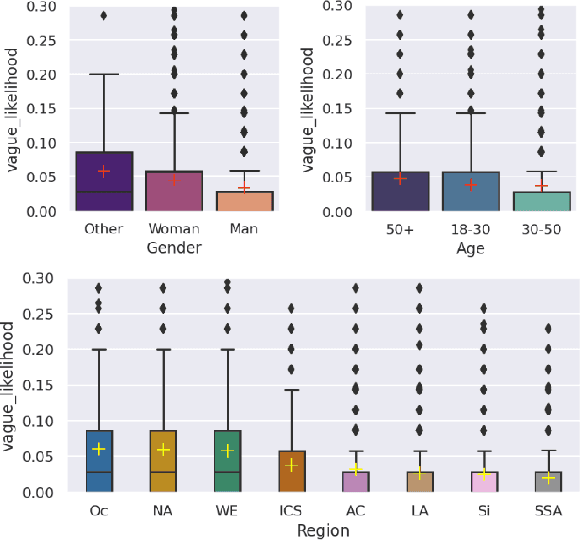
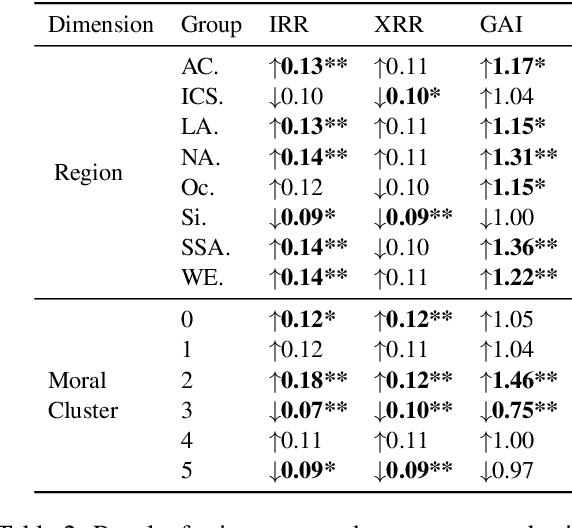
While human annotations play a crucial role in language technologies, annotator subjectivity has long been overlooked in data collection. Recent studies that have critically examined this issue are often situated in the Western context, and solely document differences across age, gender, or racial groups. As a result, NLP research on subjectivity have overlooked the fact that individuals within demographic groups may hold diverse values, which can influence their perceptions beyond their group norms. To effectively incorporate these considerations into NLP pipelines, we need datasets with extensive parallel annotations from various social and cultural groups. In this paper we introduce the \dataset dataset: a large-scale cross-cultural dataset of parallel annotations for offensive language in over 4.5K sentences annotated by a pool of over 4k annotators, balanced across gender and age, from across 21 countries, representing eight geo-cultural regions. The dataset contains annotators' moral values captured along six moral foundations: care, equality, proportionality, authority, loyalty, and purity. Our analyses reveal substantial regional variations in annotators' perceptions that are shaped by individual moral values, offering crucial insights for building pluralistic, culturally sensitive NLP models.
Discipline and Label: A WEIRD Genealogy and Social Theory of Data Annotation
Feb 09, 2024Data annotation remains the sine qua non of machine learning and AI. Recent empirical work on data annotation has begun to highlight the importance of rater diversity for fairness, model performance, and new lines of research have begun to examine the working conditions for data annotation workers, the impacts and role of annotator subjectivity on labels, and the potential psychological harms from aspects of annotation work. This paper outlines a critical genealogy of data annotation; starting with its psychological and perceptual aspects. We draw on similarities with critiques of the rise of computerized lab-based psychological experiments in the 1970's which question whether these experiments permit the generalization of results beyond the laboratory settings within which these results are typically obtained. Do data annotations permit the generalization of results beyond the settings, or locations, in which they were obtained? Psychology is overly reliant on participants from Western, Educated, Industrialized, Rich, and Democratic societies (WEIRD). Many of the people who work as data annotation platform workers, however, are not from WEIRD countries; most data annotation workers are based in Global South countries. Social categorizations and classifications from WEIRD countries are imposed on non-WEIRD annotators through instructions and tasks, and through them, on data, which is then used to train or evaluate AI models in WEIRD countries. We synthesize evidence from several recent lines of research and argue that data annotation is a form of automated social categorization that risks entrenching outdated and static social categories that are in reality dynamic and changing. We propose a framework for understanding the interplay of the global social conditions of data annotation with the subjective phenomenological experience of data annotation work.
Disentangling Perceptions of Offensiveness: Cultural and Moral Correlates
Dec 11, 2023



Perception of offensiveness is inherently subjective, shaped by the lived experiences and socio-cultural values of the perceivers. Recent years have seen substantial efforts to build AI-based tools that can detect offensive language at scale, as a means to moderate social media platforms, and to ensure safety of conversational AI technologies such as ChatGPT and Bard. However, existing approaches treat this task as a technical endeavor, built on top of data annotated for offensiveness by a global crowd workforce without any attention to the crowd workers' provenance or the values their perceptions reflect. We argue that cultural and psychological factors play a vital role in the cognitive processing of offensiveness, which is critical to consider in this context. We re-frame the task of determining offensiveness as essentially a matter of moral judgment -- deciding the boundaries of ethically wrong vs. right language within an implied set of socio-cultural norms. Through a large-scale cross-cultural study based on 4309 participants from 21 countries across 8 cultural regions, we demonstrate substantial cross-cultural differences in perceptions of offensiveness. More importantly, we find that individual moral values play a crucial role in shaping these variations: moral concerns about Care and Purity are significant mediating factors driving cross-cultural differences. These insights are of crucial importance as we build AI models for the pluralistic world, where the values they espouse should aim to respect and account for moral values in diverse geo-cultural contexts.
SoUnD Framework: Analyzing (So)cial Representation in (Un)structured (D)ata
Dec 01, 2023The unstructured nature of data used in foundation model development is a challenge to systematic analyses for making data use and documentation decisions. From a Responsible AI perspective, these decisions often rely upon understanding how people are represented in data. We propose a framework designed to guide analysis of human representation in unstructured data and identify downstream risks. We apply the framework in two toy examples using the Common Crawl web text corpus (C4) and LAION-400M. We also propose a set of hypothetical action steps in service of dataset use, development, and documentation.
A Framework to Assess agreement Among Diverse Rater Groups
Nov 09, 2023Recent advancements in conversational AI have created an urgent need for safety guardrails that prevent users from being exposed to offensive and dangerous content. Much of this work relies on human ratings and feedback, but does not account for the fact that perceptions of offense and safety are inherently subjective and that there may be systematic disagreements between raters that align with their socio-demographic identities. Instead, current machine learning approaches largely ignore rater subjectivity and use gold standards that obscure disagreements (e.g., through majority voting). In order to better understand the socio-cultural leanings of such tasks, we propose a comprehensive disagreement analysis framework to measure systematic diversity in perspectives among different rater subgroups. We then demonstrate its utility by applying this framework to a dataset of human-chatbot conversations rated by a demographically diverse pool of raters. Our analysis reveals specific rater groups that have more diverse perspectives than the rest, and informs demographic axes that are crucial to consider for safety annotations.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
(Re)Defining Expertise in Machine Learning Development
Feb 08, 2023Domain experts are often engaged in the development of machine learning systems in a variety of ways, such as in data collection and evaluation of system performance. At the same time, who counts as an 'expert' and what constitutes 'expertise' is not always explicitly defined. In this project, we conduct a systematic literature review of machine learning research to understand 1) the bases on which expertise is defined and recognized and 2) the roles experts play in ML development. Our goal is to produce a high-level taxonomy to highlight limits and opportunities in how experts are identified and engaged in ML research.
Whose Ground Truth? Accounting for Individual and Collective Identities Underlying Dataset Annotation
Dec 08, 2021Human annotations play a crucial role in machine learning (ML) research and development. However, the ethical considerations around the processes and decisions that go into building ML datasets has not received nearly enough attention. In this paper, we survey an array of literature that provides insights into ethical considerations around crowdsourced dataset annotation. We synthesize these insights, and lay out the challenges in this space along two layers: (1) who the annotator is, and how the annotators' lived experiences can impact their annotations, and (2) the relationship between the annotators and the crowdsourcing platforms and what that relationship affords them. Finally, we put forth a concrete set of recommendations and considerations for dataset developers at various stages of the ML data pipeline: task formulation, selection of annotators, platform and infrastructure choices, dataset analysis and evaluation, and dataset documentation and release.