 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelating Word Embedding Gender Biases to Gender Gaps: A Cross-Cultural Analysis
Jan 23, 2026Modern models for common NLP tasks often employ machine learning techniques and train on journalistic, social media, or other culturally-derived text. These have recently been scrutinized for racial and gender biases, rooting from inherent bias in their training text. These biases are often sub-optimal and recent work poses methods to rectify them; however, these biases may shed light on actual racial or gender gaps in the culture(s) that produced the training text, thereby helping us understand cultural context through big data. This paper presents an approach for quantifying gender bias in word embeddings, and then using them to characterize statistical gender gaps in education, politics, economics, and health. We validate these metrics on 2018 Twitter data spanning 51 U.S. regions and 99 countries. We correlate state and country word embedding biases with 18 international and 5 U.S.-based statistical gender gaps, characterizing regularities and predictive strength.
* 7 pages, 5 figures. Presented at the First Workshop on Gender Bias in Natural Language Processing (GeBNLP 2019)
Balancing Transparency and Accuracy: A Comparative Analysis of Rule-Based and Deep Learning Models in Political Bias Classification
Nov 07, 2024



The unchecked spread of digital information, combined with increasing political polarization and the tendency of individuals to isolate themselves from opposing political viewpoints, has driven researchers to develop systems for automatically detecting political bias in media. This trend has been further fueled by discussions on social media. We explore methods for categorizing bias in US news articles, comparing rule-based and deep learning approaches. The study highlights the sensitivity of modern self-learning systems to unconstrained data ingestion, while reconsidering the strengths of traditional rule-based systems. Applying both models to left-leaning (CNN) and right-leaning (FOX) news articles, we assess their effectiveness on data beyond the original training and test sets.This analysis highlights each model's accuracy, offers a framework for exploring deep-learning explainability, and sheds light on political bias in US news media. We contrast the opaque architecture of a deep learning model with the transparency of a linguistically informed rule-based model, showing that the rule-based model performs consistently across different data conditions and offers greater transparency, whereas the deep learning model is dependent on the training set and struggles with unseen data.
Socially Responsible Data for Large Multilingual Language Models
Sep 08, 2024
Large Language Models (LLMs) have rapidly increased in size and apparent capabilities in the last three years, but their training data is largely English text. There is growing interest in multilingual LLMs, and various efforts are striving for models to accommodate languages of communities outside of the Global North, which include many languages that have been historically underrepresented in digital realms. These languages have been coined as "low resource languages" or "long-tail languages", and LLMs performance on these languages is generally poor. While expanding the use of LLMs to more languages may bring many potential benefits, such as assisting cross-community communication and language preservation, great care must be taken to ensure that data collection on these languages is not extractive and that it does not reproduce exploitative practices of the past. Collecting data from languages spoken by previously colonized people, indigenous people, and non-Western languages raises many complex sociopolitical and ethical questions, e.g., around consent, cultural safety, and data sovereignty. Furthermore, linguistic complexity and cultural nuances are often lost in LLMs. This position paper builds on recent scholarship, and our own work, and outlines several relevant social, cultural, and ethical considerations and potential ways to mitigate them through qualitative research, community partnerships, and participatory design approaches. We provide twelve recommendations for consideration when collecting language data on underrepresented language communities outside of the Global North.
Discipline and Label: A WEIRD Genealogy and Social Theory of Data Annotation
Feb 09, 2024Data annotation remains the sine qua non of machine learning and AI. Recent empirical work on data annotation has begun to highlight the importance of rater diversity for fairness, model performance, and new lines of research have begun to examine the working conditions for data annotation workers, the impacts and role of annotator subjectivity on labels, and the potential psychological harms from aspects of annotation work. This paper outlines a critical genealogy of data annotation; starting with its psychological and perceptual aspects. We draw on similarities with critiques of the rise of computerized lab-based psychological experiments in the 1970's which question whether these experiments permit the generalization of results beyond the laboratory settings within which these results are typically obtained. Do data annotations permit the generalization of results beyond the settings, or locations, in which they were obtained? Psychology is overly reliant on participants from Western, Educated, Industrialized, Rich, and Democratic societies (WEIRD). Many of the people who work as data annotation platform workers, however, are not from WEIRD countries; most data annotation workers are based in Global South countries. Social categorizations and classifications from WEIRD countries are imposed on non-WEIRD annotators through instructions and tasks, and through them, on data, which is then used to train or evaluate AI models in WEIRD countries. We synthesize evidence from several recent lines of research and argue that data annotation is a form of automated social categorization that risks entrenching outdated and static social categories that are in reality dynamic and changing. We propose a framework for understanding the interplay of the global social conditions of data annotation with the subjective phenomenological experience of data annotation work.
Assessing LLMs for Moral Value Pluralism
Dec 08, 2023



The fields of AI current lacks methods to quantitatively assess and potentially alter the moral values inherent in the output of large language models (LLMs). However, decades of social science research has developed and refined widely-accepted moral value surveys, such as the World Values Survey (WVS), eliciting value judgments from direct questions in various geographies. We have turned those questions into value statements and use NLP to compute to how well popular LLMs are aligned with moral values for various demographics and cultures. While the WVS is accepted as an explicit assessment of values, we lack methods for assessing implicit moral and cultural values in media, e.g., encountered in social media, political rhetoric, narratives, and generated by AI systems such as LLMs that are increasingly present in our daily lives. As we consume online content and utilize LLM outputs, we might ask, which moral values are being implicitly promoted or undercut, or -- in the case of LLMs -- if they are intending to represent a cultural identity, are they doing so consistently? In this paper we utilize a Recognizing Value Resonance (RVR) NLP model to identify WVS values that resonate and conflict with a given passage of output text. We apply RVR to the text generated by LLMs to characterize implicit moral values, allowing us to quantify the moral/cultural distance between LLMs and various demographics that have been surveyed using the WVS. In line with other work we find that LLMs exhibit several Western-centric value biases; they overestimate how conservative people in non-Western countries are, they are less accurate in representing gender for non-Western countries, and portray older populations as having more traditional values. Our results highlight value misalignment and age groups, and a need for social science informed technological solutions addressing value plurality in LLMs.
From Unstructured Text to Causal Knowledge Graphs: A Transformer-Based Approach
Feb 23, 2022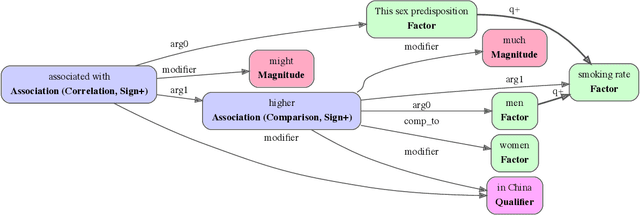
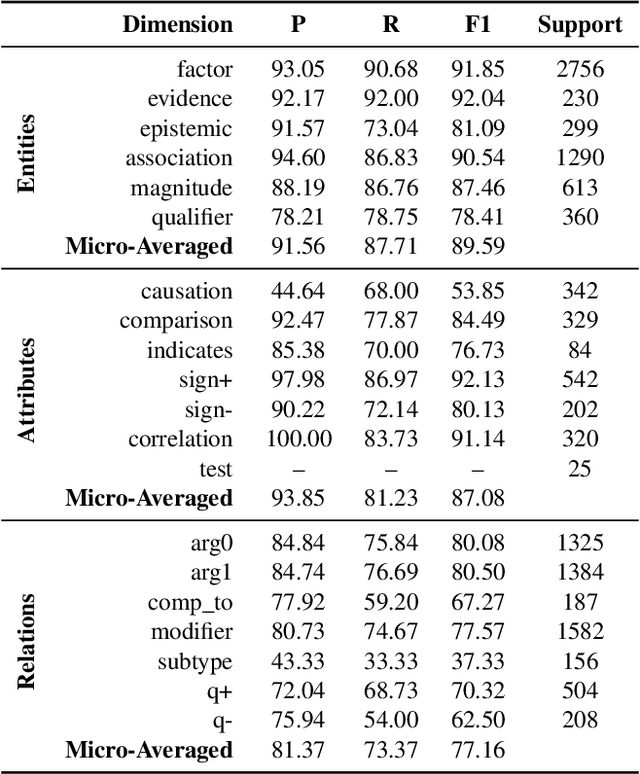
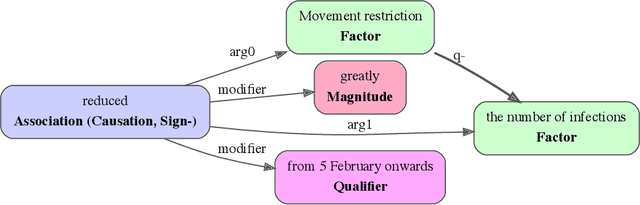
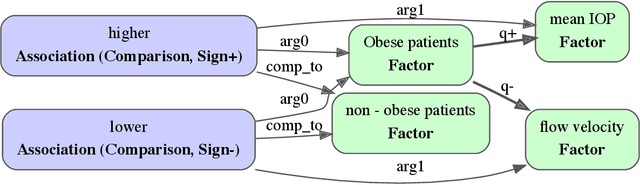
Qualitative causal relationships compactly express the direction, dependency, temporal constraints, and monotonicity constraints of discrete or continuous interactions in the world. In everyday or academic language, we may express interactions between quantities (e.g., sleep decreases stress), between discrete events or entities (e.g., a protein inhibits another protein's transcription), or between intentional or functional factors (e.g., hospital patients pray to relieve their pain). Extracting and representing these diverse causal relations are critical for cognitive systems that operate in domains spanning from scientific discovery to social science. This paper presents a transformer-based NLP architecture that jointly extracts knowledge graphs including (1) variables or factors described in language, (2) qualitative causal relationships over these variables, (3) qualifiers and magnitudes that constrain these causal relationships, and (4) word senses to localize each extracted node within a large ontology. We do not claim that our transformer-based architecture is itself a cognitive system; however, we provide evidence of its accurate knowledge graph extraction in real-world domains and the practicality of its resulting knowledge graphs for cognitive systems that perform graph-based reasoning. We demonstrate this approach and include promising results in two use cases, processing textual inputs from academic publications, news articles, and social media.