 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelating Word Embedding Gender Biases to Gender Gaps: A Cross-Cultural Analysis
Jan 23, 2026Modern models for common NLP tasks often employ machine learning techniques and train on journalistic, social media, or other culturally-derived text. These have recently been scrutinized for racial and gender biases, rooting from inherent bias in their training text. These biases are often sub-optimal and recent work poses methods to rectify them; however, these biases may shed light on actual racial or gender gaps in the culture(s) that produced the training text, thereby helping us understand cultural context through big data. This paper presents an approach for quantifying gender bias in word embeddings, and then using them to characterize statistical gender gaps in education, politics, economics, and health. We validate these metrics on 2018 Twitter data spanning 51 U.S. regions and 99 countries. We correlate state and country word embedding biases with 18 international and 5 U.S.-based statistical gender gaps, characterizing regularities and predictive strength.
* 7 pages, 5 figures. Presented at the First Workshop on Gender Bias in Natural Language Processing (GeBNLP 2019)
Assessing LLMs for Moral Value Pluralism
Dec 08, 2023



The fields of AI current lacks methods to quantitatively assess and potentially alter the moral values inherent in the output of large language models (LLMs). However, decades of social science research has developed and refined widely-accepted moral value surveys, such as the World Values Survey (WVS), eliciting value judgments from direct questions in various geographies. We have turned those questions into value statements and use NLP to compute to how well popular LLMs are aligned with moral values for various demographics and cultures. While the WVS is accepted as an explicit assessment of values, we lack methods for assessing implicit moral and cultural values in media, e.g., encountered in social media, political rhetoric, narratives, and generated by AI systems such as LLMs that are increasingly present in our daily lives. As we consume online content and utilize LLM outputs, we might ask, which moral values are being implicitly promoted or undercut, or -- in the case of LLMs -- if they are intending to represent a cultural identity, are they doing so consistently? In this paper we utilize a Recognizing Value Resonance (RVR) NLP model to identify WVS values that resonate and conflict with a given passage of output text. We apply RVR to the text generated by LLMs to characterize implicit moral values, allowing us to quantify the moral/cultural distance between LLMs and various demographics that have been surveyed using the WVS. In line with other work we find that LLMs exhibit several Western-centric value biases; they overestimate how conservative people in non-Western countries are, they are less accurate in representing gender for non-Western countries, and portray older populations as having more traditional values. Our results highlight value misalignment and age groups, and a need for social science informed technological solutions addressing value plurality in LLMs.
From Unstructured Text to Causal Knowledge Graphs: A Transformer-Based Approach
Feb 23, 2022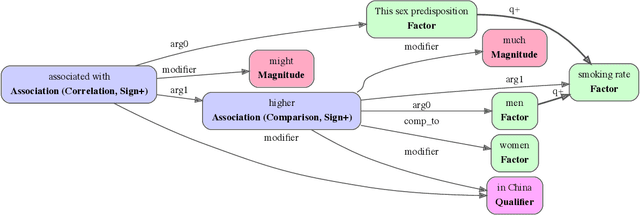
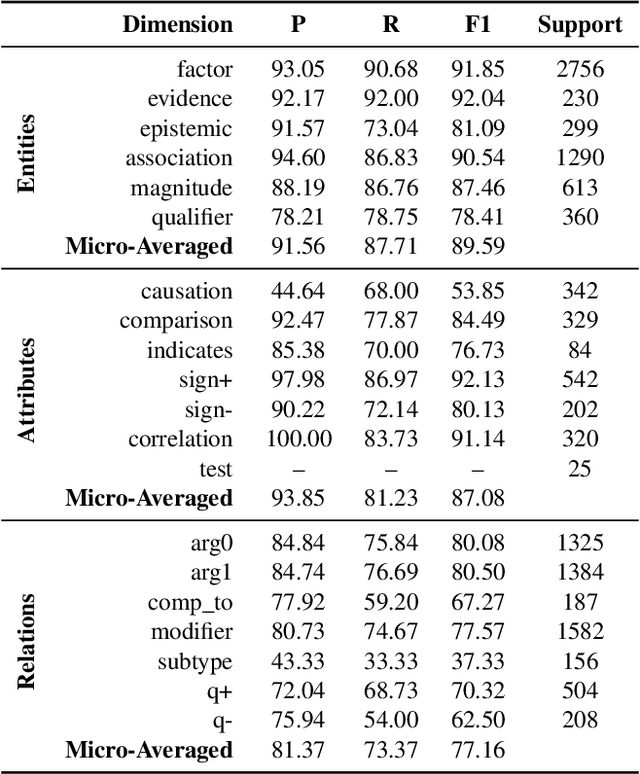
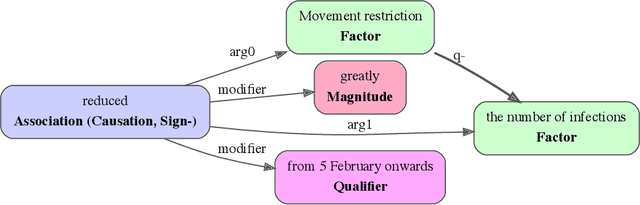
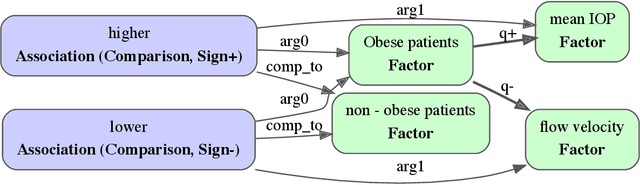
Qualitative causal relationships compactly express the direction, dependency, temporal constraints, and monotonicity constraints of discrete or continuous interactions in the world. In everyday or academic language, we may express interactions between quantities (e.g., sleep decreases stress), between discrete events or entities (e.g., a protein inhibits another protein's transcription), or between intentional or functional factors (e.g., hospital patients pray to relieve their pain). Extracting and representing these diverse causal relations are critical for cognitive systems that operate in domains spanning from scientific discovery to social science. This paper presents a transformer-based NLP architecture that jointly extracts knowledge graphs including (1) variables or factors described in language, (2) qualitative causal relationships over these variables, (3) qualifiers and magnitudes that constrain these causal relationships, and (4) word senses to localize each extracted node within a large ontology. We do not claim that our transformer-based architecture is itself a cognitive system; however, we provide evidence of its accurate knowledge graph extraction in real-world domains and the practicality of its resulting knowledge graphs for cognitive systems that perform graph-based reasoning. We demonstrate this approach and include promising results in two use cases, processing textual inputs from academic publications, news articles, and social media.
Provenance-Based Interpretation of Multi-Agent Information Analysis
Nov 08, 2020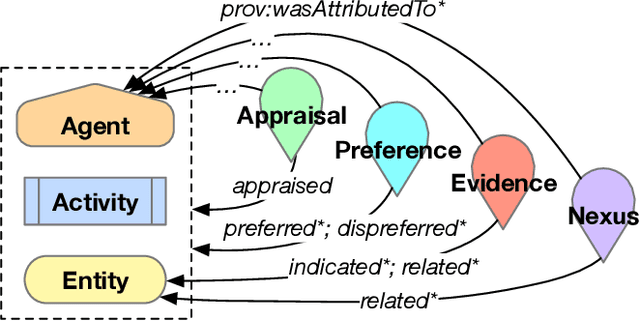
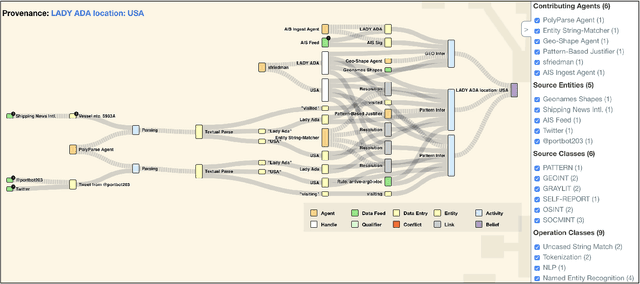
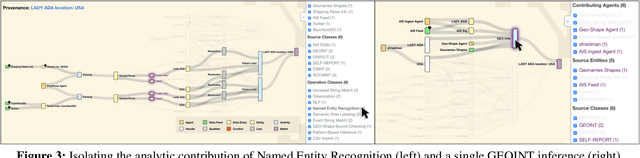
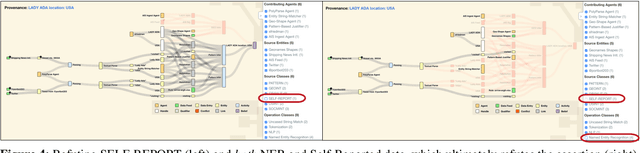
Analytic software tools and workflows are increasing in capability, complexity, number, and scale, and the integrity of our workflows is as important as ever. Specifically, we must be able to inspect the process of analytic workflows to assess (1) confidence of the conclusions, (2) risks and biases of the operations involved, (3) sensitivity of the conclusions to sources and agents, (4) impact and pertinence of various sources and agents, and (5) diversity of the sources that support the conclusions. We present an approach that tracks agents' provenance with PROV-O in conjunction with agents' appraisals and evidence links (expressed in our novel DIVE ontology). Together, PROV-O and DIVE enable dynamic propagation of confidence and counter-factual refutation to improve human-machine trust and analytic integrity. We demonstrate representative software developed for user interaction with that provenance, and discuss key needs for organizations adopting such approaches. We demonstrate all of these assessments in a multi-agent analysis scenario, using an interactive web-based information validation UI.
* 6 pages, 5 figures, appears in Proceedings of TaPP 2020
Combining Deep Learning and Qualitative Spatial Reasoning to Learn Complex Structures from Sparse Examples with Noise
Nov 27, 2018
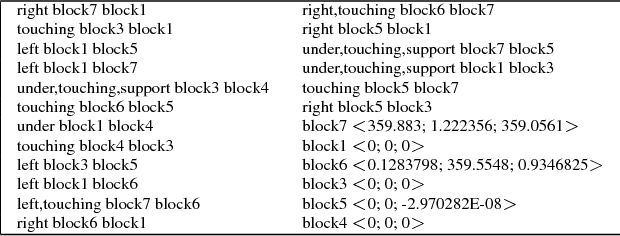


Many modern machine learning approaches require vast amounts of training data to learn new concepts; conversely, human learning often requires few examples--sometimes only one--from which the learner can abstract structural concepts. We present a novel approach to introducing new spatial structures to an AI agent, combining deep learning over qualitative spatial relations with various heuristic search algorithms. The agent extracts spatial relations from a sparse set of noisy examples of block-based structures, and trains convolutional and sequential models of those relation sets. To create novel examples of similar structures, the agent begins placing blocks on a virtual table, uses a CNN to predict the most similar complete example structure after each placement, an LSTM to predict the most likely set of remaining moves needed to complete it, and recommends one using heuristic search. We verify that the agent learned the concept by observing its virtual block-building activities, wherein it ranks each potential subsequent action toward building its learned concept. We empirically assess this approach with human participants' ratings of the block structures. Initial results and qualitative evaluations of structures generated by the trained agent show where it has generalized concepts from the training data, which heuristics perform best within the search space, and how we might improve learning and execution.