 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Explaining Hate Speech Detection with Moral Rationales
Jan 07, 2026Hate speech detection models rely on surface-level lexical features, increasing vulnerability to spurious correlations and limiting robustness, cultural contextualization, and interpretability. We propose Supervised Moral Rationale Attention (SMRA), the first self-explaining hate speech detection framework to incorporate moral rationales as direct supervision for attention alignment. Based on Moral Foundations Theory, SMRA aligns token-level attention with expert-annotated moral rationales, guiding models to attend to morally salient spans rather than spurious lexical patterns. Unlike prior rationale-supervised or post-hoc approaches, SMRA integrates moral rationale supervision directly into the training objective, producing inherently interpretable and contextualized explanations. To support our framework, we also introduce HateBRMoralXplain, a Brazilian Portuguese benchmark dataset annotated with hate labels, moral categories, token-level moral rationales, and socio-political metadata. Across binary hate speech detection and multi-label moral sentiment classification, SMRA consistently improves performance (e.g., +0.9 and +1.5 F1, respectively) while substantially enhancing explanation faithfulness, increasing IoU F1 (+7.4 pp) and Token F1 (+5.0 pp). Although explanations become more concise, sufficiency improves (+2.3 pp) and fairness remains stable, indicating more faithful rationales without performance or bias trade-offs
Socially Responsible Data for Large Multilingual Language Models
Sep 08, 2024
Large Language Models (LLMs) have rapidly increased in size and apparent capabilities in the last three years, but their training data is largely English text. There is growing interest in multilingual LLMs, and various efforts are striving for models to accommodate languages of communities outside of the Global North, which include many languages that have been historically underrepresented in digital realms. These languages have been coined as "low resource languages" or "long-tail languages", and LLMs performance on these languages is generally poor. While expanding the use of LLMs to more languages may bring many potential benefits, such as assisting cross-community communication and language preservation, great care must be taken to ensure that data collection on these languages is not extractive and that it does not reproduce exploitative practices of the past. Collecting data from languages spoken by previously colonized people, indigenous people, and non-Western languages raises many complex sociopolitical and ethical questions, e.g., around consent, cultural safety, and data sovereignty. Furthermore, linguistic complexity and cultural nuances are often lost in LLMs. This position paper builds on recent scholarship, and our own work, and outlines several relevant social, cultural, and ethical considerations and potential ways to mitigate them through qualitative research, community partnerships, and participatory design approaches. We provide twelve recommendations for consideration when collecting language data on underrepresented language communities outside of the Global North.
Beyond Model Interpretability: Socio-Structural Explanations in Machine Learning
Sep 05, 2024What is it to interpret the outputs of an opaque machine learning model. One approach is to develop interpretable machine learning techniques. These techniques aim to show how machine learning models function by providing either model centric local or global explanations, which can be based on mechanistic interpretations revealing the inner working mechanisms of models or nonmechanistic approximations showing input feature output data relationships. In this paper, we draw on social philosophy to argue that interpreting machine learning outputs in certain normatively salient domains could require appealing to a third type of explanation that we call sociostructural explanation. The relevance of this explanation type is motivated by the fact that machine learning models are not isolated entities but are embedded within and shaped by social structures. Sociostructural explanations aim to illustrate how social structures contribute to and partially explain the outputs of machine learning models. We demonstrate the importance of sociostructural explanations by examining a racially biased healthcare allocation algorithm. Our proposal highlights the need for transparency beyond model interpretability, understanding the outputs of machine learning systems could require a broader analysis that extends beyond the understanding of the machine learning model itself.
Discipline and Label: A WEIRD Genealogy and Social Theory of Data Annotation
Feb 09, 2024Data annotation remains the sine qua non of machine learning and AI. Recent empirical work on data annotation has begun to highlight the importance of rater diversity for fairness, model performance, and new lines of research have begun to examine the working conditions for data annotation workers, the impacts and role of annotator subjectivity on labels, and the potential psychological harms from aspects of annotation work. This paper outlines a critical genealogy of data annotation; starting with its psychological and perceptual aspects. We draw on similarities with critiques of the rise of computerized lab-based psychological experiments in the 1970's which question whether these experiments permit the generalization of results beyond the laboratory settings within which these results are typically obtained. Do data annotations permit the generalization of results beyond the settings, or locations, in which they were obtained? Psychology is overly reliant on participants from Western, Educated, Industrialized, Rich, and Democratic societies (WEIRD). Many of the people who work as data annotation platform workers, however, are not from WEIRD countries; most data annotation workers are based in Global South countries. Social categorizations and classifications from WEIRD countries are imposed on non-WEIRD annotators through instructions and tasks, and through them, on data, which is then used to train or evaluate AI models in WEIRD countries. We synthesize evidence from several recent lines of research and argue that data annotation is a form of automated social categorization that risks entrenching outdated and static social categories that are in reality dynamic and changing. We propose a framework for understanding the interplay of the global social conditions of data annotation with the subjective phenomenological experience of data annotation work.
Assessing LLMs for Moral Value Pluralism
Dec 08, 2023



The fields of AI current lacks methods to quantitatively assess and potentially alter the moral values inherent in the output of large language models (LLMs). However, decades of social science research has developed and refined widely-accepted moral value surveys, such as the World Values Survey (WVS), eliciting value judgments from direct questions in various geographies. We have turned those questions into value statements and use NLP to compute to how well popular LLMs are aligned with moral values for various demographics and cultures. While the WVS is accepted as an explicit assessment of values, we lack methods for assessing implicit moral and cultural values in media, e.g., encountered in social media, political rhetoric, narratives, and generated by AI systems such as LLMs that are increasingly present in our daily lives. As we consume online content and utilize LLM outputs, we might ask, which moral values are being implicitly promoted or undercut, or -- in the case of LLMs -- if they are intending to represent a cultural identity, are they doing so consistently? In this paper we utilize a Recognizing Value Resonance (RVR) NLP model to identify WVS values that resonate and conflict with a given passage of output text. We apply RVR to the text generated by LLMs to characterize implicit moral values, allowing us to quantify the moral/cultural distance between LLMs and various demographics that have been surveyed using the WVS. In line with other work we find that LLMs exhibit several Western-centric value biases; they overestimate how conservative people in non-Western countries are, they are less accurate in representing gender for non-Western countries, and portray older populations as having more traditional values. Our results highlight value misalignment and age groups, and a need for social science informed technological solutions addressing value plurality in LLMs.
Walking the Walk of AI Ethics: Organizational Challenges and the Individualization of Risk among Ethics Entrepreneurs
May 16, 2023Amidst decline in public trust in technology, computing ethics have taken center stage, and critics have raised questions about corporate ethics washing. Yet few studies examine the actual implementation of AI ethics values in technology companies. Based on a qualitative analysis of technology workers tasked with integrating AI ethics into product development, we find that workers experience an environment where policies, practices, and outcomes are decoupled. We analyze AI ethics workers as ethics entrepreneurs who work to institutionalize new ethics-related practices within organizations. We show that ethics entrepreneurs face three major barriers to their work. First, they struggle to have ethics prioritized in an environment centered around software product launches. Second, ethics are difficult to quantify in a context where company goals are incentivized by metrics. Third, the frequent reorganization of teams makes it difficult to access knowledge and maintain relationships central to their work. Consequently, individuals take on great personal risk when raising ethics issues, especially when they come from marginalized backgrounds. These findings shed light on complex dynamics of institutional change at technology companies.
The Equitable AI Research Roundtable (EARR): Towards Community-Based Decision Making in Responsible AI Development
Mar 14, 2023This paper reports on our initial evaluation of The Equitable AI Research Roundtable -- a coalition of experts in law, education, community engagement, social justice, and technology. EARR was created in collaboration among a large tech firm, nonprofits, NGO research institutions, and universities to provide critical research based perspectives and feedback on technology's emergent ethical and social harms. Through semi-structured workshops and discussions within the large tech firm, EARR has provided critical perspectives and feedback on how to conceptualize equity and vulnerability as they relate to AI technology. We outline three principles in practice of how EARR has operated thus far that are especially relevant to the concerns of the FAccT community: how EARR expands the scope of expertise in AI development, how it fosters opportunities for epistemic curiosity and responsibility, and that it creates a space for mutual learning. This paper serves as both an analysis and translation of lessons learned through this engagement approach, and the possibilities for future research.
From plane crashes to algorithmic harm: applicability of safety engineering frameworks for responsible ML
Oct 06, 2022
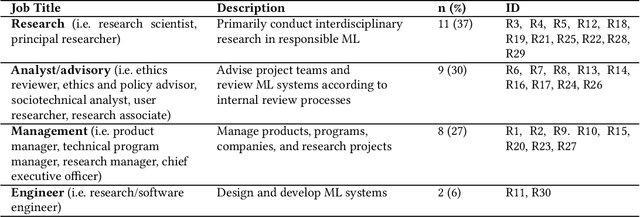
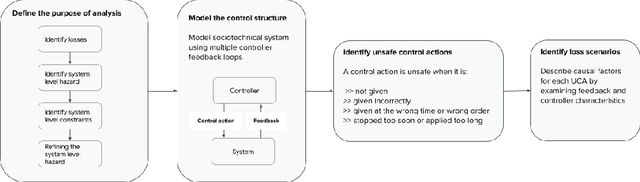
Inappropriate design and deployment of machine learning (ML) systems leads to negative downstream social and ethical impact -- described here as social and ethical risks -- for users, society and the environment. Despite the growing need to regulate ML systems, current processes for assessing and mitigating risks are disjointed and inconsistent. We interviewed 30 industry practitioners on their current social and ethical risk management practices, and collected their first reactions on adapting safety engineering frameworks into their practice -- namely, System Theoretic Process Analysis (STPA) and Failure Mode and Effects Analysis (FMEA). Our findings suggest STPA/FMEA can provide appropriate structure toward social and ethical risk assessment and mitigation processes. However, we also find nontrivial challenges in integrating such frameworks in the fast-paced culture of the ML industry. We call on the ML research community to strengthen existing frameworks and assess their efficacy, ensuring that ML systems are safer for all people.
Healthsheet: Development of a Transparency Artifact for Health Datasets
Feb 26, 2022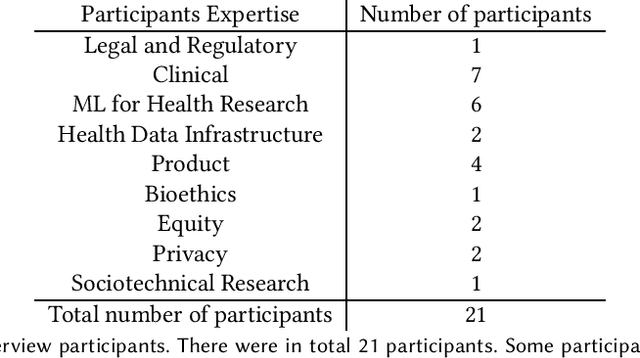
Machine learning (ML) approaches have demonstrated promising results in a wide range of healthcare applications. Data plays a crucial role in developing ML-based healthcare systems that directly affect people's lives. Many of the ethical issues surrounding the use of ML in healthcare stem from structural inequalities underlying the way we collect, use, and handle data. Developing guidelines to improve documentation practices regarding the creation, use, and maintenance of ML healthcare datasets is therefore of critical importance. In this work, we introduce Healthsheet, a contextualized adaptation of the original datasheet questionnaire ~\cite{gebru2018datasheets} for health-specific applications. Through a series of semi-structured interviews, we adapt the datasheets for healthcare data documentation. As part of the Healthsheet development process and to understand the obstacles researchers face in creating datasheets, we worked with three publicly-available healthcare datasets as our case studies, each with different types of structured data: Electronic health Records (EHR), clinical trial study data, and smartphone-based performance outcome measures. Our findings from the interviewee study and case studies show 1) that datasheets should be contextualized for healthcare, 2) that despite incentives to adopt accountability practices such as datasheets, there is a lack of consistency in the broader use of these practices 3) how the ML for health community views datasheets and particularly \textit{Healthsheets} as diagnostic tool to surface the limitations and strength of datasets and 4) the relative importance of different fields in the datasheet to healthcare concerns.
Fairness Preferences, Actual and Hypothetical: A Study of Crowdworker Incentives
Dec 08, 2020
How should we decide which fairness criteria or definitions to adopt in machine learning systems? To answer this question, we must study the fairness preferences of actual users of machine learning systems. Stringent parity constraints on treatment or impact can come with trade-offs, and may not even be preferred by the social groups in question (Zafar et al., 2017). Thus it might be beneficial to elicit what the group's preferences are, rather than rely on a priori defined mathematical fairness constraints. Simply asking for self-reported rankings of users is challenging because research has shown that there are often gaps between people's stated and actual preferences(Bernheim et al., 2013). This paper outlines a research program and experimental designs for investigating these questions. Participants in the experiments are invited to perform a set of tasks in exchange for a base payment--they are told upfront that they may receive a bonus later on, and the bonus could depend on some combination of output quantity and quality. The same group of workers then votes on a bonus payment structure, to elicit preferences. The voting is hypothetical (not tied to an outcome) for half the group and actual (tied to the actual payment outcome) for the other half, so that we can understand the relation between a group's actual preferences and hypothetical (stated) preferences. Connections and lessons from fairness in machine learning are explored.