 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBranching Out: Broadening AI Measurement and Evaluation with Measurement Trees
Sep 30, 2025This paper introduces \textit{measurement trees}, a novel class of metrics designed to combine various constructs into an interpretable multi-level representation of a measurand. Unlike conventional metrics that yield single values, vectors, surfaces, or categories, measurement trees produce a hierarchical directed graph in which each node summarizes its children through user-defined aggregation methods. In response to recent calls to expand the scope of AI system evaluation, measurement trees enhance metric transparency and facilitate the integration of heterogeneous evidence, including, e.g., agentic, business, energy-efficiency, sociotechnical, or security signals. We present definitions and examples, demonstrate practical utility through a large-scale measurement exercise, and provide accompanying open-source Python code. By operationalizing a transparent approach to measurement of complex constructs, this work offers a principled foundation for broader and more interpretable AI evaluation.
CrowdWorkSheets: Accounting for Individual and Collective Identities Underlying Crowdsourced Dataset Annotation
Jun 09, 2022Human annotated data plays a crucial role in machine learning (ML) research and development. However, the ethical considerations around the processes and decisions that go into dataset annotation have not received nearly enough attention. In this paper, we survey an array of literature that provides insights into ethical considerations around crowdsourced dataset annotation. We synthesize these insights, and lay out the challenges in this space along two layers: (1) who the annotator is, and how the annotators' lived experiences can impact their annotations, and (2) the relationship between the annotators and the crowdsourcing platforms, and what that relationship affords them. Finally, we introduce a novel framework, CrowdWorkSheets, for dataset developers to facilitate transparent documentation of key decisions points at various stages of the data annotation pipeline: task formulation, selection of annotators, platform and infrastructure choices, dataset analysis and evaluation, and dataset release and maintenance.
Healthsheet: Development of a Transparency Artifact for Health Datasets
Feb 26, 2022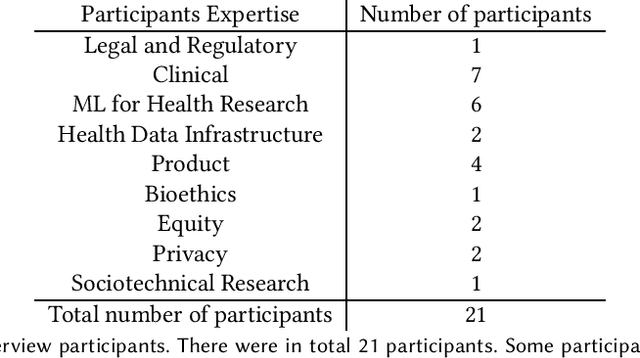
Machine learning (ML) approaches have demonstrated promising results in a wide range of healthcare applications. Data plays a crucial role in developing ML-based healthcare systems that directly affect people's lives. Many of the ethical issues surrounding the use of ML in healthcare stem from structural inequalities underlying the way we collect, use, and handle data. Developing guidelines to improve documentation practices regarding the creation, use, and maintenance of ML healthcare datasets is therefore of critical importance. In this work, we introduce Healthsheet, a contextualized adaptation of the original datasheet questionnaire ~\cite{gebru2018datasheets} for health-specific applications. Through a series of semi-structured interviews, we adapt the datasheets for healthcare data documentation. As part of the Healthsheet development process and to understand the obstacles researchers face in creating datasheets, we worked with three publicly-available healthcare datasets as our case studies, each with different types of structured data: Electronic health Records (EHR), clinical trial study data, and smartphone-based performance outcome measures. Our findings from the interviewee study and case studies show 1) that datasheets should be contextualized for healthcare, 2) that despite incentives to adopt accountability practices such as datasheets, there is a lack of consistency in the broader use of these practices 3) how the ML for health community views datasheets and particularly \textit{Healthsheets} as diagnostic tool to surface the limitations and strength of datasets and 4) the relative importance of different fields in the datasheet to healthcare concerns.