 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealthsheet: Development of a Transparency Artifact for Health Datasets
Paper and Code
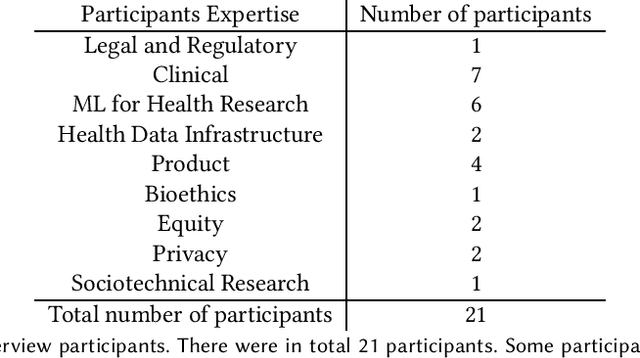
Machine learning (ML) approaches have demonstrated promising results in a wide range of healthcare applications. Data plays a crucial role in developing ML-based healthcare systems that directly affect people's lives. Many of the ethical issues surrounding the use of ML in healthcare stem from structural inequalities underlying the way we collect, use, and handle data. Developing guidelines to improve documentation practices regarding the creation, use, and maintenance of ML healthcare datasets is therefore of critical importance. In this work, we introduce Healthsheet, a contextualized adaptation of the original datasheet questionnaire ~\cite{gebru2018datasheets} for health-specific applications. Through a series of semi-structured interviews, we adapt the datasheets for healthcare data documentation. As part of the Healthsheet development process and to understand the obstacles researchers face in creating datasheets, we worked with three publicly-available healthcare datasets as our case studies, each with different types of structured data: Electronic health Records (EHR), clinical trial study data, and smartphone-based performance outcome measures. Our findings from the interviewee study and case studies show 1) that datasheets should be contextualized for healthcare, 2) that despite incentives to adopt accountability practices such as datasheets, there is a lack of consistency in the broader use of these practices 3) how the ML for health community views datasheets and particularly \textit{Healthsheets} as diagnostic tool to surface the limitations and strength of datasets and 4) the relative importance of different fields in the datasheet to healthcare concerns.