 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLength of Stay prediction for Hospital Management using Domain Adaptation
Jun 29, 2023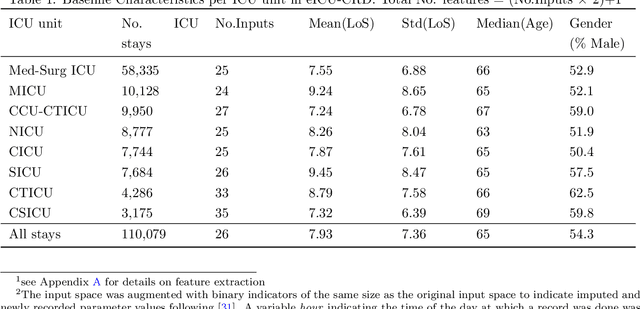
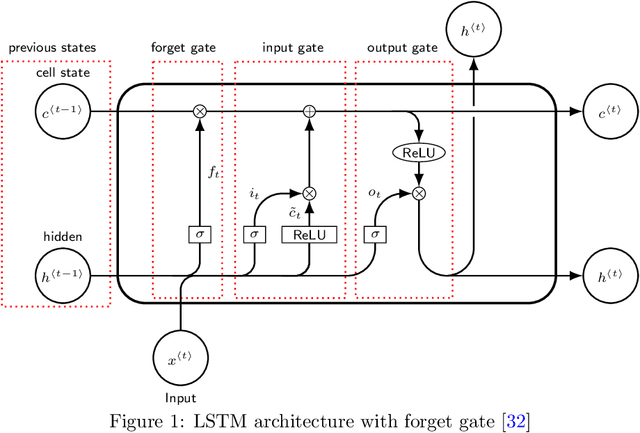
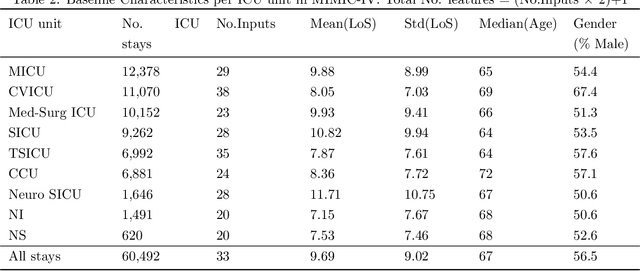
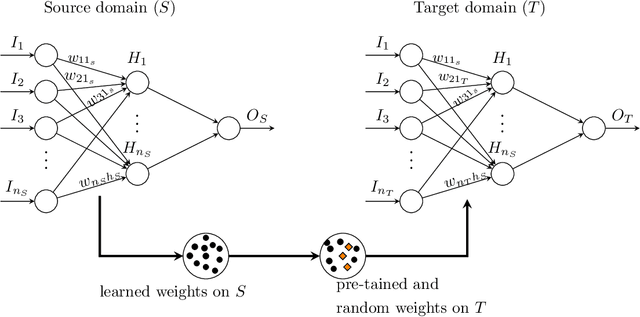
Inpatient length of stay (LoS) is an important managerial metric which if known in advance can be used to efficiently plan admissions, allocate resources and improve care. Using historical patient data and machine learning techniques, LoS prediction models can be developed. Ethically, these models can not be used for patient discharge in lieu of unit heads but are of utmost necessity for hospital management systems in charge of effective hospital planning. Therefore, the design of the prediction system should be adapted to work in a true hospital setting. In this study, we predict early hospital LoS at the granular level of admission units by applying domain adaptation to leverage information learned from a potential source domain. Time-varying data from 110,079 and 60,492 patient stays to 8 and 9 intensive care units were respectively extracted from eICU-CRD and MIMIC-IV. These were fed into a Long-Short Term Memory and a Fully connected network to train a source domain model, the weights of which were transferred either partially or fully to initiate training in target domains. Shapley Additive exPlanations (SHAP) algorithms were used to study the effect of weight transfer on model explanability. Compared to the benchmark, the proposed weight transfer model showed statistically significant gains in prediction accuracy (between 1% and 5%) as well as computation time (up to 2hrs) for some target domains. The proposed method thus provides an adapted clinical decision support system for hospital management that can ease processes of data access via ethical committee, computation infrastructures and time.
Healthsheet: Development of a Transparency Artifact for Health Datasets
Feb 26, 2022
Machine learning (ML) approaches have demonstrated promising results in a wide range of healthcare applications. Data plays a crucial role in developing ML-based healthcare systems that directly affect people's lives. Many of the ethical issues surrounding the use of ML in healthcare stem from structural inequalities underlying the way we collect, use, and handle data. Developing guidelines to improve documentation practices regarding the creation, use, and maintenance of ML healthcare datasets is therefore of critical importance. In this work, we introduce Healthsheet, a contextualized adaptation of the original datasheet questionnaire ~\cite{gebru2018datasheets} for health-specific applications. Through a series of semi-structured interviews, we adapt the datasheets for healthcare data documentation. As part of the Healthsheet development process and to understand the obstacles researchers face in creating datasheets, we worked with three publicly-available healthcare datasets as our case studies, each with different types of structured data: Electronic health Records (EHR), clinical trial study data, and smartphone-based performance outcome measures. Our findings from the interviewee study and case studies show 1) that datasheets should be contextualized for healthcare, 2) that despite incentives to adopt accountability practices such as datasheets, there is a lack of consistency in the broader use of these practices 3) how the ML for health community views datasheets and particularly \textit{Healthsheets} as diagnostic tool to surface the limitations and strength of datasets and 4) the relative importance of different fields in the datasheet to healthcare concerns.
Fair Wrapping for Black-box Predictions
Feb 16, 2022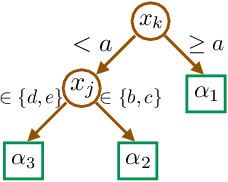
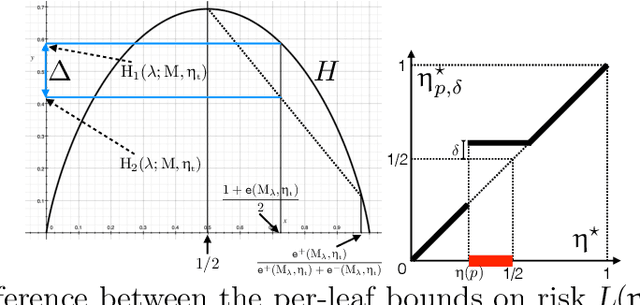
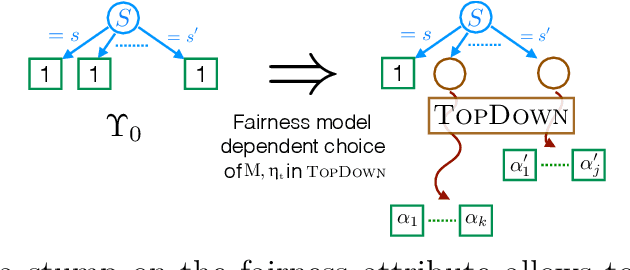
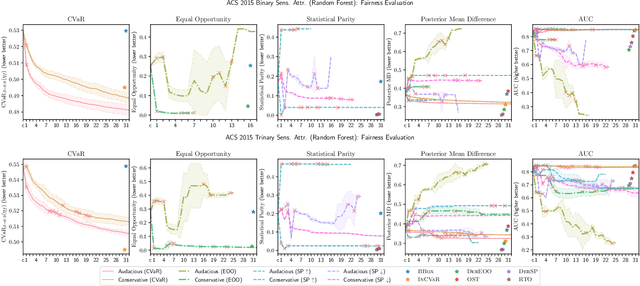
We introduce a new family of techniques to post-process ("wrap") a black-box classifier in order to reduce its bias. Our technique builds on the recent analysis of improper loss functions whose optimisation can correct any twist in prediction, unfairness being treated as a twist. In the post-processing, we learn a wrapper function which we define as an {\alpha}-tree, which modifies the prediction. We provide two generic boosting algorithms to learn {\alpha}-trees. We show that our modification has appealing properties in terms of composition of{\alpha}-trees, generalization, interpretability, and KL divergence between modified and original predictions. We exemplify the use of our technique in three fairness notions: conditional value at risk, equality of opportunity, and statistical parity; and provide experiments on several readily available datasets.
Fairness Preferences, Actual and Hypothetical: A Study of Crowdworker Incentives
Dec 08, 2020
How should we decide which fairness criteria or definitions to adopt in machine learning systems? To answer this question, we must study the fairness preferences of actual users of machine learning systems. Stringent parity constraints on treatment or impact can come with trade-offs, and may not even be preferred by the social groups in question (Zafar et al., 2017). Thus it might be beneficial to elicit what the group's preferences are, rather than rely on a priori defined mathematical fairness constraints. Simply asking for self-reported rankings of users is challenging because research has shown that there are often gaps between people's stated and actual preferences(Bernheim et al., 2013). This paper outlines a research program and experimental designs for investigating these questions. Participants in the experiments are invited to perform a set of tasks in exchange for a base payment--they are told upfront that they may receive a bonus later on, and the bonus could depend on some combination of output quantity and quality. The same group of workers then votes on a bonus payment structure, to elicit preferences. The voting is hypothetical (not tied to an outcome) for half the group and actual (tied to the actual payment outcome) for the other half, so that we can understand the relation between a group's actual preferences and hypothetical (stated) preferences. Connections and lessons from fairness in machine learning are explored.
Characterising Bias in Compressed Models
Oct 06, 2020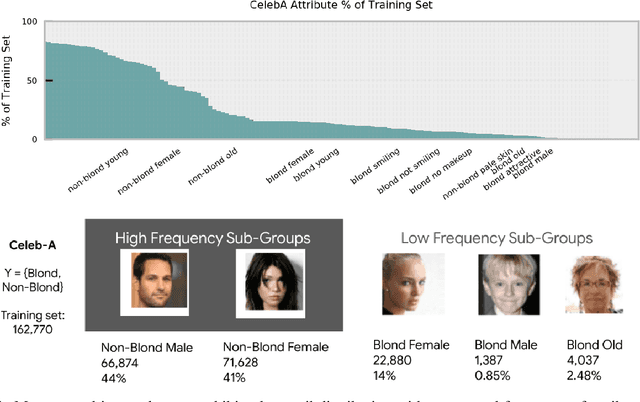
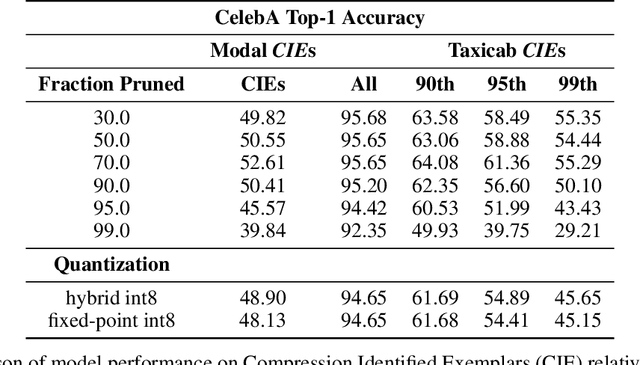
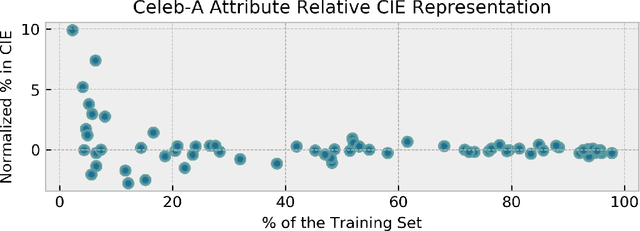
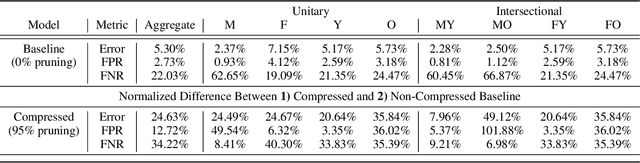
The popularity and widespread use of pruning and quantization is driven by the severe resource constraints of deploying deep neural networks to environments with strict latency, memory and energy requirements. These techniques achieve high levels of compression with negligible impact on top-line metrics (top-1 and top-5 accuracy). However, overall accuracy hides disproportionately high errors on a small subset of examples; we call this subset Compression Identified Exemplars (CIE). We further establish that for CIE examples, compression amplifies existing algorithmic bias. Pruning disproportionately impacts performance on underrepresented features, which often coincides with considerations of fairness. Given that CIE is a relatively small subset but a great contributor of error in the model, we propose its use as a human-in-the-loop auditing tool to surface a tractable subset of the dataset for further inspection or annotation by a domain expert. We provide qualitative and quantitative support that CIE surfaces the most challenging examples in the data distribution for human-in-the-loop auditing.
Diversity and Inclusion Metrics in Subset Selection
Feb 09, 2020


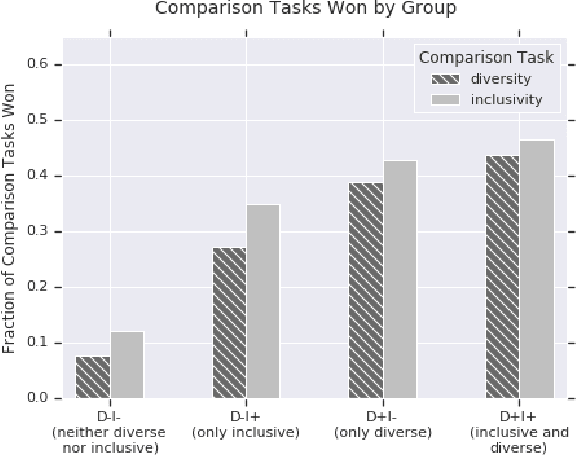
The ethical concept of fairness has recently been applied in machine learning (ML) settings to describe a wide range of constraints and objectives. When considering the relevance of ethical concepts to subset selection problems, the concepts of diversity and inclusion are additionally applicable in order to create outputs that account for social power and access differentials. We introduce metrics based on these concepts, which can be applied together, separately, and in tandem with additional fairness constraints. Results from human subject experiments lend support to the proposed criteria. Social choice methods can additionally be leveraged to aggregate and choose preferable sets, and we detail how these may be applied.