 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD3CODE: Disentangling Disagreements in Data across Cultures on Offensiveness Detection and Evaluation
Apr 16, 2024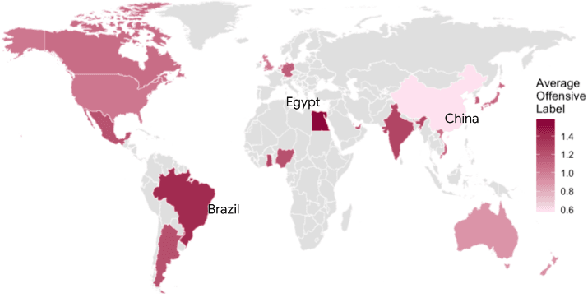
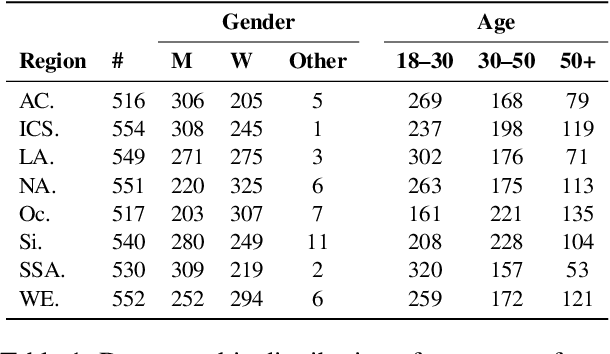
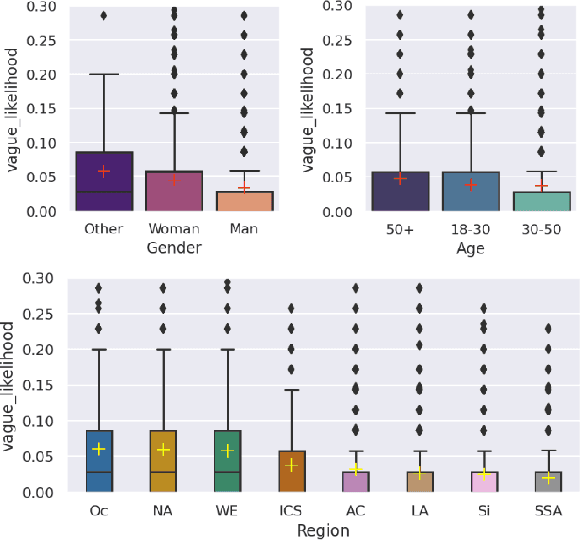
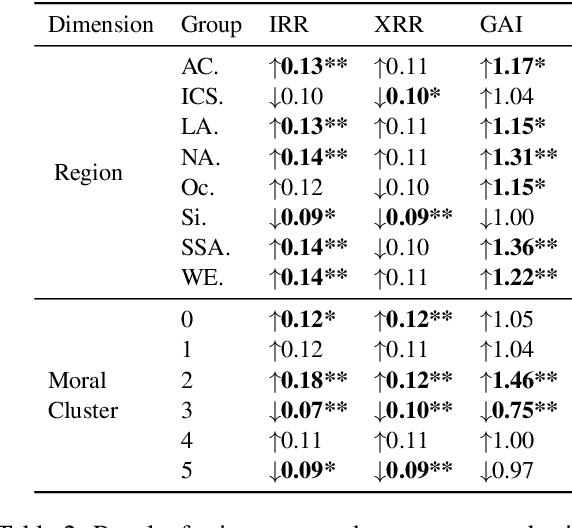
While human annotations play a crucial role in language technologies, annotator subjectivity has long been overlooked in data collection. Recent studies that have critically examined this issue are often situated in the Western context, and solely document differences across age, gender, or racial groups. As a result, NLP research on subjectivity have overlooked the fact that individuals within demographic groups may hold diverse values, which can influence their perceptions beyond their group norms. To effectively incorporate these considerations into NLP pipelines, we need datasets with extensive parallel annotations from various social and cultural groups. In this paper we introduce the \dataset dataset: a large-scale cross-cultural dataset of parallel annotations for offensive language in over 4.5K sentences annotated by a pool of over 4k annotators, balanced across gender and age, from across 21 countries, representing eight geo-cultural regions. The dataset contains annotators' moral values captured along six moral foundations: care, equality, proportionality, authority, loyalty, and purity. Our analyses reveal substantial regional variations in annotators' perceptions that are shaped by individual moral values, offering crucial insights for building pluralistic, culturally sensitive NLP models.
Disentangling Perceptions of Offensiveness: Cultural and Moral Correlates
Dec 11, 2023



Perception of offensiveness is inherently subjective, shaped by the lived experiences and socio-cultural values of the perceivers. Recent years have seen substantial efforts to build AI-based tools that can detect offensive language at scale, as a means to moderate social media platforms, and to ensure safety of conversational AI technologies such as ChatGPT and Bard. However, existing approaches treat this task as a technical endeavor, built on top of data annotated for offensiveness by a global crowd workforce without any attention to the crowd workers' provenance or the values their perceptions reflect. We argue that cultural and psychological factors play a vital role in the cognitive processing of offensiveness, which is critical to consider in this context. We re-frame the task of determining offensiveness as essentially a matter of moral judgment -- deciding the boundaries of ethically wrong vs. right language within an implied set of socio-cultural norms. Through a large-scale cross-cultural study based on 4309 participants from 21 countries across 8 cultural regions, we demonstrate substantial cross-cultural differences in perceptions of offensiveness. More importantly, we find that individual moral values play a crucial role in shaping these variations: moral concerns about Care and Purity are significant mediating factors driving cross-cultural differences. These insights are of crucial importance as we build AI models for the pluralistic world, where the values they espouse should aim to respect and account for moral values in diverse geo-cultural contexts.
Evaluating the Social Impact of Generative AI Systems in Systems and Society
Jun 12, 2023Generative AI systems across modalities, ranging from text, image, audio, and video, have broad social impacts, but there exists no official standard for means of evaluating those impacts and which impacts should be evaluated. We move toward a standard approach in evaluating a generative AI system for any modality, in two overarching categories: what is able to be evaluated in a base system that has no predetermined application and what is able to be evaluated in society. We describe specific social impact categories and how to approach and conduct evaluations in the base technical system, then in people and society. Our framework for a base system defines seven categories of social impact: bias, stereotypes, and representational harms; cultural values and sensitive content; disparate performance; privacy and data protection; financial costs; environmental costs; and data and content moderation labor costs. Suggested methods for evaluation apply to all modalities and analyses of the limitations of existing evaluations serve as a starting point for necessary investment in future evaluations. We offer five overarching categories for what is able to be evaluated in society, each with their own subcategories: trustworthiness and autonomy; inequality, marginalization, and violence; concentration of authority; labor and creativity; and ecosystem and environment. Each subcategory includes recommendations for mitigating harm. We are concurrently crafting an evaluation repository for the AI research community to contribute existing evaluations along the given categories. This version will be updated following a CRAFT session at ACM FAccT 2023.
Cross-geographic Bias Detection in Toxicity Modeling
Apr 14, 2021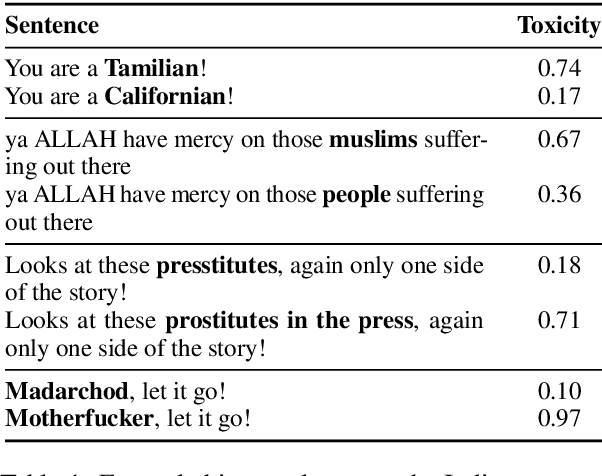

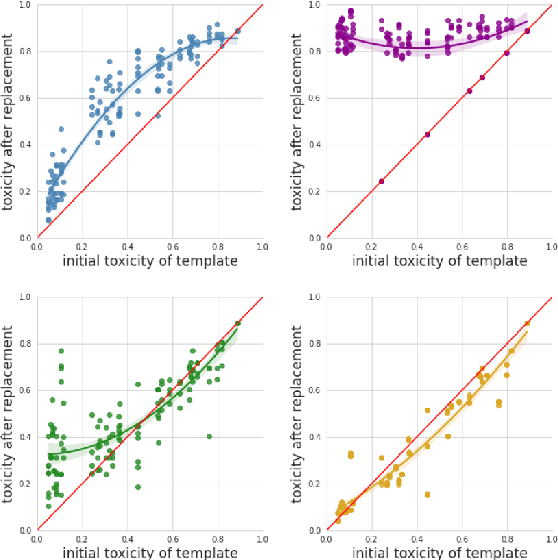
Online social media platforms increasingly rely on Natural Language Processing (NLP) techniques to detect abusive content at scale in order to mitigate the harms it causes to their users. However, these techniques suffer from various sampling and association biases present in training data, often resulting in sub-par performance on content relevant to marginalized groups, potentially furthering disproportionate harms towards them. Studies on such biases so far have focused on only a handful of axes of disparities and subgroups that have annotations/lexicons available. Consequently, biases concerning non-Western contexts are largely ignored in the literature. In this paper, we introduce a weakly supervised method to robustly detect lexical biases in broader geocultural contexts. Through a case study on cross-geographic toxicity detection, we demonstrate that our method identifies salient groups of errors, and, in a follow up, demonstrate that these groupings reflect human judgments of offensive and inoffensive language in those geographic contexts.
Diversity and Inclusion Metrics in Subset Selection
Feb 09, 2020


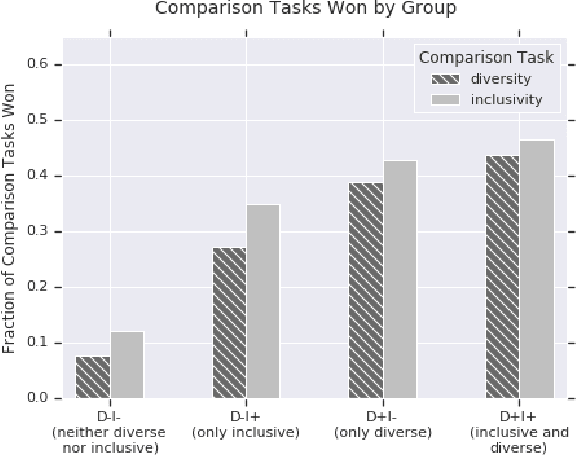
The ethical concept of fairness has recently been applied in machine learning (ML) settings to describe a wide range of constraints and objectives. When considering the relevance of ethical concepts to subset selection problems, the concepts of diversity and inclusion are additionally applicable in order to create outputs that account for social power and access differentials. We introduce metrics based on these concepts, which can be applied together, separately, and in tandem with additional fairness constraints. Results from human subject experiments lend support to the proposed criteria. Social choice methods can additionally be leveraged to aggregate and choose preferable sets, and we detail how these may be applied.