 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework to Quantify Cultural Intelligence of AI
Mar 01, 2026As generative AI technologies are increasingly being launched across the globe, assessing their competence to operate in different cultural contexts is exigently becoming a priority. While recent years have seen numerous and much-needed efforts on cultural benchmarking, these efforts have largely focused on specific aspects of culture and evaluation. While these efforts contribute to our understanding of cultural competence, a unified and systematic evaluation approach is needed for us as a field to comprehensively assess diverse cultural dimensions at scale. Drawing on measurement theory, we present a principled framework to aggregate multifaceted indicators of cultural capabilities into a unified assessment of cultural intelligence. We start by developing a working definition of culture that includes identifying core domains of culture. We then introduce a broad-purpose, systematic, and extensible framework for assessing cultural intelligence of AI systems. Drawing on theoretical framing from psychometric measurement validity theory, we decouple the background concept (i.e., cultural intelligence) from its operationalization via measurement. We conceptualize cultural intelligence as a suite of core capabilities spanning diverse domains, which we then operationalize through a set of indicators designed for reliable measurement. Finally, we identify the considerations, challenges, and research pathways to meaningfully measure these indicators, specifically focusing on data collection, probing strategies, and evaluation metrics.
SAFARI: A Community-Engaged Approach and Dataset of Stereotype Resources in the Sub-Saharan African Context
Feb 25, 2026Stereotype repositories are critical to assess generative AI model safety, but currently lack adequate global coverage. It is imperative to prioritize targeted expansion, strategically addressing existing deficits, over merely increasing data volume. This work introduces a multilingual stereotype resource covering four sub-Saharan African countries that are severely underrepresented in NLP resources: Ghana, Kenya, Nigeria, and South Africa. By utilizing socioculturally-situated, community-engaged methods, including telephonic surveys moderated in native languages, we establish a reproducible methodology that is sensitive to the region's complex linguistic diversity and traditional orality. By deliberately balancing the sample across diverse ethnic and demographic backgrounds, we ensure broad coverage, resulting in a dataset of 3,534 stereotypes in English and 3,206 stereotypes across 15 native languages.
Cultural Compass: A Framework for Organizing Societal Norms to Detect Violations in Human-AI Conversations
Jan 12, 2026Generative AI models ought to be useful and safe across cross-cultural contexts. One critical step toward this goal is understanding how AI models adhere to sociocultural norms. While this challenge has gained attention in NLP, existing work lacks both nuance and coverage in understanding and evaluating models' norm adherence. We address these gaps by introducing a taxonomy of norms that clarifies their contexts (e.g., distinguishing between human-human norms that models should recognize and human-AI interactional norms that apply to the human-AI interaction itself), specifications (e.g., relevant domains), and mechanisms (e.g., modes of enforcement). We demonstrate how our taxonomy can be operationalized to automatically evaluate models' norm adherence in naturalistic, open-ended settings. Our exploratory analyses suggest that state-of-the-art models frequently violate norms, though violation rates vary by model, interactional context, and country. We further show that violation rates also vary by prompt intent and situational framing. Our taxonomy and demonstrative evaluation pipeline enable nuanced, context-sensitive evaluation of cultural norm adherence in realistic settings.
Humanlike AI Design Increases Anthropomorphism but Yields Divergent Outcomes on Engagement and Trust Globally
Dec 19, 2025Over a billion users across the globe interact with AI systems engineered with increasing sophistication to mimic human traits. This shift has triggered urgent debate regarding Anthropomorphism, the attribution of human characteristics to synthetic agents, and its potential to induce misplaced trust or emotional dependency. However, the causal link between more humanlike AI design and subsequent effects on engagement and trust has not been tested in realistic human-AI interactions with a global user pool. Prevailing safety frameworks continue to rely on theoretical assumptions derived from Western populations, overlooking the global diversity of AI users. Here, we address these gaps through two large-scale cross-national experiments (N=3,500) across 10 diverse nations, involving real-time and open-ended interactions with an AI system. We find that when evaluating an AI's human-likeness, users focus less on the kind of theoretical aspects often cited in policy (e.g., sentience or consciousness), but rather applied, interactional cues like conversation flow or understanding the user's perspective. We also experimentally demonstrate that humanlike design levers can causally increase anthropomorphism among users; however, we do not find that humanlike design universally increases behavioral measures for user engagement and trust, as previous theoretical work suggests. Instead, part of the connection between human-likeness and behavioral outcomes is fractured by culture: specific design choices that foster self-reported trust in AI-systems in some populations (e.g., Brazil) may trigger the opposite result in others (e.g., Japan). Our findings challenge prevailing narratives of inherent risk in humanlike AI design. Instead, we identify a nuanced, culturally mediated landscape of human-AI interaction, which demands that we move beyond a one-size-fits-all approach in AI governance.
Towards Geo-Culturally Grounded LLM Generations
Feb 20, 2025Generative large language models (LLMs) have been demonstrated to have gaps in diverse, cultural knowledge across the globe. We investigate the effect of retrieval augmented generation and search-grounding techniques on the ability of LLMs to display familiarity with a diverse range of national cultures. Specifically, we compare the performance of standard LLMs, LLMs augmented with retrievals from a bespoke knowledge base (i.e., KB grounding), and LLMs augmented with retrievals from a web search (i.e., search grounding) on a series of cultural familiarity benchmarks. We find that search grounding significantly improves the LLM performance on multiple-choice benchmarks that test propositional knowledge (e.g., the norms, artifacts, and institutions of national cultures), while KB grounding's effectiveness is limited by inadequate knowledge base coverage and a suboptimal retriever. However, search grounding also increases the risk of stereotypical judgments by language models, while failing to improve evaluators' judgments of cultural familiarity in a human evaluation with adequate statistical power. These results highlight the distinction between propositional knowledge about a culture and open-ended cultural fluency when it comes to evaluating the cultural familiarity of generative LLMs.
Risks of Cultural Erasure in Large Language Models
Jan 02, 2025



Large language models are increasingly being integrated into applications that shape the production and discovery of societal knowledge such as search, online education, and travel planning. As a result, language models will shape how people learn about, perceive and interact with global cultures making it important to consider whose knowledge systems and perspectives are represented in models. Recognizing this importance, increasingly work in Machine Learning and NLP has focused on evaluating gaps in global cultural representational distribution within outputs. However, more work is needed on developing benchmarks for cross-cultural impacts of language models that stem from a nuanced sociologically-aware conceptualization of cultural impact or harm. We join this line of work arguing for the need of metricizable evaluations of language technologies that interrogate and account for historical power inequities and differential impacts of representation on global cultures, particularly for cultures already under-represented in the digital corpora. We look at two concepts of erasure: omission: where cultures are not represented at all and simplification i.e. when cultural complexity is erased by presenting one-dimensional views of a rich culture. The former focuses on whether something is represented, and the latter on how it is represented. We focus our analysis on two task contexts with the potential to influence global cultural production. First, we probe representations that a language model produces about different places around the world when asked to describe these contexts. Second, we analyze the cultures represented in the travel recommendations produced by a set of language model applications. Our study shows ways in which the NLP community and application developers can begin to operationalize complex socio-cultural considerations into standard evaluations and benchmarks.
Insights on Disagreement Patterns in Multimodal Safety Perception across Diverse Rater Groups
Oct 22, 2024



AI systems crucially rely on human ratings, but these ratings are often aggregated, obscuring the inherent diversity of perspectives in real-world phenomenon. This is particularly concerning when evaluating the safety of generative AI, where perceptions and associated harms can vary significantly across socio-cultural contexts. While recent research has studied the impact of demographic differences on annotating text, there is limited understanding of how these subjective variations affect multimodal safety in generative AI. To address this, we conduct a large-scale study employing highly-parallel safety ratings of about 1000 text-to-image (T2I) generations from a demographically diverse rater pool of 630 raters balanced across 30 intersectional groups across age, gender, and ethnicity. Our study shows that (1) there are significant differences across demographic groups (including intersectional groups) on how severe they assess the harm to be, and that these differences vary across different types of safety violations, (2) the diverse rater pool captures annotation patterns that are substantially different from expert raters trained on specific set of safety policies, and (3) the differences we observe in T2I safety are distinct from previously documented group level differences in text-based safety tasks. To further understand these varying perspectives, we conduct a qualitative analysis of the open-ended explanations provided by raters. This analysis reveals core differences into the reasons why different groups perceive harms in T2I generations. Our findings underscore the critical need for incorporating diverse perspectives into safety evaluation of generative AI ensuring these systems are truly inclusive and reflect the values of all users.
Beyond Aesthetics: Cultural Competence in Text-to-Image Models
Jul 11, 2024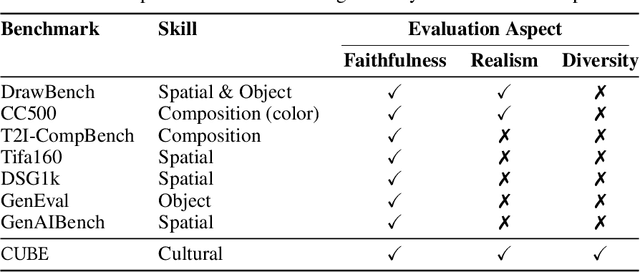
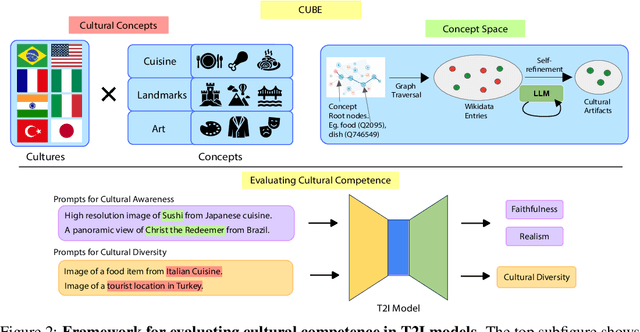


Text-to-Image (T2I) models are being increasingly adopted in diverse global communities where they create visual representations of their unique cultures. Current T2I benchmarks primarily focus on faithfulness, aesthetics, and realism of generated images, overlooking the critical dimension of cultural competence. In this work, we introduce a framework to evaluate cultural competence of T2I models along two crucial dimensions: cultural awareness and cultural diversity, and present a scalable approach using a combination of structured knowledge bases and large language models to build a large dataset of cultural artifacts to enable this evaluation. In particular, we apply this approach to build CUBE (CUltural BEnchmark for Text-to-Image models), a first-of-its-kind benchmark to evaluate cultural competence of T2I models. CUBE covers cultural artifacts associated with 8 countries across different geo-cultural regions and along 3 concepts: cuisine, landmarks, and art. CUBE consists of 1) CUBE-1K, a set of high-quality prompts that enable the evaluation of cultural awareness, and 2) CUBE-CSpace, a larger dataset of cultural artifacts that serves as grounding to evaluate cultural diversity. We also introduce cultural diversity as a novel T2I evaluation component, leveraging quality-weighted Vendi score. Our evaluations reveal significant gaps in the cultural awareness of existing models across countries and provide valuable insights into the cultural diversity of T2I outputs for under-specified prompts. Our methodology is extendable to other cultural regions and concepts, and can facilitate the development of T2I models that better cater to the global population.
D3CODE: Disentangling Disagreements in Data across Cultures on Offensiveness Detection and Evaluation
Apr 16, 2024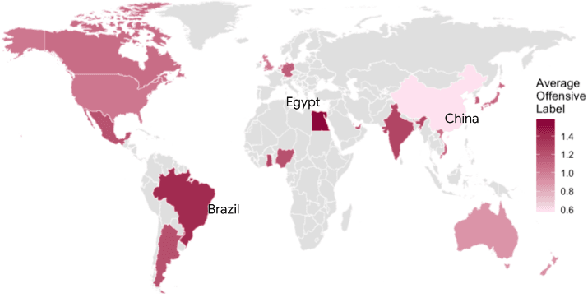
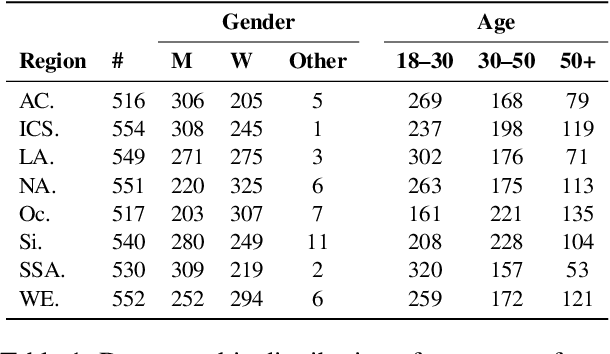
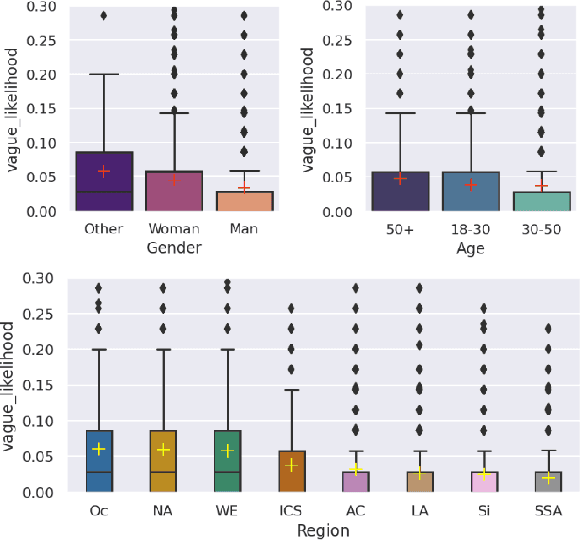
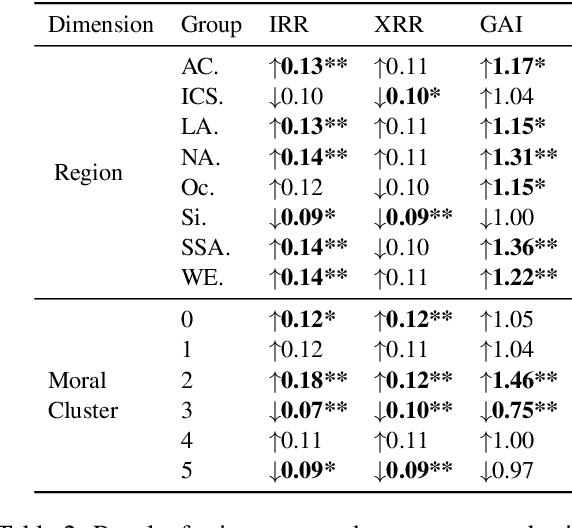
While human annotations play a crucial role in language technologies, annotator subjectivity has long been overlooked in data collection. Recent studies that have critically examined this issue are often situated in the Western context, and solely document differences across age, gender, or racial groups. As a result, NLP research on subjectivity have overlooked the fact that individuals within demographic groups may hold diverse values, which can influence their perceptions beyond their group norms. To effectively incorporate these considerations into NLP pipelines, we need datasets with extensive parallel annotations from various social and cultural groups. In this paper we introduce the \dataset dataset: a large-scale cross-cultural dataset of parallel annotations for offensive language in over 4.5K sentences annotated by a pool of over 4k annotators, balanced across gender and age, from across 21 countries, representing eight geo-cultural regions. The dataset contains annotators' moral values captured along six moral foundations: care, equality, proportionality, authority, loyalty, and purity. Our analyses reveal substantial regional variations in annotators' perceptions that are shaped by individual moral values, offering crucial insights for building pluralistic, culturally sensitive NLP models.
GeniL: A Multilingual Dataset on Generalizing Language
Apr 08, 2024



LLMs are increasingly transforming our digital ecosystem, but they often inherit societal biases learned from their training data, for instance stereotypes associating certain attributes with specific identity groups. While whether and how these biases are mitigated may depend on the specific use cases, being able to effectively detect instances of stereotype perpetuation is a crucial first step. Current methods to assess presence of stereotypes in generated language rely on simple template or co-occurrence based measures, without accounting for the variety of sentential contexts they manifest in. We argue that understanding the sentential context is crucial for detecting instances of generalization. We distinguish two types of generalizations: (1) language that merely mentions the presence of a generalization ("people think the French are very rude"), and (2) language that reinforces such a generalization ("as French they must be rude"), from non-generalizing context ("My French friends think I am rude"). For meaningful stereotype evaluations, we need to reliably distinguish such instances of generalizations. We introduce the new task of detecting generalization in language, and build GeniL, a multilingual dataset of over 50K sentences from 9 languages (English, Arabic, Bengali, Spanish, French, Hindi, Indonesian, Malay, and Portuguese) annotated for instances of generalizations. We demonstrate that the likelihood of a co-occurrence being an instance of generalization is usually low, and varies across different languages, identity groups, and attributes. We build classifiers to detect generalization in language with an overall PR-AUC of 58.7, with varying degrees of performance across languages. Our research provides data and tools to enable a nuanced understanding of stereotype perpetuation, a crucial step towards more inclusive and responsible language technologies.