 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Reasoning Arena
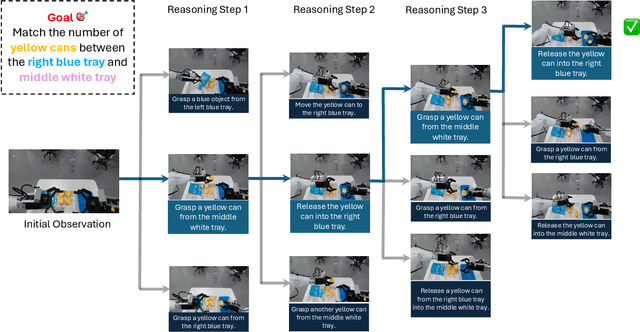
Mar 26, 2026World models (WMs) are intended to serve as internal simulators of the real world that enable agents to understand, anticipate, and act upon complex environments. Existing WM benchmarks remain narrowly focused on next-state prediction and visual fidelity, overlooking the richer simulation capabilities required for intelligent behavior. To address this gap, we introduce WR-Arena, a comprehensive benchmark for evaluating WMs along three fundamental dimensions of next world simulation: (i) Action Simulation Fidelity, the ability to interpret and follow semantically meaningful, multi-step instructions and generate diverse counterfactual rollouts; (ii) Long-horizon Forecast, the ability to sustain accurate, coherent, and physically plausible simulations across extended interactions; and (iii) Simulative Reasoning and Planning, the ability to support goal-directed reasoning by simulating, comparing, and selecting among alternative futures in both structured and open-ended environments. We build a task taxonomy and curate diverse datasets designed to probe these capabilities, moving beyond single-turn and perceptual evaluations. Through extensive experiments with state-of-the-art WMs, our results expose a substantial gap between current models and human-level hypothetical reasoning, and establish WR-Arena as both a diagnostic tool and a guideline for advancing next-generation world models capable of robust understanding, forecasting, and purposeful action. The code is available at https://github.com/MBZUAI-IFM/WR-Arena.
PAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Nov 15, 2025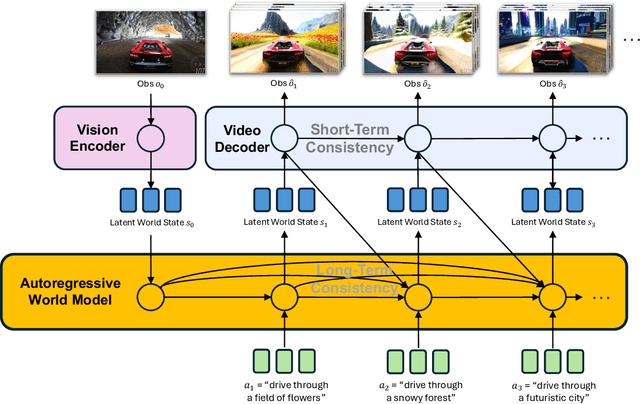
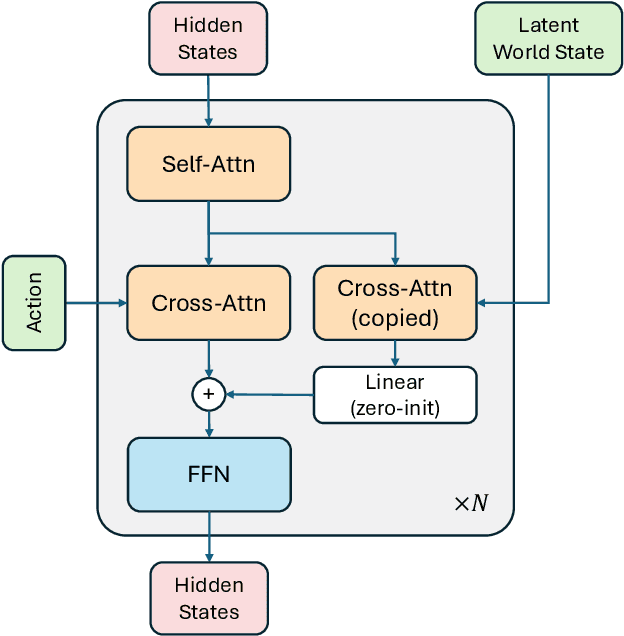
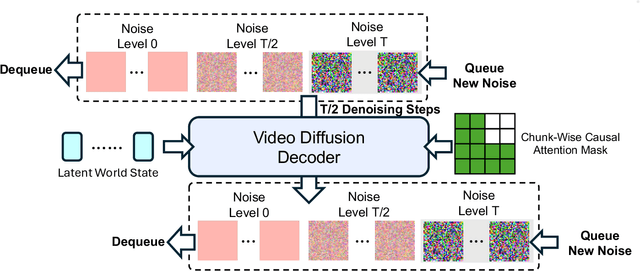
A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a large language model (LLM), which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
Looks can be Deceptive: Distinguishing Repetition Disfluency from Reduplication
Jul 11, 2024
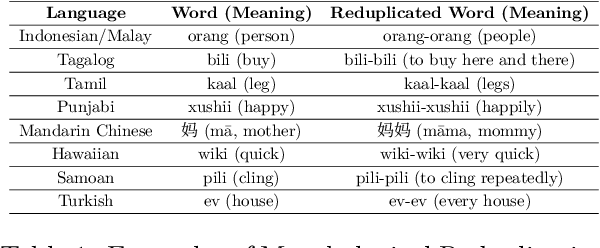
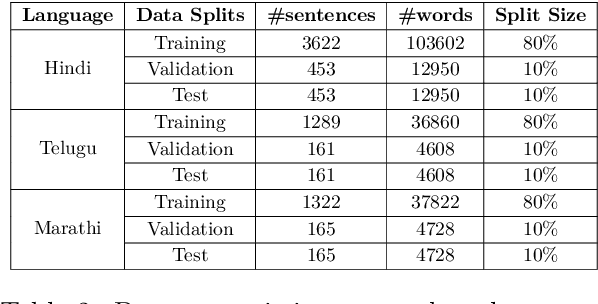
Reduplication and repetition, though similar in form, serve distinct linguistic purposes. Reduplication is a deliberate morphological process used to express grammatical, semantic, or pragmatic nuances, while repetition is often unintentional and indicative of disfluency. This paper presents the first large-scale study of reduplication and repetition in speech using computational linguistics. We introduce IndicRedRep, a new publicly available dataset containing Hindi, Telugu, and Marathi text annotated with reduplication and repetition at the word level. We evaluate transformer-based models for multi-class reduplication and repetition token classification, utilizing the Reparandum-Interregnum-Repair structure to distinguish between the two phenomena. Our models achieve macro F1 scores of up to 85.62% in Hindi, 83.95% in Telugu, and 84.82% in Marathi for reduplication-repetition classification.
Beyond Aesthetics: Cultural Competence in Text-to-Image Models
Jul 11, 2024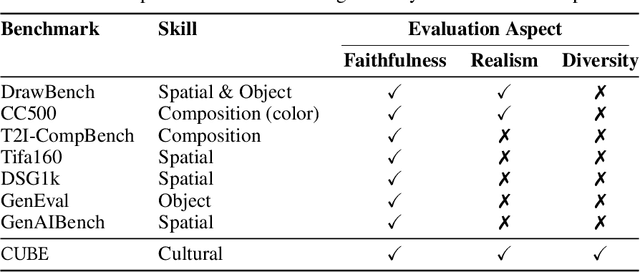
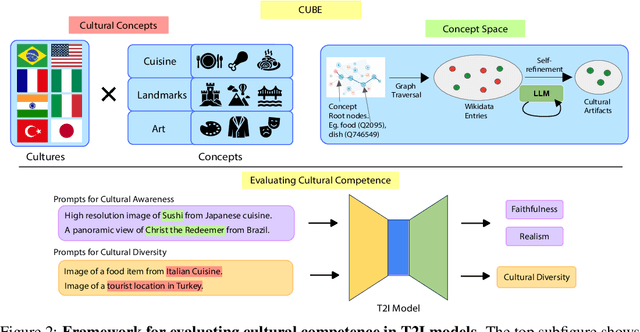


Text-to-Image (T2I) models are being increasingly adopted in diverse global communities where they create visual representations of their unique cultures. Current T2I benchmarks primarily focus on faithfulness, aesthetics, and realism of generated images, overlooking the critical dimension of cultural competence. In this work, we introduce a framework to evaluate cultural competence of T2I models along two crucial dimensions: cultural awareness and cultural diversity, and present a scalable approach using a combination of structured knowledge bases and large language models to build a large dataset of cultural artifacts to enable this evaluation. In particular, we apply this approach to build CUBE (CUltural BEnchmark for Text-to-Image models), a first-of-its-kind benchmark to evaluate cultural competence of T2I models. CUBE covers cultural artifacts associated with 8 countries across different geo-cultural regions and along 3 concepts: cuisine, landmarks, and art. CUBE consists of 1) CUBE-1K, a set of high-quality prompts that enable the evaluation of cultural awareness, and 2) CUBE-CSpace, a larger dataset of cultural artifacts that serves as grounding to evaluate cultural diversity. We also introduce cultural diversity as a novel T2I evaluation component, leveraging quality-weighted Vendi score. Our evaluations reveal significant gaps in the cultural awareness of existing models across countries and provide valuable insights into the cultural diversity of T2I outputs for under-specified prompts. Our methodology is extendable to other cultural regions and concepts, and can facilitate the development of T2I models that better cater to the global population.
IndiBias: A Benchmark Dataset to Measure Social Biases in Language Models for Indian Context
Apr 03, 2024
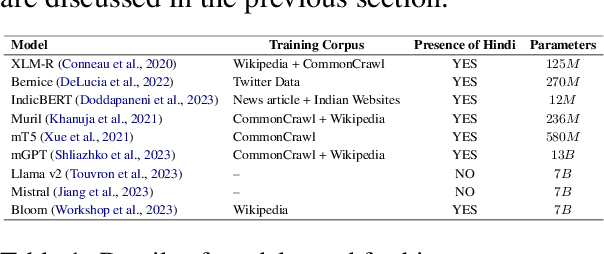


The pervasive influence of social biases in language data has sparked the need for benchmark datasets that capture and evaluate these biases in Large Language Models (LLMs). Existing efforts predominantly focus on English language and the Western context, leaving a void for a reliable dataset that encapsulates India's unique socio-cultural nuances. To bridge this gap, we introduce IndiBias, a comprehensive benchmarking dataset designed specifically for evaluating social biases in the Indian context. We filter and translate the existing CrowS-Pairs dataset to create a benchmark dataset suited to the Indian context in Hindi language. Additionally, we leverage LLMs including ChatGPT and InstructGPT to augment our dataset with diverse societal biases and stereotypes prevalent in India. The included bias dimensions encompass gender, religion, caste, age, region, physical appearance, and occupation. We also build a resource to address intersectional biases along three intersectional dimensions. Our dataset contains 800 sentence pairs and 300 tuples for bias measurement across different demographics. The dataset is available in English and Hindi, providing a size comparable to existing benchmark datasets. Furthermore, using IndiBias we compare ten different language models on multiple bias measurement metrics. We observed that the language models exhibit more bias across a majority of the intersectional groups.
End to End Bangla Speech Synthesis
Aug 01, 2021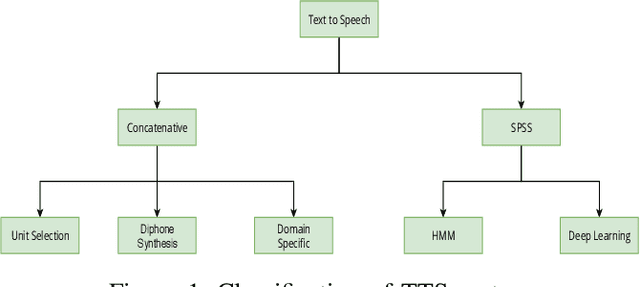
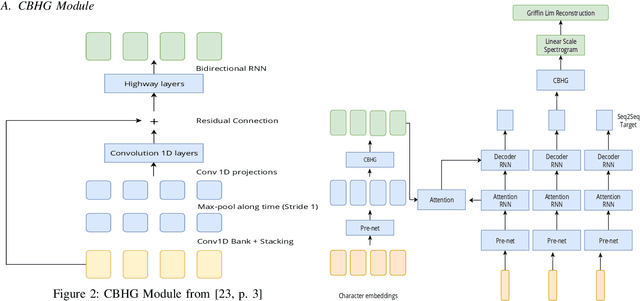
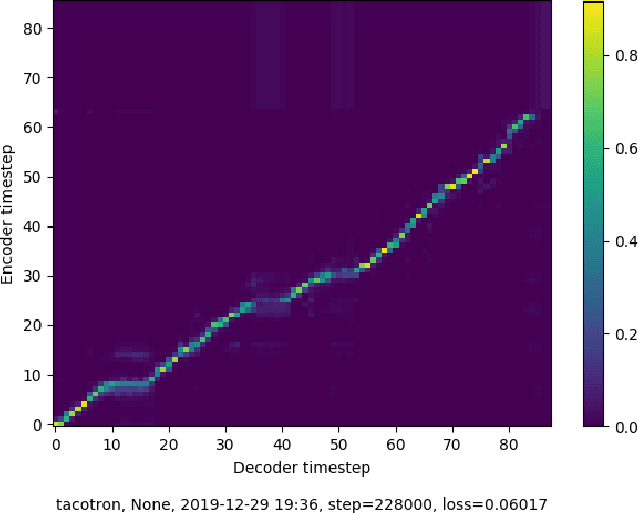
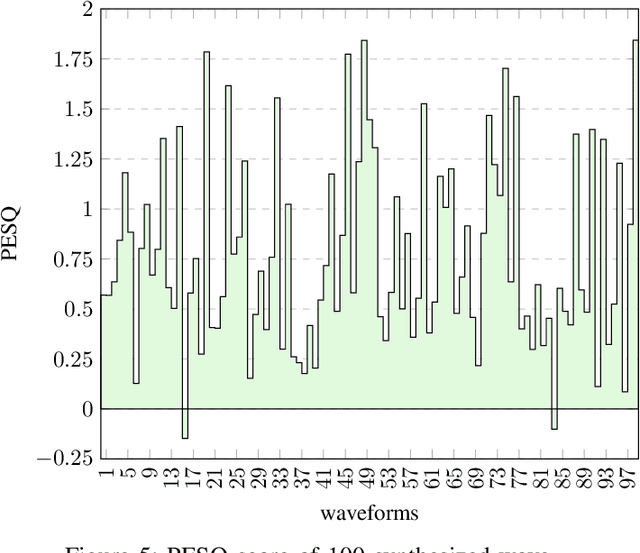
Text-to-Speech (TTS) system is a system where speech is synthesized from a given text following any particular approach. Concatenative synthesis, Hidden Markov Model (HMM) based synthesis, Deep Learning (DL) based synthesis with multiple building blocks, etc. are the main approaches for implementing a TTS system. Here, we are presenting our deep learning-based end-to-end Bangla speech synthesis system. It has been implemented with minimal human annotation using only 3 major components (Encoder, Decoder, Post-processing net including waveform synthesis). It does not require any frontend preprocessor and Grapheme-to-Phoneme (G2P) converter. Our model has been trained with phonetically balanced 20 hours of single speaker speech data. It has obtained a 3.79 Mean Opinion Score (MOS) on a scale of 5.0 as subjective evaluation and a 0.77 Perceptual Evaluation of Speech Quality(PESQ) score on a scale of [-0.5, 4.5] as objective evaluation. It is outperforming all existing non-commercial state-of-the-art Bangla TTS systems based on naturalness.