 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBharatBBQ: A Multilingual Bias Benchmark for Question Answering in the Indian Context
Aug 09, 2025



Evaluating social biases in language models (LMs) is crucial for ensuring fairness and minimizing the reinforcement of harmful stereotypes in AI systems. Existing benchmarks, such as the Bias Benchmark for Question Answering (BBQ), primarily focus on Western contexts, limiting their applicability to the Indian context. To address this gap, we introduce BharatBBQ, a culturally adapted benchmark designed to assess biases in Hindi, English, Marathi, Bengali, Tamil, Telugu, Odia, and Assamese. BharatBBQ covers 13 social categories, including 3 intersectional groups, reflecting prevalent biases in the Indian sociocultural landscape. Our dataset contains 49,108 examples in one language that are expanded using translation and verification to 392,864 examples in eight different languages. We evaluate five multilingual LM families across zero and few-shot settings, analyzing their bias and stereotypical bias scores. Our findings highlight persistent biases across languages and social categories and often amplified biases in Indian languages compared to English, demonstrating the necessity of linguistically and culturally grounded benchmarks for bias evaluation.
Mathematics Isn't Culture-Free: Probing Cultural Gaps via Entity and Scenario Perturbations
Jul 01, 2025



Although mathematics is often considered culturally neutral, the way mathematical problems are presented can carry implicit cultural context. Existing benchmarks like GSM8K are predominantly rooted in Western norms, including names, currencies, and everyday scenarios. In this work, we create culturally adapted variants of the GSM8K test set for five regions Africa, India, China, Korea, and Japan using prompt-based transformations followed by manual verification. We evaluate six large language models (LLMs), ranging from 8B to 72B parameters, across five prompting strategies to assess their robustness to cultural variation in math problem presentation. Our findings reveal a consistent performance gap: models perform best on the original US-centric dataset and comparatively worse on culturally adapted versions. However, models with reasoning capabilities are more resilient to these shifts, suggesting that deeper reasoning helps bridge cultural presentation gaps in mathematical tasks
IndiBias: A Benchmark Dataset to Measure Social Biases in Language Models for Indian Context
Apr 03, 2024
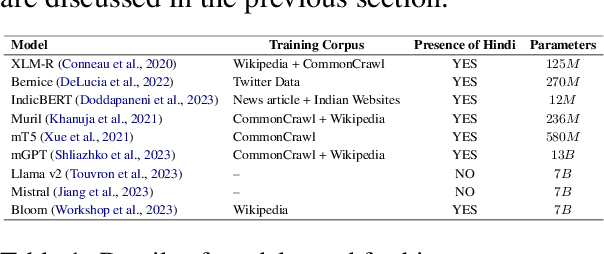


The pervasive influence of social biases in language data has sparked the need for benchmark datasets that capture and evaluate these biases in Large Language Models (LLMs). Existing efforts predominantly focus on English language and the Western context, leaving a void for a reliable dataset that encapsulates India's unique socio-cultural nuances. To bridge this gap, we introduce IndiBias, a comprehensive benchmarking dataset designed specifically for evaluating social biases in the Indian context. We filter and translate the existing CrowS-Pairs dataset to create a benchmark dataset suited to the Indian context in Hindi language. Additionally, we leverage LLMs including ChatGPT and InstructGPT to augment our dataset with diverse societal biases and stereotypes prevalent in India. The included bias dimensions encompass gender, religion, caste, age, region, physical appearance, and occupation. We also build a resource to address intersectional biases along three intersectional dimensions. Our dataset contains 800 sentence pairs and 300 tuples for bias measurement across different demographics. The dataset is available in English and Hindi, providing a size comparable to existing benchmark datasets. Furthermore, using IndiBias we compare ten different language models on multiple bias measurement metrics. We observed that the language models exhibit more bias across a majority of the intersectional groups.
Few-Shot Domain Adaptation for Low Light RAW Image Enhancement
Mar 27, 2023



Enhancing practical low light raw images is a difficult task due to severe noise and color distortions from short exposure time and limited illumination. Despite the success of existing Convolutional Neural Network (CNN) based methods, their performance is not adaptable to different camera domains. In addition, such methods also require large datasets with short-exposure and corresponding long-exposure ground truth raw images for each camera domain, which is tedious to compile. To address this issue, we present a novel few-shot domain adaptation method to utilize the existing source camera labeled data with few labeled samples from the target camera to improve the target domain's enhancement quality in extreme low-light imaging. Our experiments show that only ten or fewer labeled samples from the target camera domain are sufficient to achieve similar or better enhancement performance than training a model with a large labeled target camera dataset. To support research in this direction, we also present a new low-light raw image dataset captured with a Nikon camera, comprising short-exposure and their corresponding long-exposure ground truth images.
* BMVC 2021 Best Student Paper Award (Runner-Up). Project Page: https://val.cds.iisc.ac.in/HDR/BMVC21/index.html