 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Domain Adaptation for Low Light RAW Image Enhancement
Mar 27, 2023



Enhancing practical low light raw images is a difficult task due to severe noise and color distortions from short exposure time and limited illumination. Despite the success of existing Convolutional Neural Network (CNN) based methods, their performance is not adaptable to different camera domains. In addition, such methods also require large datasets with short-exposure and corresponding long-exposure ground truth raw images for each camera domain, which is tedious to compile. To address this issue, we present a novel few-shot domain adaptation method to utilize the existing source camera labeled data with few labeled samples from the target camera to improve the target domain's enhancement quality in extreme low-light imaging. Our experiments show that only ten or fewer labeled samples from the target camera domain are sufficient to achieve similar or better enhancement performance than training a model with a large labeled target camera dataset. To support research in this direction, we also present a new low-light raw image dataset captured with a Nikon camera, comprising short-exposure and their corresponding long-exposure ground truth images.
* BMVC 2021 Best Student Paper Award (Runner-Up). Project Page: https://val.cds.iisc.ac.in/HDR/BMVC21/index.html
TEGLO: High Fidelity Canonical Texture Mapping from Single-View Images
Mar 24, 2023
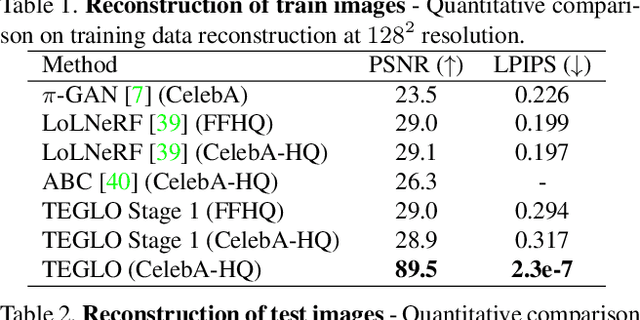
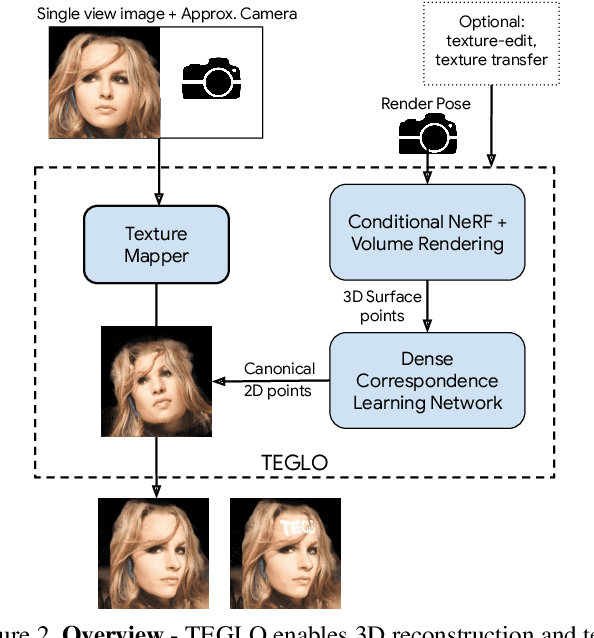
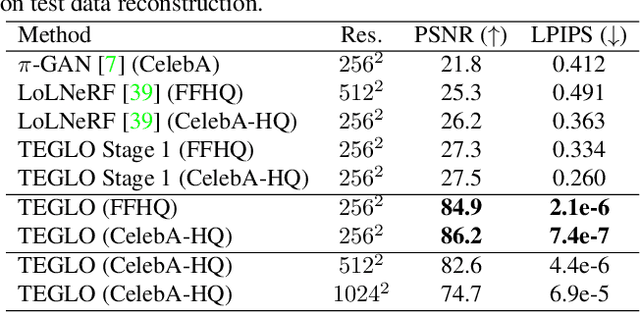
Recent work in Neural Fields (NFs) learn 3D representations from class-specific single view image collections. However, they are unable to reconstruct the input data preserving high-frequency details. Further, these methods do not disentangle appearance from geometry and hence are not suitable for tasks such as texture transfer and editing. In this work, we propose TEGLO (Textured EG3D-GLO) for learning 3D representations from single view in-the-wild image collections for a given class of objects. We accomplish this by training a conditional Neural Radiance Field (NeRF) without any explicit 3D supervision. We equip our method with editing capabilities by creating a dense correspondence mapping to a 2D canonical space. We demonstrate that such mapping enables texture transfer and texture editing without requiring meshes with shared topology. Our key insight is that by mapping the input image pixels onto the texture space we can achieve near perfect reconstruction (>= 74 dB PSNR at 1024^2 resolution). Our formulation allows for high quality 3D consistent novel view synthesis with high-frequency details at megapixel image resolution.
Estimating Leaf Water Content using Remotely Sensed Hyperspectral Data
Sep 06, 2021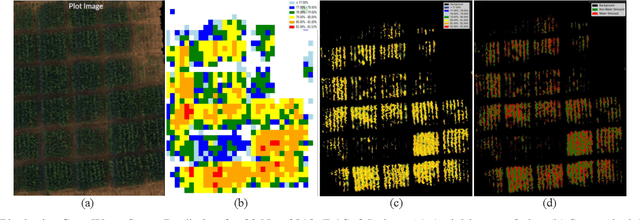

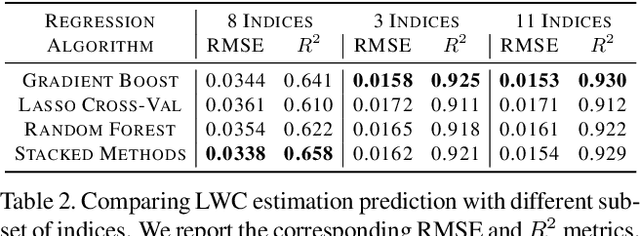
Plant water stress may occur due to the limited availability of water to the roots/soil or due to increased transpiration. These factors adversely affect plant physiology and photosynthetic ability to the extent that it has been shown to have inhibitory effects in both growth and yield [18]. Early identification of plant water stress status enables suitable corrective measures to be applied to obtain the expected crop yield. Further, improving crop yield through precision agriculture methods is a key component of climate policy and the UN sustainable development goals [1]. Leaf water content (LWC) is a measure that can be used to estimate water content and identify stressed plants. LWC during the early crop growth stages is an important indicator of plant productivity and yield. The effect of water stress can be instantaneous [15], affecting gaseous exchange or long-term, significantly reducing [9, 18, 22]. It is thus necessary to identify potential plant water stress during the early stages of growth [15] to introduce corrective irrigation and alleviate stress. LWC is also useful for identifying plant genotypes that are tolerant to water stress and salinity by measuring the stability of LWC even under artificially induced water stress [18, 25]. Such experiments generally employ destructive procedures to obtain the LWC, which is time-consuming and labor intensive. Accordingly, this research has developed a non-destructive method to estimate LWC from UAV-based hyperspectral data.
Multilingual Medical Question Answering and Information Retrieval for Rural Health Intelligence Access
Jun 02, 2021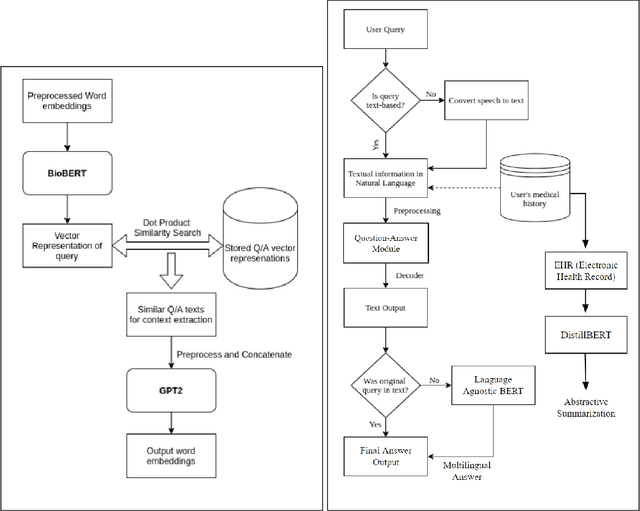

In rural regions of several developing countries, access to quality healthcare, medical infrastructure, and professional diagnosis is largely unavailable. Many of these regions are gradually gaining access to internet infrastructure, although not with a strong enough connection to allow for sustained communication with a medical practitioner. Several deaths resulting from this lack of medical access, absence of patient's previous health records, and the unavailability of information in indigenous languages can be easily prevented. In this paper, we describe an approach leveraging the phenomenal progress in Machine Learning and NLP (Natural Language Processing) techniques to design a model that is low-resource, multilingual, and a preliminary first-point-of-contact medical assistant. Our contribution includes defining the NLP pipeline required for named-entity-recognition, language-agnostic sentence embedding, natural language translation, information retrieval, question answering, and generative pre-training for final query processing. We obtain promising results for this pipeline and preliminary results for EHR (Electronic Health Record) analysis with text summarization for medical practitioners to peruse for their diagnosis. Through this NLP pipeline, we aim to provide preliminary medical information to the user and do not claim to supplant diagnosis from qualified medical practitioners. Using the input from subject matter experts, we have compiled a large corpus to pre-train and fine-tune our BioBERT based NLP model for the specific tasks. We expect recent advances in NLP architectures, several of which are efficient and privacy-preserving models, to further the impact of our solution and improve on individual task performance.