 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Layerwise Activation Norm Improves Generalization in Federated Learning
Dec 09, 2025Federated Learning (FL) is an emerging machine learning framework that enables multiple clients (coordinated by a server) to collaboratively train a global model by aggregating the locally trained models without sharing any client's training data. It has been observed in recent works that learning in a federated manner may lead the aggregated global model to converge to a 'sharp minimum' thereby adversely affecting the generalizability of this FL-trained model. Therefore, in this work, we aim to improve the generalization performance of models trained in a federated setup by introducing a 'flatness' constrained FL optimization problem. This flatness constraint is imposed on the top eigenvalue of the Hessian computed from the training loss. As each client trains a model on its local data, we further re-formulate this complex problem utilizing the client loss functions and propose a new computationally efficient regularization technique, dubbed 'MAN,' which Minimizes Activation's Norm of each layer on client-side models. We also theoretically show that minimizing the activation norm reduces the top eigenvalue of the layer-wise Hessian of the client's loss, which in turn decreases the overall Hessian's top eigenvalue, ensuring convergence to a flat minimum. We apply our proposed flatness-constrained optimization to the existing FL techniques and obtain significant improvements, thereby establishing new state-of-the-art.
Harnessing Diffusion-Generated Synthetic Images for Fair Image Classification
Nov 11, 2025Image classification systems often inherit biases from uneven group representation in training data. For example, in face datasets for hair color classification, blond hair may be disproportionately associated with females, reinforcing stereotypes. A recent approach leverages the Stable Diffusion model to generate balanced training data, but these models often struggle to preserve the original data distribution. In this work, we explore multiple diffusion-finetuning techniques, e.g., LoRA and DreamBooth, to generate images that more accurately represent each training group by learning directly from their samples. Additionally, in order to prevent a single DreamBooth model from being overwhelmed by excessive intra-group variations, we explore a technique of clustering images within each group and train a DreamBooth model per cluster. These models are then used to generate group-balanced data for pretraining, followed by fine-tuning on real data. Experiments on multiple benchmarks demonstrate that the studied finetuning approaches outperform vanilla Stable Diffusion on average and achieve results comparable to SOTA debiasing techniques like Group-DRO, while surpassing them as the dataset bias severity increases.
MonoPlace3D: Learning 3D-Aware Object Placement for 3D Monocular Detection
Apr 10, 2025Current monocular 3D detectors are held back by the limited diversity and scale of real-world datasets. While data augmentation certainly helps, it's particularly difficult to generate realistic scene-aware augmented data for outdoor settings. Most current approaches to synthetic data generation focus on realistic object appearance through improved rendering techniques. However, we show that where and how objects are positioned is just as crucial for training effective 3D monocular detectors. The key obstacle lies in automatically determining realistic object placement parameters - including position, dimensions, and directional alignment when introducing synthetic objects into actual scenes. To address this, we introduce MonoPlace3D, a novel system that considers the 3D scene content to create realistic augmentations. Specifically, given a background scene, MonoPlace3D learns a distribution over plausible 3D bounding boxes. Subsequently, we render realistic objects and place them according to the locations sampled from the learned distribution. Our comprehensive evaluation on two standard datasets KITTI and NuScenes, demonstrates that MonoPlace3D significantly improves the accuracy of multiple existing monocular 3D detectors while being highly data efficient.
Compass Control: Multi Object Orientation Control for Text-to-Image Generation
Apr 10, 2025Existing approaches for controlling text-to-image diffusion models, while powerful, do not allow for explicit 3D object-centric control, such as precise control of object orientation. In this work, we address the problem of multi-object orientation control in text-to-image diffusion models. This enables the generation of diverse multi-object scenes with precise orientation control for each object. The key idea is to condition the diffusion model with a set of orientation-aware \textbf{compass} tokens, one for each object, along with text tokens. A light-weight encoder network predicts these compass tokens taking object orientation as the input. The model is trained on a synthetic dataset of procedurally generated scenes, each containing one or two 3D assets on a plain background. However, direct training this framework results in poor orientation control as well as leads to entanglement among objects. To mitigate this, we intervene in the generation process and constrain the cross-attention maps of each compass token to its corresponding object regions. The trained model is able to achieve precise orientation control for a) complex objects not seen during training and b) multi-object scenes with more than two objects, indicating strong generalization capabilities. Further, when combined with personalization methods, our method precisely controls the orientation of the new object in diverse contexts. Our method achieves state-of-the-art orientation control and text alignment, quantified with extensive evaluations and a user study.
PreciseControl: Enhancing Text-To-Image Diffusion Models with Fine-Grained Attribute Control
Jul 24, 2024Recently, we have seen a surge of personalization methods for text-to-image (T2I) diffusion models to learn a concept using a few images. Existing approaches, when used for face personalization, suffer to achieve convincing inversion with identity preservation and rely on semantic text-based editing of the generated face. However, a more fine-grained control is desired for facial attribute editing, which is challenging to achieve solely with text prompts. In contrast, StyleGAN models learn a rich face prior and enable smooth control towards fine-grained attribute editing by latent manipulation. This work uses the disentangled $\mathcal{W+}$ space of StyleGANs to condition the T2I model. This approach allows us to precisely manipulate facial attributes, such as smoothly introducing a smile, while preserving the existing coarse text-based control inherent in T2I models. To enable conditioning of the T2I model on the $\mathcal{W+}$ space, we train a latent mapper to translate latent codes from $\mathcal{W+}$ to the token embedding space of the T2I model. The proposed approach excels in the precise inversion of face images with attribute preservation and facilitates continuous control for fine-grained attribute editing. Furthermore, our approach can be readily extended to generate compositions involving multiple individuals. We perform extensive experiments to validate our method for face personalization and fine-grained attribute editing.
Text2Place: Affordance-aware Text Guided Human Placement
Jul 22, 2024For a given scene, humans can easily reason for the locations and pose to place objects. Designing a computational model to reason about these affordances poses a significant challenge, mirroring the intuitive reasoning abilities of humans. This work tackles the problem of realistic human insertion in a given background scene termed as \textbf{Semantic Human Placement}. This task is extremely challenging given the diverse backgrounds, scale, and pose of the generated person and, finally, the identity preservation of the person. We divide the problem into the following two stages \textbf{i)} learning \textit{semantic masks} using text guidance for localizing regions in the image to place humans and \textbf{ii)} subject-conditioned inpainting to place a given subject adhering to the scene affordance within the \textit{semantic masks}. For learning semantic masks, we leverage rich object-scene priors learned from the text-to-image generative models and optimize a novel parameterization of the semantic mask, eliminating the need for large-scale training. To the best of our knowledge, we are the first ones to provide an effective solution for realistic human placements in diverse real-world scenes. The proposed method can generate highly realistic scene compositions while preserving the background and subject identity. Further, we present results for several downstream tasks - scene hallucination from a single or multiple generated persons and text-based attribute editing. With extensive comparisons against strong baselines, we show the superiority of our method in realistic human placement.
Crafting Parts for Expressive Object Composition
Jun 14, 2024Text-to-image generation from large generative models like Stable Diffusion, DALLE-2, etc., have become a common base for various tasks due to their superior quality and extensive knowledge bases. As image composition and generation are creative processes the artists need control over various parts of the images being generated. We find that just adding details about parts in the base text prompt either leads to an entirely different image (e.g., missing/incorrect identity) or the extra part details simply being ignored. To mitigate these issues, we introduce PartCraft, which enables image generation based on fine-grained part-level details specified for objects in the base text prompt. This allows more control for artists and enables novel object compositions by combining distinctive object parts. PartCraft first localizes object parts by denoising the object region from a specific diffusion process. This enables each part token to be localized to the right object region. After obtaining part masks, we run a localized diffusion process in each of the part regions based on fine-grained part descriptions and combine them to produce the final image. All the stages of PartCraft are based on repurposing a pre-trained diffusion model, which enables it to generalize across various domains without training. We demonstrate the effectiveness of part-level control provided by PartCraft qualitatively through visual examples and quantitatively in comparison to the contemporary baselines.
ProFeAT: Projected Feature Adversarial Training for Self-Supervised Learning of Robust Representations
Jun 09, 2024



The need for abundant labelled data in supervised Adversarial Training (AT) has prompted the use of Self-Supervised Learning (SSL) techniques with AT. However, the direct application of existing SSL methods to adversarial training has been sub-optimal due to the increased training complexity of combining SSL with AT. A recent approach, DeACL, mitigates this by utilizing supervision from a standard SSL teacher in a distillation setting, to mimic supervised AT. However, we find that there is still a large performance gap when compared to supervised adversarial training, specifically on larger models. In this work, investigate the key reason for this gap and propose Projected Feature Adversarial Training (ProFeAT) to bridge the same. We show that the sub-optimal distillation performance is a result of mismatch in training objectives of the teacher and student, and propose to use a projection head at the student, that allows it to leverage weak supervision from the teacher while also being able to learn adversarially robust representations that are distinct from the teacher. We further propose appropriate attack and defense losses at the feature and projector, alongside a combination of weak and strong augmentations for the teacher and student respectively, to improve the training data diversity without increasing the training complexity. Through extensive experiments on several benchmark datasets and models, we demonstrate significant improvements in both clean and robust accuracy when compared to existing SSL-AT methods, setting a new state-of-the-art. We further report on-par/ improved performance when compared to TRADES, a popular supervised-AT method.
DeiT-LT Distillation Strikes Back for Vision Transformer Training on Long-Tailed Datasets
Apr 03, 2024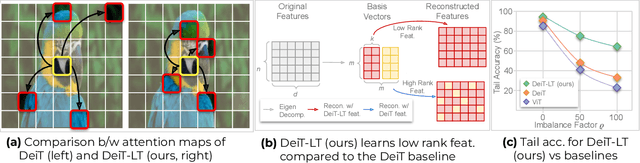
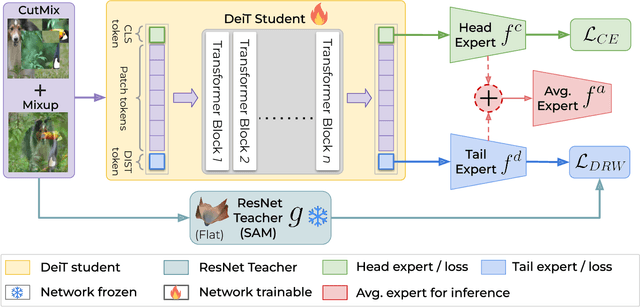
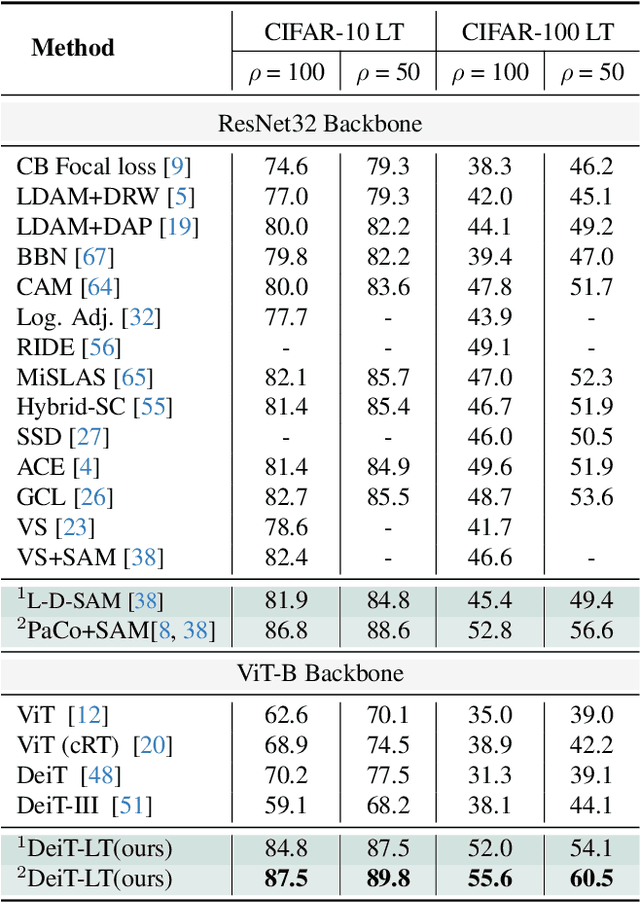
Vision Transformer (ViT) has emerged as a prominent architecture for various computer vision tasks. In ViT, we divide the input image into patch tokens and process them through a stack of self attention blocks. However, unlike Convolutional Neural Networks (CNN), ViTs simple architecture has no informative inductive bias (e.g., locality,etc. ). Due to this, ViT requires a large amount of data for pre-training. Various data efficient approaches (DeiT) have been proposed to train ViT on balanced datasets effectively. However, limited literature discusses the use of ViT for datasets with long-tailed imbalances. In this work, we introduce DeiT-LT to tackle the problem of training ViTs from scratch on long-tailed datasets. In DeiT-LT, we introduce an efficient and effective way of distillation from CNN via distillation DIST token by using out-of-distribution images and re-weighting the distillation loss to enhance focus on tail classes. This leads to the learning of local CNN-like features in early ViT blocks, improving generalization for tail classes. Further, to mitigate overfitting, we propose distilling from a flat CNN teacher, which leads to learning low-rank generalizable features for DIST tokens across all ViT blocks. With the proposed DeiT-LT scheme, the distillation DIST token becomes an expert on the tail classes, and the classifier CLS token becomes an expert on the head classes. The experts help to effectively learn features corresponding to both the majority and minority classes using a distinct set of tokens within the same ViT architecture. We show the effectiveness of DeiT-LT for training ViT from scratch on datasets ranging from small-scale CIFAR-10 LT to large-scale iNaturalist-2018.
Balancing Act: Distribution-Guided Debiasing in Diffusion Models
Feb 28, 2024Diffusion Models (DMs) have emerged as powerful generative models with unprecedented image generation capability. These models are widely used for data augmentation and creative applications. However, DMs reflect the biases present in the training datasets. This is especially concerning in the context of faces, where the DM prefers one demographic subgroup vs others (eg. female vs male). In this work, we present a method for debiasing DMs without relying on additional data or model retraining. Specifically, we propose Distribution Guidance, which enforces the generated images to follow the prescribed attribute distribution. To realize this, we build on the key insight that the latent features of denoising UNet hold rich demographic semantics, and the same can be leveraged to guide debiased generation. We train Attribute Distribution Predictor (ADP) - a small mlp that maps the latent features to the distribution of attributes. ADP is trained with pseudo labels generated from existing attribute classifiers. The proposed Distribution Guidance with ADP enables us to do fair generation. Our method reduces bias across single/multiple attributes and outperforms the baseline by a significant margin for unconditional and text-conditional diffusion models. Further, we present a downstream task of training a fair attribute classifier by rebalancing the training set with our generated data.