 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Layerwise Activation Norm Improves Generalization in Federated Learning
Dec 09, 2025Federated Learning (FL) is an emerging machine learning framework that enables multiple clients (coordinated by a server) to collaboratively train a global model by aggregating the locally trained models without sharing any client's training data. It has been observed in recent works that learning in a federated manner may lead the aggregated global model to converge to a 'sharp minimum' thereby adversely affecting the generalizability of this FL-trained model. Therefore, in this work, we aim to improve the generalization performance of models trained in a federated setup by introducing a 'flatness' constrained FL optimization problem. This flatness constraint is imposed on the top eigenvalue of the Hessian computed from the training loss. As each client trains a model on its local data, we further re-formulate this complex problem utilizing the client loss functions and propose a new computationally efficient regularization technique, dubbed 'MAN,' which Minimizes Activation's Norm of each layer on client-side models. We also theoretically show that minimizing the activation norm reduces the top eigenvalue of the layer-wise Hessian of the client's loss, which in turn decreases the overall Hessian's top eigenvalue, ensuring convergence to a flat minimum. We apply our proposed flatness-constrained optimization to the existing FL techniques and obtain significant improvements, thereby establishing new state-of-the-art.
Learning from Limited and Imperfect Data
Nov 11, 2024The datasets used for Deep Neural Network training (e.g., ImageNet, MSCOCO, etc.) are often manually balanced across categories (classes) to facilitate learning of all the categories. This curation process is often expensive and requires throwing away precious annotated data to balance the frequency across classes. This is because the distribution of data in the world (e.g., internet, etc.) significantly differs from the well-curated datasets and is often over-populated with samples from common categories. The algorithms designed for well-curated datasets perform suboptimally when used to learn from imperfect datasets with long-tailed imbalances and distribution shifts. For deep models to be widely used, getting away with the costly curation process by developing robust algorithms that can learn from real-world data distribution is necessary. Toward this goal, we develop practical algorithms for Deep Neural Networks that can learn from limited and imperfect data present in the real world. These works are divided into four segments, each covering a scenario of learning from limited or imperfect data. The first part of the works focuses on Learning Generative Models for Long-Tail Data, where we mitigate the mode-collapse for tail (minority) classes and enable diverse aesthetic image generations as head (majority) classes. In the second part, we enable effective generalization on tail classes through Inductive Regularization schemes, which allow tail classes to generalize as the head classes without enforcing explicit generation of images. In the third part, we develop algorithms for Optimizing Relevant Metrics compared to the average accuracy for learning from long-tailed data with limited annotation (semi-supervised), followed by the fourth part, which focuses on the effective domain adaptation of the model to various domains with zero to very few labeled samples.
Crafting Parts for Expressive Object Composition
Jun 14, 2024Text-to-image generation from large generative models like Stable Diffusion, DALLE-2, etc., have become a common base for various tasks due to their superior quality and extensive knowledge bases. As image composition and generation are creative processes the artists need control over various parts of the images being generated. We find that just adding details about parts in the base text prompt either leads to an entirely different image (e.g., missing/incorrect identity) or the extra part details simply being ignored. To mitigate these issues, we introduce PartCraft, which enables image generation based on fine-grained part-level details specified for objects in the base text prompt. This allows more control for artists and enables novel object compositions by combining distinctive object parts. PartCraft first localizes object parts by denoising the object region from a specific diffusion process. This enables each part token to be localized to the right object region. After obtaining part masks, we run a localized diffusion process in each of the part regions based on fine-grained part descriptions and combine them to produce the final image. All the stages of PartCraft are based on repurposing a pre-trained diffusion model, which enables it to generalize across various domains without training. We demonstrate the effectiveness of part-level control provided by PartCraft qualitatively through visual examples and quantitatively in comparison to the contemporary baselines.
DeiT-LT Distillation Strikes Back for Vision Transformer Training on Long-Tailed Datasets
Apr 03, 2024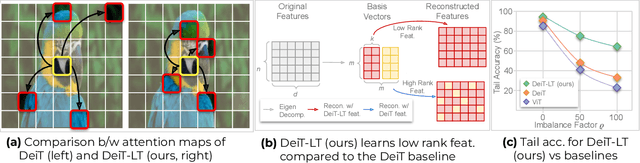
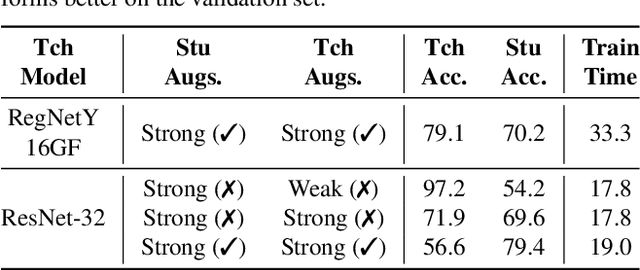
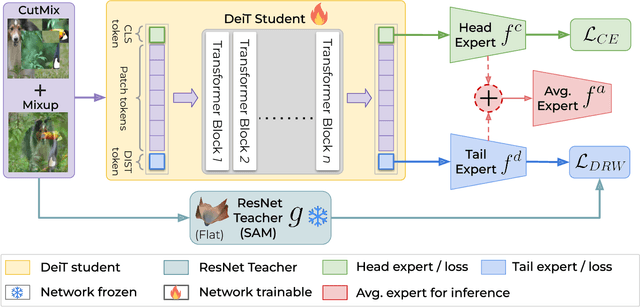
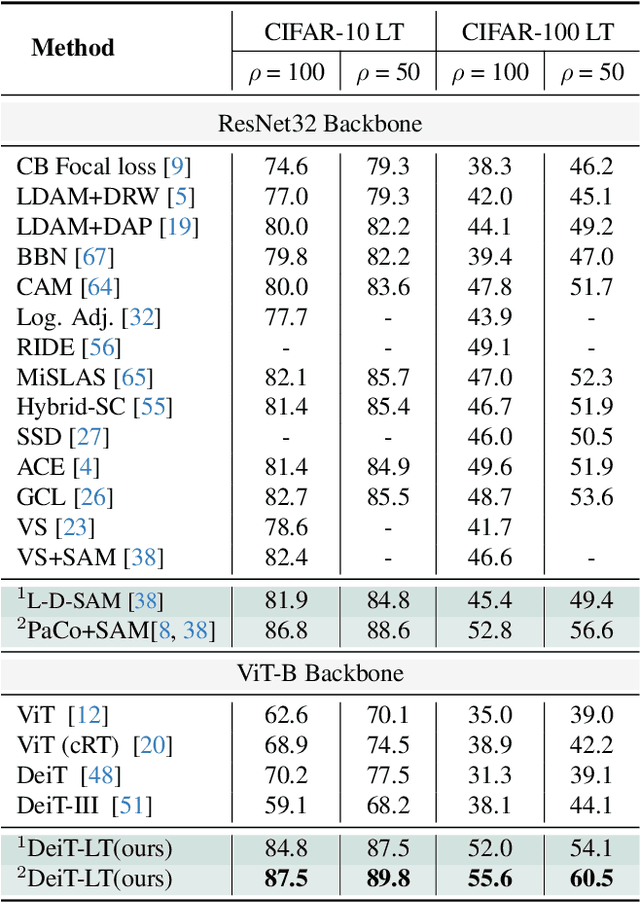
Vision Transformer (ViT) has emerged as a prominent architecture for various computer vision tasks. In ViT, we divide the input image into patch tokens and process them through a stack of self attention blocks. However, unlike Convolutional Neural Networks (CNN), ViTs simple architecture has no informative inductive bias (e.g., locality,etc. ). Due to this, ViT requires a large amount of data for pre-training. Various data efficient approaches (DeiT) have been proposed to train ViT on balanced datasets effectively. However, limited literature discusses the use of ViT for datasets with long-tailed imbalances. In this work, we introduce DeiT-LT to tackle the problem of training ViTs from scratch on long-tailed datasets. In DeiT-LT, we introduce an efficient and effective way of distillation from CNN via distillation DIST token by using out-of-distribution images and re-weighting the distillation loss to enhance focus on tail classes. This leads to the learning of local CNN-like features in early ViT blocks, improving generalization for tail classes. Further, to mitigate overfitting, we propose distilling from a flat CNN teacher, which leads to learning low-rank generalizable features for DIST tokens across all ViT blocks. With the proposed DeiT-LT scheme, the distillation DIST token becomes an expert on the tail classes, and the classifier CLS token becomes an expert on the head classes. The experts help to effectively learn features corresponding to both the majority and minority classes using a distinct set of tokens within the same ViT architecture. We show the effectiveness of DeiT-LT for training ViT from scratch on datasets ranging from small-scale CIFAR-10 LT to large-scale iNaturalist-2018.
Selective Mixup Fine-Tuning for Optimizing Non-Decomposable Objectives
Mar 27, 2024The rise in internet usage has led to the generation of massive amounts of data, resulting in the adoption of various supervised and semi-supervised machine learning algorithms, which can effectively utilize the colossal amount of data to train models. However, before deploying these models in the real world, these must be strictly evaluated on performance measures like worst-case recall and satisfy constraints such as fairness. We find that current state-of-the-art empirical techniques offer sub-optimal performance on these practical, non-decomposable performance objectives. On the other hand, the theoretical techniques necessitate training a new model from scratch for each performance objective. To bridge the gap, we propose SelMix, a selective mixup-based inexpensive fine-tuning technique for pre-trained models, to optimize for the desired objective. The core idea of our framework is to determine a sampling distribution to perform a mixup of features between samples from particular classes such that it optimizes the given objective. We comprehensively evaluate our technique against the existing empirical and theoretically principled methods on standard benchmark datasets for imbalanced classification. We find that proposed SelMix fine-tuning significantly improves the performance for various practical non-decomposable objectives across benchmarks.
Strata-NeRF : Neural Radiance Fields for Stratified Scenes
Aug 20, 2023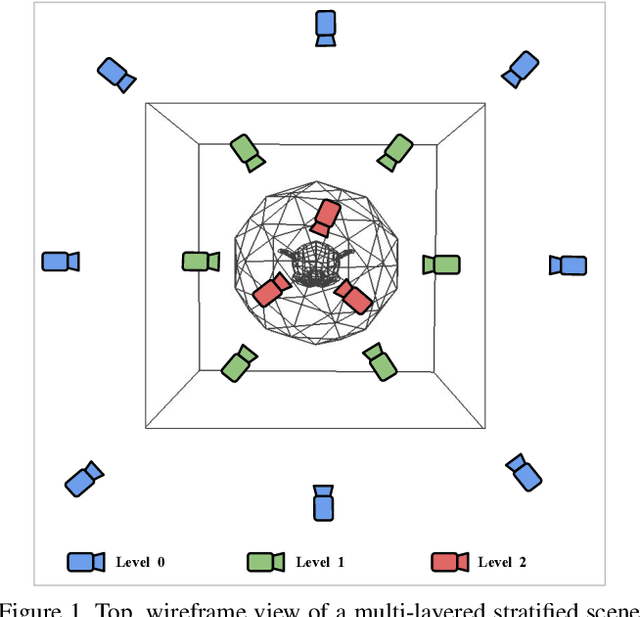
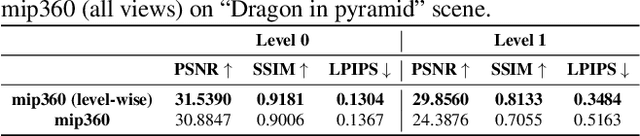

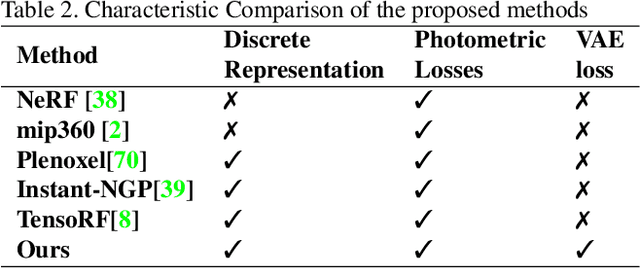
Neural Radiance Field (NeRF) approaches learn the underlying 3D representation of a scene and generate photo-realistic novel views with high fidelity. However, most proposed settings concentrate on modelling a single object or a single level of a scene. However, in the real world, we may capture a scene at multiple levels, resulting in a layered capture. For example, tourists usually capture a monument's exterior structure before capturing the inner structure. Modelling such scenes in 3D with seamless switching between levels can drastically improve immersive experiences. However, most existing techniques struggle in modelling such scenes. We propose Strata-NeRF, a single neural radiance field that implicitly captures a scene with multiple levels. Strata-NeRF achieves this by conditioning the NeRFs on Vector Quantized (VQ) latent representations which allow sudden changes in scene structure. We evaluate the effectiveness of our approach in multi-layered synthetic dataset comprising diverse scenes and then further validate its generalization on the real-world RealEstate10K dataset. We find that Strata-NeRF effectively captures stratified scenes, minimizes artifacts, and synthesizes high-fidelity views compared to existing approaches.
Cost-Sensitive Self-Training for Optimizing Non-Decomposable Metrics
Apr 28, 2023Self-training based semi-supervised learning algorithms have enabled the learning of highly accurate deep neural networks, using only a fraction of labeled data. However, the majority of work on self-training has focused on the objective of improving accuracy, whereas practical machine learning systems can have complex goals (e.g. maximizing the minimum of recall across classes, etc.) that are non-decomposable in nature. In this work, we introduce the Cost-Sensitive Self-Training (CSST) framework which generalizes the self-training-based methods for optimizing non-decomposable metrics. We prove that our framework can better optimize the desired non-decomposable metric utilizing unlabeled data, under similar data distribution assumptions made for the analysis of self-training. Using the proposed CSST framework, we obtain practical self-training methods (for both vision and NLP tasks) for optimizing different non-decomposable metrics using deep neural networks. Our results demonstrate that CSST achieves an improvement over the state-of-the-art in majority of the cases across datasets and objectives.
Certified Adversarial Robustness Within Multiple Perturbation Bounds
Apr 20, 2023



Randomized smoothing (RS) is a well known certified defense against adversarial attacks, which creates a smoothed classifier by predicting the most likely class under random noise perturbations of inputs during inference. While initial work focused on robustness to $\ell_2$ norm perturbations using noise sampled from a Gaussian distribution, subsequent works have shown that different noise distributions can result in robustness to other $\ell_p$ norm bounds as well. In general, a specific noise distribution is optimal for defending against a given $\ell_p$ norm based attack. In this work, we aim to improve the certified adversarial robustness against multiple perturbation bounds simultaneously. Towards this, we firstly present a novel \textit{certification scheme}, that effectively combines the certificates obtained using different noise distributions to obtain optimal results against multiple perturbation bounds. We further propose a novel \textit{training noise distribution} along with a \textit{regularized training scheme} to improve the certification within both $\ell_1$ and $\ell_2$ perturbation norms simultaneously. Contrary to prior works, we compare the certified robustness of different training algorithms across the same natural (clean) accuracy, rather than across fixed noise levels used for training and certification. We also empirically invalidate the argument that training and certifying the classifier with the same amount of noise gives the best results. The proposed approach achieves improvements on the ACR (Average Certified Radius) metric across both $\ell_1$ and $\ell_2$ perturbation bounds.
NoisyTwins: Class-Consistent and Diverse Image Generation through StyleGANs
Apr 12, 2023StyleGANs are at the forefront of controllable image generation as they produce a latent space that is semantically disentangled, making it suitable for image editing and manipulation. However, the performance of StyleGANs severely degrades when trained via class-conditioning on large-scale long-tailed datasets. We find that one reason for degradation is the collapse of latents for each class in the $\mathcal{W}$ latent space. With NoisyTwins, we first introduce an effective and inexpensive augmentation strategy for class embeddings, which then decorrelates the latents based on self-supervision in the $\mathcal{W}$ space. This decorrelation mitigates collapse, ensuring that our method preserves intra-class diversity with class-consistency in image generation. We show the effectiveness of our approach on large-scale real-world long-tailed datasets of ImageNet-LT and iNaturalist 2019, where our method outperforms other methods by $\sim 19\%$ on FID, establishing a new state-of-the-art.
Escaping Saddle Points for Effective Generalization on Class-Imbalanced Data
Dec 28, 2022Real-world datasets exhibit imbalances of varying types and degrees. Several techniques based on re-weighting and margin adjustment of loss are often used to enhance the performance of neural networks, particularly on minority classes. In this work, we analyze the class-imbalanced learning problem by examining the loss landscape of neural networks trained with re-weighting and margin-based techniques. Specifically, we examine the spectral density of Hessian of class-wise loss, through which we observe that the network weights converge to a saddle point in the loss landscapes of minority classes. Following this observation, we also find that optimization methods designed to escape from saddle points can be effectively used to improve generalization on minority classes. We further theoretically and empirically demonstrate that Sharpness-Aware Minimization (SAM), a recent technique that encourages convergence to a flat minima, can be effectively used to escape saddle points for minority classes. Using SAM results in a 6.2\% increase in accuracy on the minority classes over the state-of-the-art Vector Scaling Loss, leading to an overall average increase of 4\% across imbalanced datasets. The code is available at: https://github.com/val-iisc/Saddle-LongTail.