 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniC-Lift: Unified 3D Instance Segmentation via Contrastive Learning
Dec 31, 20253D Gaussian Splatting (3DGS) and Neural Radiance Fields (NeRF) have advanced novel-view synthesis. Recent methods extend multi-view 2D segmentation to 3D, enabling instance/semantic segmentation for better scene understanding. A key challenge is the inconsistency of 2D instance labels across views, leading to poor 3D predictions. Existing methods use a two-stage approach in which some rely on contrastive learning with hyperparameter-sensitive clustering, while others preprocess labels for consistency. We propose a unified framework that merges these steps, reducing training time and improving performance by introducing a learnable feature embedding for segmentation in Gaussian primitives. This embedding is then efficiently decoded into instance labels through a novel "Embedding-to-Label" process, effectively integrating the optimization. While this unified framework offers substantial benefits, we observed artifacts at the object boundaries. To address the object boundary issues, we propose hard-mining samples along these boundaries. However, directly applying hard mining to the feature embeddings proved unstable. Therefore, we apply a linear layer to the rasterized feature embeddings before calculating the triplet loss, which stabilizes training and significantly improves performance. Our method outperforms baselines qualitatively and quantitatively on the ScanNet, Replica3D, and Messy-Rooms datasets.
Instructive3D: Editing Large Reconstruction Models with Text Instructions
Jan 08, 2025



Transformer based methods have enabled users to create, modify, and comprehend text and image data. Recently proposed Large Reconstruction Models (LRMs) further extend this by providing the ability to generate high-quality 3D models with the help of a single object image. These models, however, lack the ability to manipulate or edit the finer details, such as adding standard design patterns or changing the color and reflectance of the generated objects, thus lacking fine-grained control that may be very helpful in domains such as augmented reality, animation and gaming. Naively training LRMs for this purpose would require generating precisely edited images and 3D object pairs, which is computationally expensive. In this paper, we propose Instructive3D, a novel LRM based model that integrates generation and fine-grained editing, through user text prompts, of 3D objects into a single model. We accomplish this by adding an adapter that performs a diffusion process conditioned on a text prompt specifying edits in the triplane latent space representation of 3D object models. Our method does not require the generation of edited 3D objects. Additionally, Instructive3D allows us to perform geometrically consistent modifications, as the edits done through user-defined text prompts are applied to the triplane latent representation thus enhancing the versatility and precision of 3D objects generated. We compare the objects generated by Instructive3D and a baseline that first generates the 3D object meshes using a standard LRM model and then edits these 3D objects using text prompts when images are provided from the Objaverse LVIS dataset. We find that Instructive3D produces qualitatively superior 3D objects with the properties specified by the edit prompts.
CoRF : Colorizing Radiance Fields using Knowledge Distillation
Sep 14, 2023



Neural radiance field (NeRF) based methods enable high-quality novel-view synthesis for multi-view images. This work presents a method for synthesizing colorized novel views from input grey-scale multi-view images. When we apply image or video-based colorization methods on the generated grey-scale novel views, we observe artifacts due to inconsistency across views. Training a radiance field network on the colorized grey-scale image sequence also does not solve the 3D consistency issue. We propose a distillation based method to transfer color knowledge from the colorization networks trained on natural images to the radiance field network. Specifically, our method uses the radiance field network as a 3D representation and transfers knowledge from existing 2D colorization methods. The experimental results demonstrate that the proposed method produces superior colorized novel views for indoor and outdoor scenes while maintaining cross-view consistency than baselines. Further, we show the efficacy of our method on applications like colorization of radiance field network trained from 1.) Infra-Red (IR) multi-view images and 2.) Old grey-scale multi-view image sequences.
Strata-NeRF : Neural Radiance Fields for Stratified Scenes
Aug 20, 2023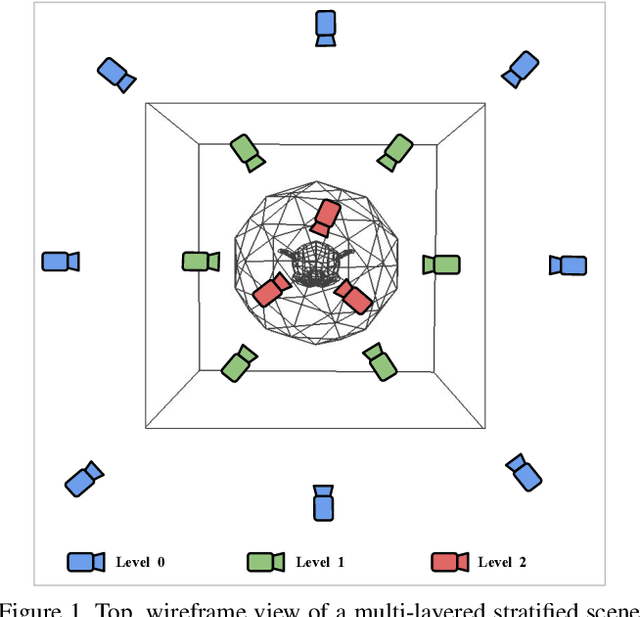
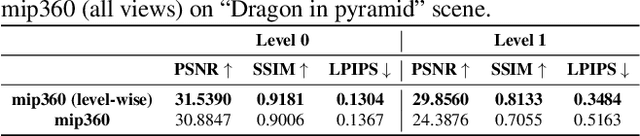

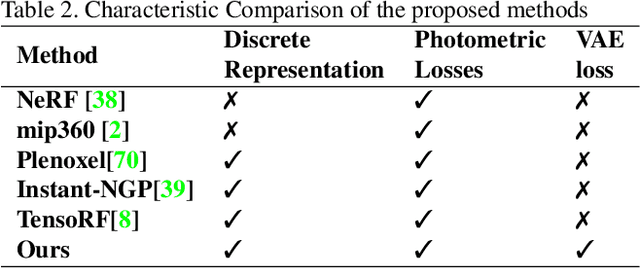
Neural Radiance Field (NeRF) approaches learn the underlying 3D representation of a scene and generate photo-realistic novel views with high fidelity. However, most proposed settings concentrate on modelling a single object or a single level of a scene. However, in the real world, we may capture a scene at multiple levels, resulting in a layered capture. For example, tourists usually capture a monument's exterior structure before capturing the inner structure. Modelling such scenes in 3D with seamless switching between levels can drastically improve immersive experiences. However, most existing techniques struggle in modelling such scenes. We propose Strata-NeRF, a single neural radiance field that implicitly captures a scene with multiple levels. Strata-NeRF achieves this by conditioning the NeRFs on Vector Quantized (VQ) latent representations which allow sudden changes in scene structure. We evaluate the effectiveness of our approach in multi-layered synthetic dataset comprising diverse scenes and then further validate its generalization on the real-world RealEstate10K dataset. We find that Strata-NeRF effectively captures stratified scenes, minimizes artifacts, and synthesizes high-fidelity views compared to existing approaches.