 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamControl: Human-Inspired Whole-Body Humanoid Control for Scene Interaction via Guided Diffusion
Sep 17, 2025
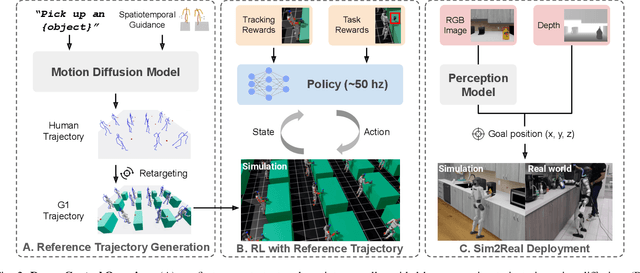

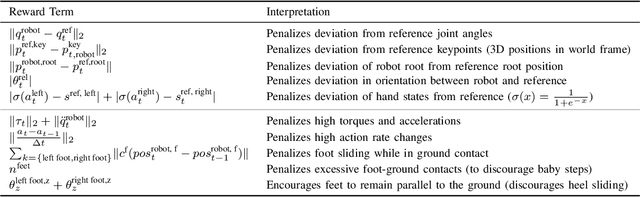
We introduce DreamControl, a novel methodology for learning autonomous whole-body humanoid skills. DreamControl leverages the strengths of diffusion models and Reinforcement Learning (RL): our core innovation is the use of a diffusion prior trained on human motion data, which subsequently guides an RL policy in simulation to complete specific tasks of interest (e.g., opening a drawer or picking up an object). We demonstrate that this human motion-informed prior allows RL to discover solutions unattainable by direct RL, and that diffusion models inherently promote natural looking motions, aiding in sim-to-real transfer. We validate DreamControl's effectiveness on a Unitree G1 robot across a diverse set of challenging tasks involving simultaneous lower and upper body control and object interaction.
UniTac: Whole-Robot Touch Sensing Without Tactile Sensors
Jul 10, 2025Robots can better interact with humans and unstructured environments through touch sensing. However, most commercial robots are not equipped with tactile skins, making it challenging to achieve even basic touch-sensing functions, such as contact localization. We present UniTac, a data-driven whole-body touch-sensing approach that uses only proprioceptive joint sensors and does not require the installation of additional sensors. Our approach enables a robot equipped solely with joint sensors to localize contacts. Our goal is to democratize touch sensing and provide an off-the-shelf tool for HRI researchers to provide their robots with touch-sensing capabilities. We validate our approach on two platforms: the Franka robot arm and the Spot quadruped. On Franka, we can localize contact to within 8.0 centimeters, and on Spot, we can localize to within 7.2 centimeters at around 2,000 Hz on an RTX 3090 GPU without adding any additional sensors to the robot. Project website: https://ivl.cs.brown.edu/research/unitac.
GenHSI: Controllable Generation of Human-Scene Interaction Videos
Jun 24, 2025Large-scale pre-trained video diffusion models have exhibited remarkable capabilities in diverse video generation. However, existing solutions face several challenges in using these models to generate long movie-like videos with rich human-object interactions that include unrealistic human-scene interaction, lack of subject identity preservation, and require expensive training. We propose GenHSI, a training-free method for controllable generation of long human-scene interaction videos (HSI). Taking inspiration from movie animation, our key insight is to overcome the limitations of previous work by subdividing the long video generation task into three stages: (1) script writing, (2) pre-visualization, and (3) animation. Given an image of a scene, a user description, and multiple images of a person, we use these three stages to generate long-videos that preserve human-identity and provide rich human-scene interactions. Script writing converts complex human tasks into simple atomic tasks that are used in the pre-visualization stage to generate 3D keyframes (storyboards). These 3D keyframes are rendered and animated by off-the-shelf video diffusion models for consistent long video generation with rich contacts in a 3D-aware manner. A key advantage of our work is that we alleviate the need for scanned, accurate scenes and create 3D keyframes from single-view images. We are the first to generate a long video sequence with a consistent camera pose that contains arbitrary numbers of character actions without training. Experiments demonstrate that our method can generate long videos that effectively preserve scene content and character identity with plausible human-scene interaction from a single image scene. Visit our project homepage https://kunkun0w0.github.io/project/GenHSI/ for more information.
ViTa-Zero: Zero-shot Visuotactile Object 6D Pose Estimation
Apr 17, 2025Object 6D pose estimation is a critical challenge in robotics, particularly for manipulation tasks. While prior research combining visual and tactile (visuotactile) information has shown promise, these approaches often struggle with generalization due to the limited availability of visuotactile data. In this paper, we introduce ViTa-Zero, a zero-shot visuotactile pose estimation framework. Our key innovation lies in leveraging a visual model as its backbone and performing feasibility checking and test-time optimization based on physical constraints derived from tactile and proprioceptive observations. Specifically, we model the gripper-object interaction as a spring-mass system, where tactile sensors induce attractive forces, and proprioception generates repulsive forces. We validate our framework through experiments on a real-world robot setup, demonstrating its effectiveness across representative visual backbones and manipulation scenarios, including grasping, object picking, and bimanual handover. Compared to the visual models, our approach overcomes some drastic failure modes while tracking the in-hand object pose. In our experiments, our approach shows an average increase of 55% in AUC of ADD-S and 60% in ADD, along with an 80% lower position error compared to FoundationPose.
Art3D: Training-Free 3D Generation from Flat-Colored Illustration
Apr 14, 2025Large-scale pre-trained image-to-3D generative models have exhibited remarkable capabilities in diverse shape generations. However, most of them struggle to synthesize plausible 3D assets when the reference image is flat-colored like hand drawings due to the lack of 3D illusion, which are often the most user-friendly input modalities in art content creation. To this end, we propose Art3D, a training-free method that can lift flat-colored 2D designs into 3D. By leveraging structural and semantic features with pre- trained 2D image generation models and a VLM-based realism evaluation, Art3D successfully enhances the three-dimensional illusion in reference images, thus simplifying the process of generating 3D from 2D, and proves adaptable to a wide range of painting styles. To benchmark the generalization performance of existing image-to-3D models on flat-colored images without 3D feeling, we collect a new dataset, Flat-2D, with over 100 samples. Experimental results demonstrate the performance and robustness of Art3D, exhibiting superior generalizable capacity and promising practical applicability. Our source code and dataset will be publicly available on our project page: https://joy-jy11.github.io/ .
InteractAvatar: Modeling Hand-Face Interaction in Photorealistic Avatars with Deformable Gaussians
Apr 10, 2025With the rising interest from the community in digital avatars coupled with the importance of expressions and gestures in communication, modeling natural avatar behavior remains an important challenge across many industries such as teleconferencing, gaming, and AR/VR. Human hands are the primary tool for interacting with the environment and essential for realistic human behavior modeling, yet existing 3D hand and head avatar models often overlook the crucial aspect of hand-body interactions, such as between hand and face. We present InteracttAvatar, the first model to faithfully capture the photorealistic appearance of dynamic hand and non-rigid hand-face interactions. Our novel Dynamic Gaussian Hand model, combining template model and 3D Gaussian Splatting as well as a dynamic refinement module, captures pose-dependent change, e.g. the fine wrinkles and complex shadows that occur during articulation. Importantly, our hand-face interaction module models the subtle geometry and appearance dynamics that underlie common gestures. Through experiments of novel view synthesis, self reenactment and cross-identity reenactment, we demonstrate that InteracttAvatar can reconstruct hand and hand-face interactions from monocular or multiview videos with high-fidelity details and be animated with novel poses.
V-HOP: Visuo-Haptic 6D Object Pose Tracking
Feb 24, 2025Humans naturally integrate vision and haptics for robust object perception during manipulation. The loss of either modality significantly degrades performance. Inspired by this multisensory integration, prior object pose estimation research has attempted to combine visual and haptic/tactile feedback. Although these works demonstrate improvements in controlled environments or synthetic datasets, they often underperform vision-only approaches in real-world settings due to poor generalization across diverse grippers, sensor layouts, or sim-to-real environments. Furthermore, they typically estimate the object pose for each frame independently, resulting in less coherent tracking over sequences in real-world deployments. To address these limitations, we introduce a novel unified haptic representation that effectively handles multiple gripper embodiments. Building on this representation, we introduce a new visuo-haptic transformer-based object pose tracker that seamlessly integrates visual and haptic input. We validate our framework in our dataset and the Feelsight dataset, demonstrating significant performance improvement on challenging sequences. Notably, our method achieves superior generalization and robustness across novel embodiments, objects, and sensor types (both taxel-based and vision-based tactile sensors). In real-world experiments, we demonstrate that our approach outperforms state-of-the-art visual trackers by a large margin. We further show that we can achieve precise manipulation tasks by incorporating our real-time object tracking result into motion plans, underscoring the advantages of visuo-haptic perception. Our model and dataset will be made open source upon acceptance of the paper. Project website: https://lhy.xyz/projects/v-hop/
UVGS: Reimagining Unstructured 3D Gaussian Splatting using UV Mapping
Feb 03, 20253D Gaussian Splatting (3DGS) has demonstrated superior quality in modeling 3D objects and scenes. However, generating 3DGS remains challenging due to their discrete, unstructured, and permutation-invariant nature. In this work, we present a simple yet effective method to overcome these challenges. We utilize spherical mapping to transform 3DGS into a structured 2D representation, termed UVGS. UVGS can be viewed as multi-channel images, with feature dimensions as a concatenation of Gaussian attributes such as position, scale, color, opacity, and rotation. We further find that these heterogeneous features can be compressed into a lower-dimensional (e.g., 3-channel) shared feature space using a carefully designed multi-branch network. The compressed UVGS can be treated as typical RGB images. Remarkably, we discover that typical VAEs trained with latent diffusion models can directly generalize to this new representation without additional training. Our novel representation makes it effortless to leverage foundational 2D models, such as diffusion models, to directly model 3DGS. Additionally, one can simply increase the 2D UV resolution to accommodate more Gaussians, making UVGS a scalable solution compared to typical 3D backbones. This approach immediately unlocks various novel generation applications of 3DGS by inherently utilizing the already developed superior 2D generation capabilities. In our experiments, we demonstrate various unconditional, conditional generation, and inpainting applications of 3DGS based on diffusion models, which were previously non-trivial.
ProcTex: Consistent and Interactive Text-to-texture Synthesis for Procedural Models
Jan 28, 2025



Recent advancement in 2D image diffusion models has driven significant progress in text-guided texture synthesis, enabling realistic, high-quality texture generation from arbitrary text prompts. However, current methods usually focus on synthesizing texture for single static 3D objects, and struggle to handle entire families of shapes, such as those produced by procedural programs. Applying existing methods naively to each procedural shape is too slow to support exploring different parameter settings at interactive rates, and also results in inconsistent textures across the procedural shapes. To this end, we introduce ProcTex, the first text-to-texture system designed for procedural 3D models. ProcTex enables consistent and real-time text-guided texture synthesis for families of shapes, which integrates seamlessly with the interactive design flow of procedural models. To ensure consistency, our core approach is to generate texture for the shape produced by one setting of the procedural parameters, followed by a texture transfer stage to apply the texture to other parameter settings. We also develop several techniques, including a novel UV displacement network for real-time texture transfer, the retexturing pipeline to support structural changes from discrete procedural parameters, and part-level UV texture map generation for local appearance editing. Extensive experiments on a diverse set of professional procedural models validate ProcTex's ability to produce high-quality, visually consistent textures while supporting real-time, interactive applications.
Turbo-GS: Accelerating 3D Gaussian Fitting for High-Quality Radiance Fields
Dec 18, 2024



Novel-view synthesis is an important problem in computer vision with applications in 3D reconstruction, mixed reality, and robotics. Recent methods like 3D Gaussian Splatting (3DGS) have become the preferred method for this task, providing high-quality novel views in real time. However, the training time of a 3DGS model is slow, often taking 30 minutes for a scene with 200 views. In contrast, our goal is to reduce the optimization time by training for fewer steps while maintaining high rendering quality. Specifically, we combine the guidance from both the position error and the appearance error to achieve a more effective densification. To balance the rate between adding new Gaussians and fitting old Gaussians, we develop a convergence-aware budget control mechanism. Moreover, to make the densification process more reliable, we selectively add new Gaussians from mostly visited regions. With these designs, we reduce the Gaussian optimization steps to one-third of the previous approach while achieving a comparable or even better novel view rendering quality. To further facilitate the rapid fitting of 4K resolution images, we introduce a dilation-based rendering technique. Our method, Turbo-GS, speeds up optimization for typical scenes and scales well to high-resolution (4K) scenarios on standard datasets. Through extensive experiments, we show that our method is significantly faster in optimization than other methods while retaining quality. Project page: https://ivl.cs.brown.edu/research/turbo-gs.