 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Noise to Control: Parameterized Diffusion Policies
May 29, 2026We propose Parameterized Diffusion Policy (PDP), a framework for learning diffusion policies conditioned on low-dimensional, continuous parameters embedded in a learned behavior manifold. By constructing this manifold so that distances between latent representations reflect the semantic similarity between physical trajectories, we transform diffusion from a mechanism for stochastic diversity into a precise and optimizable tool for behavior steering. Our approach enables smooth interpolation between known strategies and efficient adaptation to novel constraints without updating policy weights. We demonstrate that PDP significantly improves adaptation performance on complex multimodal benchmarks in both simulated and real-robot experiments compared to standard diffusion policies, particularly in scenarios requiring the synthesis of novel behaviors.
Self-Adapting Improvement Loops for Robotic Learning
Jun 07, 2025



Video generative models trained on expert demonstrations have been utilized as performant text-conditioned visual planners for solving robotic tasks. However, generalization to unseen tasks remains a challenge. Whereas improved generalization may be facilitated by leveraging learned prior knowledge from additional pre-collected offline data sources, such as web-scale video datasets, in the era of experience we aim to design agents that can continuously improve in an online manner from self-collected behaviors. In this work we thus propose the Self-Adapting Improvement Loop (SAIL), where an in-domain video model iteratively updates itself on self-produced trajectories, collected through adaptation with an internet-scale pretrained video model, and steadily improves its performance for a specified task of interest. We apply SAIL to a diverse suite of MetaWorld tasks, as well as two manipulation tasks on a real robot arm, and find that performance improvements continuously emerge over multiple iterations for novel tasks initially unseen during original in-domain video model training. Furthermore, we discover that SAIL is surprisingly robust regarding if and how the self-collected experience is filtered, and the quality of the initial in-domain demonstrations. Through adaptation with summarized internet-scale data, and learning through online experience, we thus demonstrate a way to iteratively bootstrap a high-performance video model for solving novel robotic tasks through self-improvement.
Optimal Interactive Learning on the Job via Facility Location Planning
May 01, 2025Collaborative robots must continually adapt to novel tasks and user preferences without overburdening the user. While prior interactive robot learning methods aim to reduce human effort, they are typically limited to single-task scenarios and are not well-suited for sustained, multi-task collaboration. We propose COIL (Cost-Optimal Interactive Learning) -- a multi-task interaction planner that minimizes human effort across a sequence of tasks by strategically selecting among three query types (skill, preference, and help). When user preferences are known, we formulate COIL as an uncapacitated facility location (UFL) problem, which enables bounded-suboptimal planning in polynomial time using off-the-shelf approximation algorithms. We extend our formulation to handle uncertainty in user preferences by incorporating one-step belief space planning, which uses these approximation algorithms as subroutines to maintain polynomial-time performance. Simulated and physical experiments on manipulation tasks show that our framework significantly reduces the amount of work allocated to the human while maintaining successful task completion.
V-HOP: Visuo-Haptic 6D Object Pose Tracking
Feb 24, 2025Humans naturally integrate vision and haptics for robust object perception during manipulation. The loss of either modality significantly degrades performance. Inspired by this multisensory integration, prior object pose estimation research has attempted to combine visual and haptic/tactile feedback. Although these works demonstrate improvements in controlled environments or synthetic datasets, they often underperform vision-only approaches in real-world settings due to poor generalization across diverse grippers, sensor layouts, or sim-to-real environments. Furthermore, they typically estimate the object pose for each frame independently, resulting in less coherent tracking over sequences in real-world deployments. To address these limitations, we introduce a novel unified haptic representation that effectively handles multiple gripper embodiments. Building on this representation, we introduce a new visuo-haptic transformer-based object pose tracker that seamlessly integrates visual and haptic input. We validate our framework in our dataset and the Feelsight dataset, demonstrating significant performance improvement on challenging sequences. Notably, our method achieves superior generalization and robustness across novel embodiments, objects, and sensor types (both taxel-based and vision-based tactile sensors). In real-world experiments, we demonstrate that our approach outperforms state-of-the-art visual trackers by a large margin. We further show that we can achieve precise manipulation tasks by incorporating our real-time object tracking result into motion plans, underscoring the advantages of visuo-haptic perception. Our model and dataset will be made open source upon acceptance of the paper. Project website: https://lhy.xyz/projects/v-hop/
Open-vocabulary Pick and Place via Patch-level Semantic Maps
Jun 21, 2024Controlling robots through natural language instructions in open-vocabulary scenarios is pivotal for enhancing human-robot collaboration and complex robot behavior synthesis. However, achieving this capability poses significant challenges due to the need for a system that can generalize from limited data to a wide range of tasks and environments. Existing methods rely on large, costly datasets and struggle with generalization. This paper introduces Grounded Equivariant Manipulation (GEM), a novel approach that leverages the generative capabilities of pre-trained vision-language models and geometric symmetries to facilitate few-shot and zero-shot learning for open-vocabulary robot manipulation tasks. Our experiments demonstrate GEM's high sample efficiency and superior generalization across diverse pick-and-place tasks in both simulation and real-world experiments, showcasing its ability to adapt to novel instructions and unseen objects with minimal data requirements. GEM advances a significant step forward in the domain of language-conditioned robot control, bridging the gap between semantic understanding and action generation in robotic systems.
Imagination Policy: Using Generative Point Cloud Models for Learning Manipulation Policies
Jun 17, 2024


Humans can imagine goal states during planning and perform actions to match those goals. In this work, we propose Imagination Policy, a novel multi-task key-frame policy network for solving high-precision pick and place tasks. Instead of learning actions directly, Imagination Policy generates point clouds to imagine desired states which are then translated to actions using rigid action estimation. This transforms action inference into a local generative task. We leverage pick and place symmetries underlying the tasks in the generation process and achieve extremely high sample efficiency and generalizability to unseen configurations. Finally, we demonstrate state-of-the-art performance across various tasks on the RLbench benchmark compared with several strong baselines.
SEIL: Simulation-augmented Equivariant Imitation Learning
Oct 31, 2022In robotic manipulation, acquiring samples is extremely expensive because it often requires interacting with the real world. Traditional image-level data augmentation has shown the potential to improve sample efficiency in various machine learning tasks. However, image-level data augmentation is insufficient for an imitation learning agent to learn good manipulation policies in a reasonable amount of demonstrations. We propose Simulation-augmented Equivariant Imitation Learning (SEIL), a method that combines a novel data augmentation strategy of supplementing expert trajectories with simulated transitions and an equivariant model that exploits the $\mathrm{O}(2)$ symmetry in robotic manipulation. Experimental evaluations demonstrate that our method can learn non-trivial manipulation tasks within ten demonstrations and outperforms the baselines with a significant margin.
BulletArm: An Open-Source Robotic Manipulation Benchmark and Learning Framework
May 28, 2022


We present BulletArm, a novel benchmark and learning-environment for robotic manipulation. BulletArm is designed around two key principles: reproducibility and extensibility. We aim to encourage more direct comparisons between robotic learning methods by providing a set of standardized benchmark tasks in simulation alongside a collection of baseline algorithms. The framework consists of 31 different manipulation tasks of varying difficulty, ranging from simple reaching and picking tasks to more realistic tasks such as bin packing and pallet stacking. In addition to the provided tasks, BulletArm has been built to facilitate easy expansion and provides a suite of tools to assist users when adding new tasks to the framework. Moreover, we introduce a set of five benchmarks and evaluate them using a series of state-of-the-art baseline algorithms. By including these algorithms as part of our framework, we hope to encourage users to benchmark their work on any new tasks against these baselines.
On-Robot Policy Learning with $\mathrm{O}$-Equivariant SAC
Mar 09, 2022


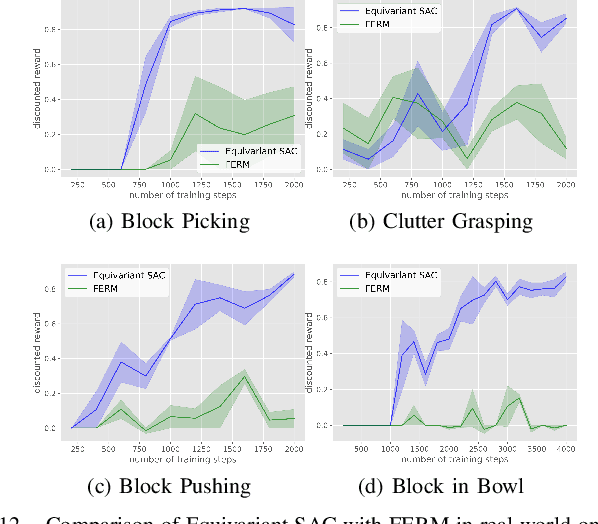
Recently, equivariant neural network models have been shown to be useful in improving sample efficiency for tasks in computer vision and reinforcement learning. This paper explores this idea in the context of on-robot policy learning where a policy must be learned entirely on a physical robotic system without reference to a model, a simulator, or an offline dataset. We focus on applications of $\mathrm{SO}(2)$-Equivariant SAC to robotic manipulation and explore a number of variations of the algorithm. Ultimately, we demonstrate the ability to learn several non-trivial manipulation tasks completely through on-robot experiences in less than an hour or two of wall clock time.