 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Adapting Improvement Loops for Robotic Learning
Jun 07, 2025



Video generative models trained on expert demonstrations have been utilized as performant text-conditioned visual planners for solving robotic tasks. However, generalization to unseen tasks remains a challenge. Whereas improved generalization may be facilitated by leveraging learned prior knowledge from additional pre-collected offline data sources, such as web-scale video datasets, in the era of experience we aim to design agents that can continuously improve in an online manner from self-collected behaviors. In this work we thus propose the Self-Adapting Improvement Loop (SAIL), where an in-domain video model iteratively updates itself on self-produced trajectories, collected through adaptation with an internet-scale pretrained video model, and steadily improves its performance for a specified task of interest. We apply SAIL to a diverse suite of MetaWorld tasks, as well as two manipulation tasks on a real robot arm, and find that performance improvements continuously emerge over multiple iterations for novel tasks initially unseen during original in-domain video model training. Furthermore, we discover that SAIL is surprisingly robust regarding if and how the self-collected experience is filtered, and the quality of the initial in-domain demonstrations. Through adaptation with summarized internet-scale data, and learning through online experience, we thus demonstrate a way to iteratively bootstrap a high-performance video model for solving novel robotic tasks through self-improvement.
Solving New Tasks by Adapting Internet Video Knowledge
Apr 21, 2025Video generative models demonstrate great promise in robotics by serving as visual planners or as policy supervisors. When pretrained on internet-scale data, such video models intimately understand alignment with natural language, and can thus facilitate generalization to novel downstream behavior through text-conditioning. However, they may not be sensitive to the specificities of the particular environment the agent inhabits. On the other hand, training video models on in-domain examples of robotic behavior naturally encodes environment-specific intricacies, but the scale of available demonstrations may not be sufficient to support generalization to unseen tasks via natural language specification. In this work, we investigate different adaptation techniques that integrate in-domain information with large-scale pretrained video models, and explore the extent to which they enable novel text-conditioned generalization for robotic tasks, while also considering their independent data and resource considerations. We successfully demonstrate across robotic environments that adapting powerful video models with small scales of example data can successfully facilitate generalization to novel behaviors. In particular, we present a novel adaptation strategy, termed Inverse Probabilistic Adaptation, that not only consistently achieves strong generalization performance across robotic tasks and settings, but also exhibits robustness to the quality of adaptation data, successfully solving novel tasks even when only suboptimal in-domain demonstrations are available.
Text-Aware Diffusion for Policy Learning
Jul 02, 2024

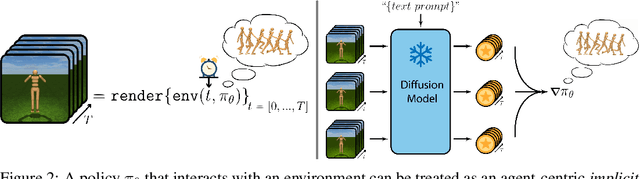
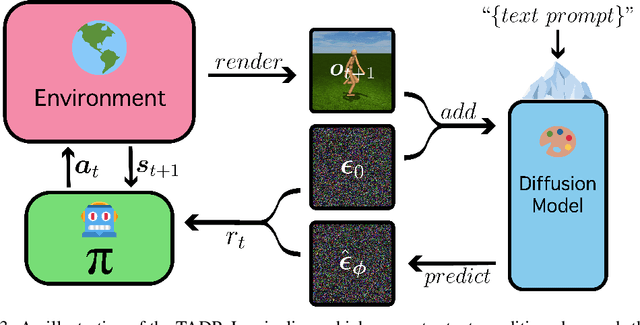
Training an agent to achieve particular goals or perform desired behaviors is often accomplished through reinforcement learning, especially in the absence of expert demonstrations. However, supporting novel goals or behaviors through reinforcement learning requires the ad-hoc design of appropriate reward functions, which quickly becomes intractable. To address this challenge, we propose Text-Aware Diffusion for Policy Learning (TADPoLe), which uses a pretrained, frozen text-conditioned diffusion model to compute dense zero-shot reward signals for text-aligned policy learning. We hypothesize that large-scale pretrained generative models encode rich priors that can supervise a policy to behave not only in a text-aligned manner, but also in alignment with a notion of naturalness summarized from internet-scale training data. In our experiments, we demonstrate that TADPoLe is able to learn policies for novel goal-achievement and continuous locomotion behaviors specified by natural language, in both Humanoid and Dog environments. The behaviors are learned zero-shot without ground-truth rewards or expert demonstrations, and are qualitatively more natural according to human evaluation. We further show that TADPoLe performs competitively when applied to robotic manipulation tasks in the Meta-World environment.
Self-Correcting Self-Consuming Loops for Generative Model Training
Feb 11, 2024



As synthetic data becomes higher quality and proliferates on the internet, machine learning models are increasingly trained on a mix of human- and machine-generated data. Despite the successful stories of using synthetic data for representation learning, using synthetic data for generative model training creates "self-consuming loops" which may lead to training instability or even collapse, unless certain conditions are met. Our paper aims to stabilize self-consuming generative model training. Our theoretical results demonstrate that by introducing an idealized correction function, which maps a data point to be more likely under the true data distribution, self-consuming loops can be made exponentially more stable. We then propose self-correction functions, which rely on expert knowledge (e.g. the laws of physics programmed in a simulator), and aim to approximate the idealized corrector automatically and at scale. We empirically validate the effectiveness of self-correcting self-consuming loops on the challenging human motion synthesis task, and observe that it successfully avoids model collapse, even when the ratio of synthetic data to real data is as high as 100%.
Towards A Unified Neural Architecture for Visual Recognition and Reasoning
Nov 10, 2023
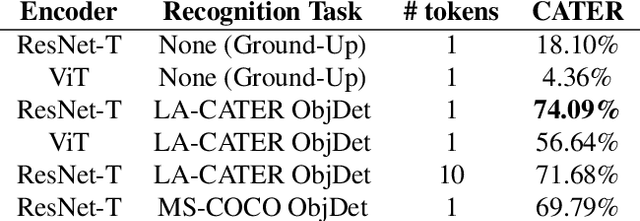


Recognition and reasoning are two pillars of visual understanding. However, these tasks have an imbalance in focus; whereas recent advances in neural networks have shown strong empirical performance in visual recognition, there has been comparably much less success in solving visual reasoning. Intuitively, unifying these two tasks under a singular framework is desirable, as they are mutually dependent and beneficial. Motivated by the recent success of multi-task transformers for visual recognition and language understanding, we propose a unified neural architecture for visual recognition and reasoning with a generic interface (e.g., tokens) for both. Our framework enables the principled investigation of how different visual recognition tasks, datasets, and inductive biases can help enable spatiotemporal reasoning capabilities. Noticeably, we find that object detection, which requires spatial localization of individual objects, is the most beneficial recognition task for reasoning. We further demonstrate via probing that implicit object-centric representations emerge automatically inside our framework. Intriguingly, we discover that certain architectural choices such as the backbone model of the visual encoder have a significant impact on visual reasoning, but little on object detection. Given the results of our experiments, we believe that visual reasoning should be considered as a first-class citizen alongside visual recognition, as they are strongly correlated but benefit from potentially different design choices.
Does Visual Pretraining Help End-to-End Reasoning?
Jul 17, 2023



We aim to investigate whether end-to-end learning of visual reasoning can be achieved with general-purpose neural networks, with the help of visual pretraining. A positive result would refute the common belief that explicit visual abstraction (e.g. object detection) is essential for compositional generalization on visual reasoning, and confirm the feasibility of a neural network "generalist" to solve visual recognition and reasoning tasks. We propose a simple and general self-supervised framework which "compresses" each video frame into a small set of tokens with a transformer network, and reconstructs the remaining frames based on the compressed temporal context. To minimize the reconstruction loss, the network must learn a compact representation for each image, as well as capture temporal dynamics and object permanence from temporal context. We perform evaluation on two visual reasoning benchmarks, CATER and ACRE. We observe that pretraining is essential to achieve compositional generalization for end-to-end visual reasoning. Our proposed framework outperforms traditional supervised pretraining, including image classification and explicit object detection, by large margins.
Understanding Diffusion Models: A Unified Perspective
Aug 25, 2022
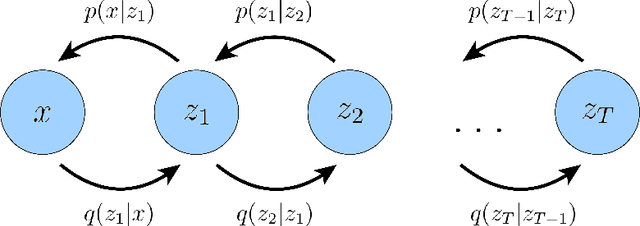


Diffusion models have shown incredible capabilities as generative models; indeed, they power the current state-of-the-art models on text-conditioned image generation such as Imagen and DALL-E 2. In this work we review, demystify, and unify the understanding of diffusion models across both variational and score-based perspectives. We first derive Variational Diffusion Models (VDM) as a special case of a Markovian Hierarchical Variational Autoencoder, where three key assumptions enable tractable computation and scalable optimization of the ELBO. We then prove that optimizing a VDM boils down to learning a neural network to predict one of three potential objectives: the original source input from any arbitrary noisification of it, the original source noise from any arbitrarily noisified input, or the score function of a noisified input at any arbitrary noise level. We then dive deeper into what it means to learn the score function, and connect the variational perspective of a diffusion model explicitly with the Score-based Generative Modeling perspective through Tweedie's Formula. Lastly, we cover how to learn a conditional distribution using diffusion models via guidance.
Data Augmentation via Structured Adversarial Perturbations
Nov 05, 2020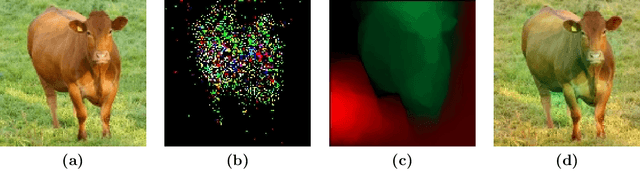
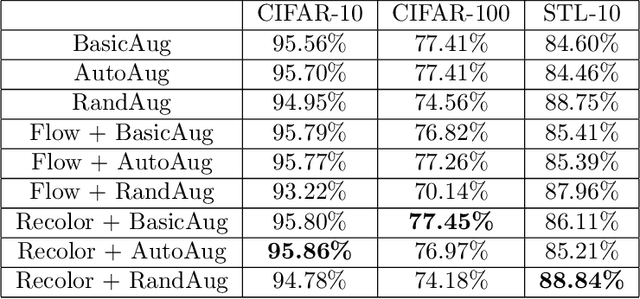

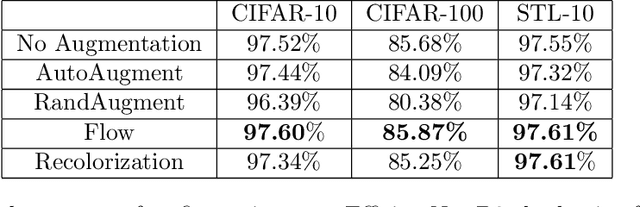
Data augmentation is a major component of many machine learning methods with state-of-the-art performance. Common augmentation strategies work by drawing random samples from a space of transformations. Unfortunately, such sampling approaches are limited in expressivity, as they are unable to scale to rich transformations that depend on numerous parameters due to the curse of dimensionality. Adversarial examples can be considered as an alternative scheme for data augmentation. By being trained on the most difficult modifications of the inputs, the resulting models are then hopefully able to handle other, presumably easier, modifications as well. The advantage of adversarial augmentation is that it replaces sampling with the use of a single, calculated perturbation that maximally increases the loss. The downside, however, is that these raw adversarial perturbations appear rather unstructured; applying them often does not produce a natural transformation, contrary to a desirable data augmentation technique. To address this, we propose a method to generate adversarial examples that maintain some desired natural structure. We first construct a subspace that only contains perturbations with the desired structure. We then project the raw adversarial gradient onto this space to select a structured transformation that would maximally increase the loss when applied. We demonstrate this approach through two types of image transformations: photometric and geometric. Furthermore, we show that training on such structured adversarial images improves generalization.
Scalable Recommender Systems through Recursive Evidence Chains
Jul 05, 2018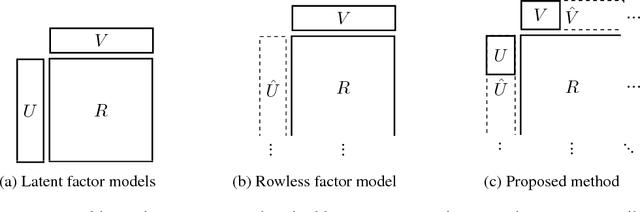
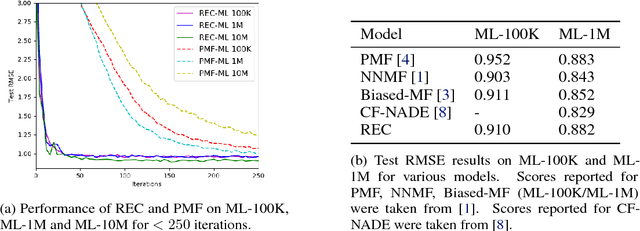
Recommender systems can be formulated as a matrix completion problem, predicting ratings from user and item parameter vectors. Optimizing these parameters by subsampling data becomes difficult as the number of users and items grows. We develop a novel approach to generate all latent variables on demand from the ratings matrix itself and a fixed pool of parameters. We estimate missing ratings using chains of evidence that link them to a small set of prototypical users and items. Our model automatically addresses the cold-start and online learning problems by combining information across both users and items. We investigate the scaling behavior of this model, and demonstrate competitive results with respect to current matrix factorization techniques in terms of accuracy and convergence speed.