 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Aware Diffusion for Policy Learning
Jul 02, 2024

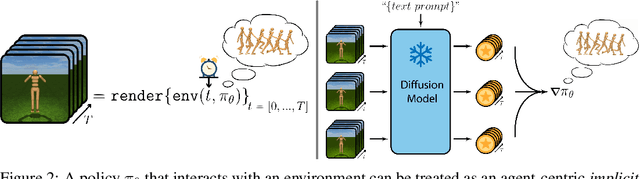
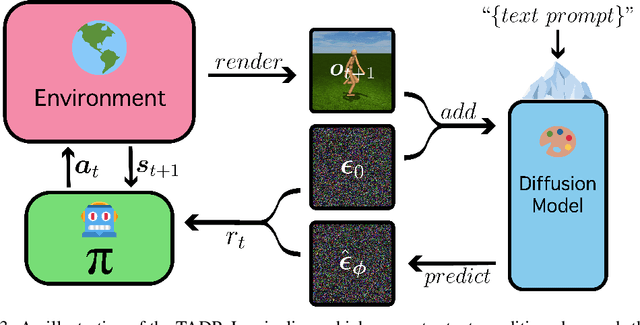
Training an agent to achieve particular goals or perform desired behaviors is often accomplished through reinforcement learning, especially in the absence of expert demonstrations. However, supporting novel goals or behaviors through reinforcement learning requires the ad-hoc design of appropriate reward functions, which quickly becomes intractable. To address this challenge, we propose Text-Aware Diffusion for Policy Learning (TADPoLe), which uses a pretrained, frozen text-conditioned diffusion model to compute dense zero-shot reward signals for text-aligned policy learning. We hypothesize that large-scale pretrained generative models encode rich priors that can supervise a policy to behave not only in a text-aligned manner, but also in alignment with a notion of naturalness summarized from internet-scale training data. In our experiments, we demonstrate that TADPoLe is able to learn policies for novel goal-achievement and continuous locomotion behaviors specified by natural language, in both Humanoid and Dog environments. The behaviors are learned zero-shot without ground-truth rewards or expert demonstrations, and are qualitatively more natural according to human evaluation. We further show that TADPoLe performs competitively when applied to robotic manipulation tasks in the Meta-World environment.