 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Adapting Improvement Loops for Robotic Learning
Jun 07, 2025



Video generative models trained on expert demonstrations have been utilized as performant text-conditioned visual planners for solving robotic tasks. However, generalization to unseen tasks remains a challenge. Whereas improved generalization may be facilitated by leveraging learned prior knowledge from additional pre-collected offline data sources, such as web-scale video datasets, in the era of experience we aim to design agents that can continuously improve in an online manner from self-collected behaviors. In this work we thus propose the Self-Adapting Improvement Loop (SAIL), where an in-domain video model iteratively updates itself on self-produced trajectories, collected through adaptation with an internet-scale pretrained video model, and steadily improves its performance for a specified task of interest. We apply SAIL to a diverse suite of MetaWorld tasks, as well as two manipulation tasks on a real robot arm, and find that performance improvements continuously emerge over multiple iterations for novel tasks initially unseen during original in-domain video model training. Furthermore, we discover that SAIL is surprisingly robust regarding if and how the self-collected experience is filtered, and the quality of the initial in-domain demonstrations. Through adaptation with summarized internet-scale data, and learning through online experience, we thus demonstrate a way to iteratively bootstrap a high-performance video model for solving novel robotic tasks through self-improvement.
Solving New Tasks by Adapting Internet Video Knowledge
Apr 21, 2025Video generative models demonstrate great promise in robotics by serving as visual planners or as policy supervisors. When pretrained on internet-scale data, such video models intimately understand alignment with natural language, and can thus facilitate generalization to novel downstream behavior through text-conditioning. However, they may not be sensitive to the specificities of the particular environment the agent inhabits. On the other hand, training video models on in-domain examples of robotic behavior naturally encodes environment-specific intricacies, but the scale of available demonstrations may not be sufficient to support generalization to unseen tasks via natural language specification. In this work, we investigate different adaptation techniques that integrate in-domain information with large-scale pretrained video models, and explore the extent to which they enable novel text-conditioned generalization for robotic tasks, while also considering their independent data and resource considerations. We successfully demonstrate across robotic environments that adapting powerful video models with small scales of example data can successfully facilitate generalization to novel behaviors. In particular, we present a novel adaptation strategy, termed Inverse Probabilistic Adaptation, that not only consistently achieves strong generalization performance across robotic tasks and settings, but also exhibits robustness to the quality of adaptation data, successfully solving novel tasks even when only suboptimal in-domain demonstrations are available.
Text-Aware Diffusion for Policy Learning
Jul 02, 2024

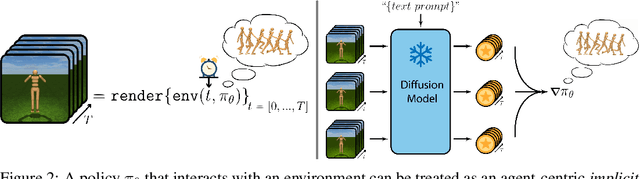
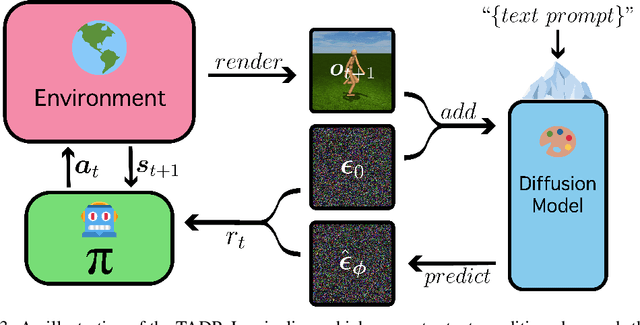
Training an agent to achieve particular goals or perform desired behaviors is often accomplished through reinforcement learning, especially in the absence of expert demonstrations. However, supporting novel goals or behaviors through reinforcement learning requires the ad-hoc design of appropriate reward functions, which quickly becomes intractable. To address this challenge, we propose Text-Aware Diffusion for Policy Learning (TADPoLe), which uses a pretrained, frozen text-conditioned diffusion model to compute dense zero-shot reward signals for text-aligned policy learning. We hypothesize that large-scale pretrained generative models encode rich priors that can supervise a policy to behave not only in a text-aligned manner, but also in alignment with a notion of naturalness summarized from internet-scale training data. In our experiments, we demonstrate that TADPoLe is able to learn policies for novel goal-achievement and continuous locomotion behaviors specified by natural language, in both Humanoid and Dog environments. The behaviors are learned zero-shot without ground-truth rewards or expert demonstrations, and are qualitatively more natural according to human evaluation. We further show that TADPoLe performs competitively when applied to robotic manipulation tasks in the Meta-World environment.
Emergence of Abstract State Representations in Embodied Sequence Modeling
Nov 07, 2023Decision making via sequence modeling aims to mimic the success of language models, where actions taken by an embodied agent are modeled as tokens to predict. Despite their promising performance, it remains unclear if embodied sequence modeling leads to the emergence of internal representations that represent the environmental state information. A model that lacks abstract state representations would be liable to make decisions based on surface statistics which fail to generalize. We take the BabyAI environment, a grid world in which language-conditioned navigation tasks are performed, and build a sequence modeling Transformer, which takes a language instruction, a sequence of actions, and environmental observations as its inputs. In order to investigate the emergence of abstract state representations, we design a "blindfolded" navigation task, where only the initial environmental layout, the language instruction, and the action sequence to complete the task are available for training. Our probing results show that intermediate environmental layouts can be reasonably reconstructed from the internal activations of a trained model, and that language instructions play a role in the reconstruction accuracy. Our results suggest that many key features of state representations can emerge via embodied sequence modeling, supporting an optimistic outlook for applications of sequence modeling objectives to more complex embodied decision-making domains.
Goal-Conditioned Predictive Coding as an Implicit Planner for Offline Reinforcement Learning
Jul 07, 2023Recent work has demonstrated the effectiveness of formulating decision making as a supervised learning problem on offline-collected trajectories. However, the benefits of performing sequence modeling on trajectory data is not yet clear. In this work we investigate if sequence modeling has the capability to condense trajectories into useful representations that can contribute to policy learning. To achieve this, we adopt a two-stage framework that first summarizes trajectories with sequence modeling techniques, and then employs these representations to learn a policy along with a desired goal. This design allows many existing supervised offline RL methods to be considered as specific instances of our framework. Within this framework, we introduce Goal-Conditioned Predicitve Coding (GCPC), an approach that brings powerful trajectory representations and leads to performant policies. We conduct extensive empirical evaluations on AntMaze, FrankaKitchen and Locomotion environments, and observe that sequence modeling has a significant impact on some decision making tasks. In addition, we demonstrate that GCPC learns a goal-conditioned latent representation about the future, which serves as an "implicit planner", and enables competitive performance on all three benchmarks.