 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards A Unified Neural Architecture for Visual Recognition and Reasoning
Paper and Code
Nov 10, 2023
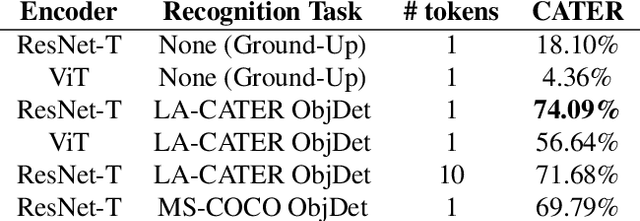


Recognition and reasoning are two pillars of visual understanding. However, these tasks have an imbalance in focus; whereas recent advances in neural networks have shown strong empirical performance in visual recognition, there has been comparably much less success in solving visual reasoning. Intuitively, unifying these two tasks under a singular framework is desirable, as they are mutually dependent and beneficial. Motivated by the recent success of multi-task transformers for visual recognition and language understanding, we propose a unified neural architecture for visual recognition and reasoning with a generic interface (e.g., tokens) for both. Our framework enables the principled investigation of how different visual recognition tasks, datasets, and inductive biases can help enable spatiotemporal reasoning capabilities. Noticeably, we find that object detection, which requires spatial localization of individual objects, is the most beneficial recognition task for reasoning. We further demonstrate via probing that implicit object-centric representations emerge automatically inside our framework. Intriguingly, we discover that certain architectural choices such as the backbone model of the visual encoder have a significant impact on visual reasoning, but little on object detection. Given the results of our experiments, we believe that visual reasoning should be considered as a first-class citizen alongside visual recognition, as they are strongly correlated but benefit from potentially different design choices.